
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
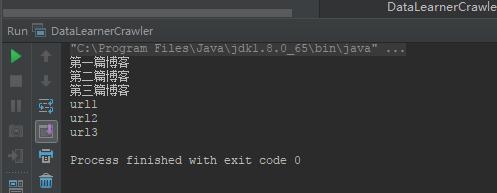
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。

使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
在使用HttpClient作为客户端请求数据的时候,我们常常需要以一个用户的身份多次请求一个网站内的多种资源。例如,我一次登录后,后面希望以这个身份继续访问不用重新登录。这里就可以使用cookie了。
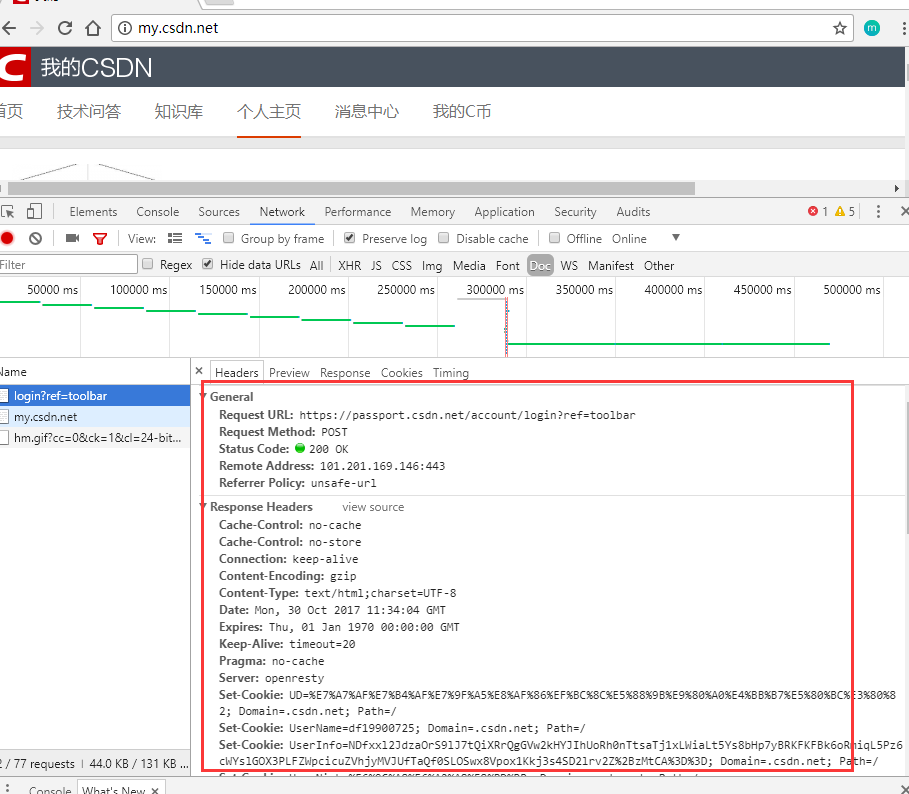
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录

今日推荐
ChatGPT官方代码解释器插件Code-Interpreter大揭秘:Code-Interpreter背后都有什么(执行环境、硬件资源、包含的Python库等)?
Generative Adversarial Networks 生成对抗网络的简单理解
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!
2023年4月中旬值得关注的几个AI模型:Dollly2、MiniGPT-4、LLaVA、DINOv2
重磅!苹果官方发布大模型框架:一个可以充分利用苹果统一内存的新的大模型框架MLX,你的MacBook可以一键运行LLaMA了
Python3.10版本的结构模式匹配(structural pattern matching)简介
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!