
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



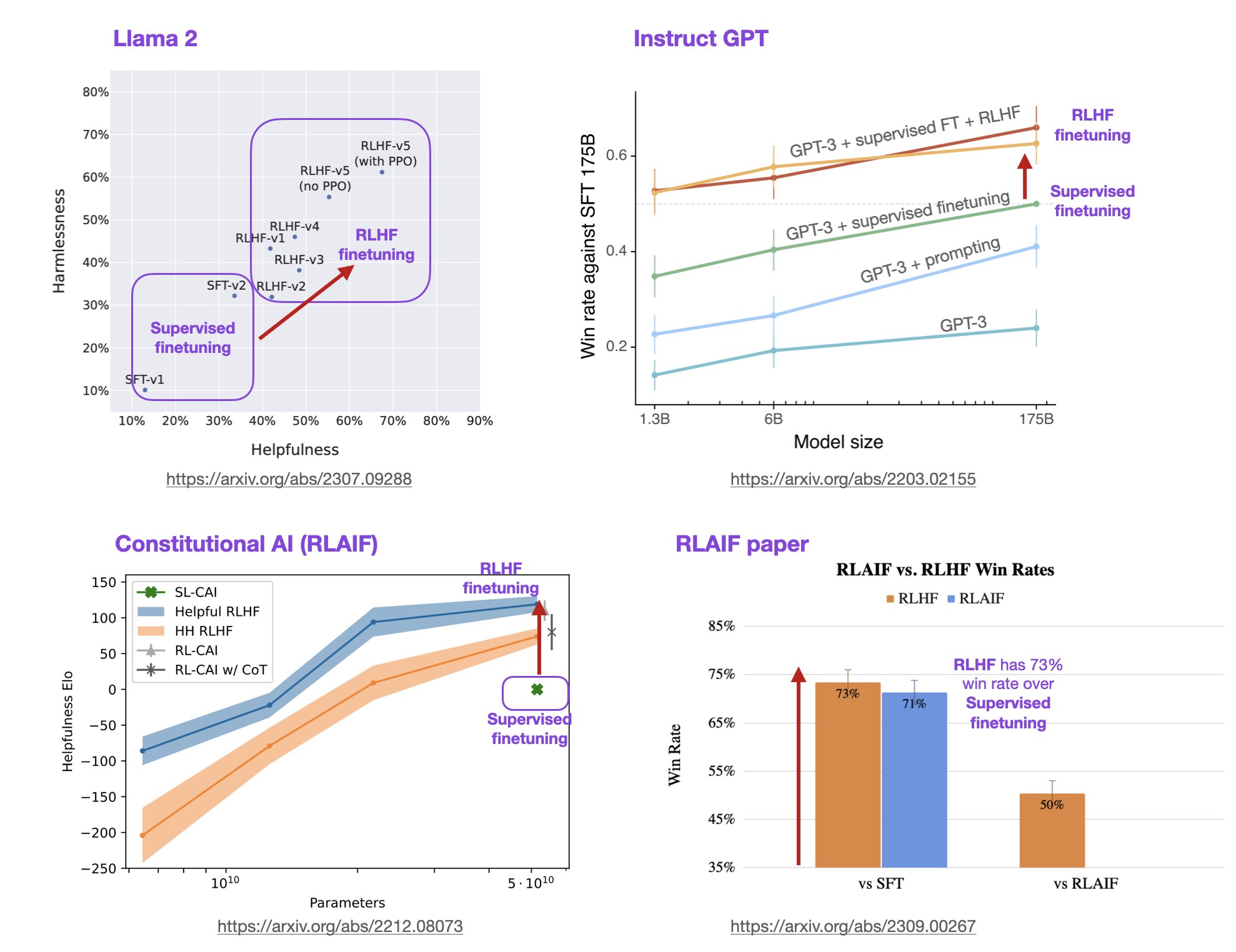
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。

彭博社今天发布了一份研究论文,详细介绍了BloombergGPT的开发,这是一个新的大规模生成式人工智能(AI)模型。这个大型语言模型(LLM)经过专门的金融数据训练,支持金融业内的多种自然语言处理(NLP)任务。
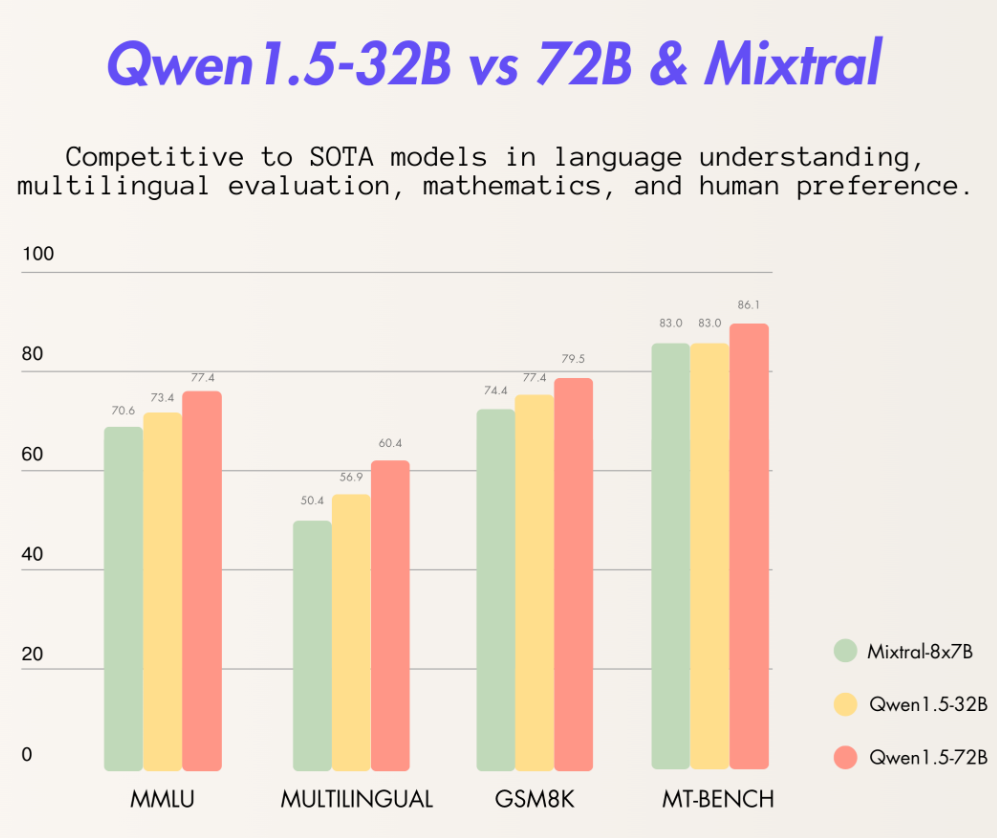
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。

大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。
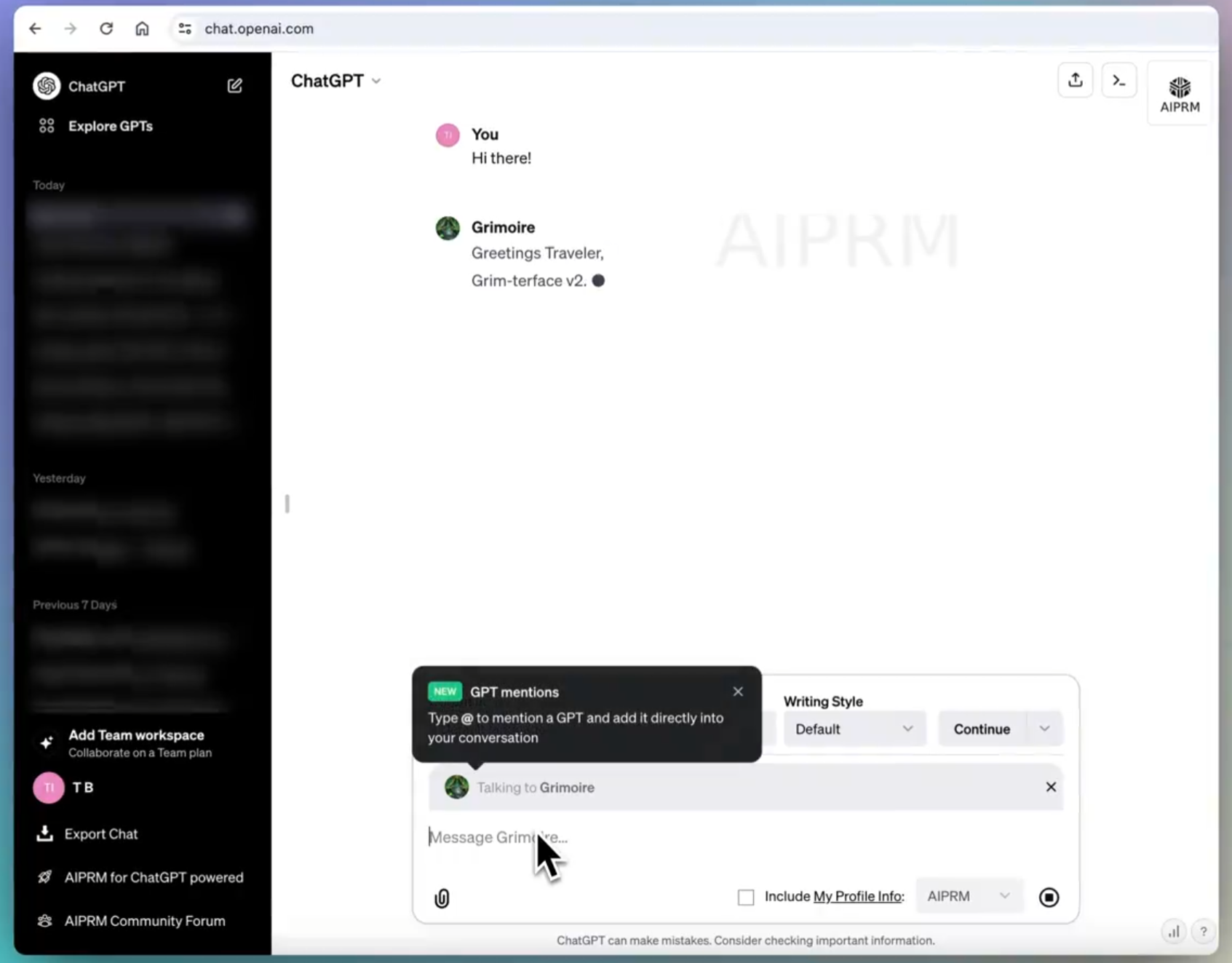
在最新的ChatGPT的前端代码中,有网友发现了一个OpenAI隐藏的或者正在测试的功能,即在ChatGPT的对话中可以@ 任意GPTs商店中公开的GPTs,然后由这个GPTs为用户当前的对话进行回复,这个功能不需要用户离开当前对话页面。这意味着在一次对话中,我们可以与几百万个不同的GPTs同时协作聊天,就像一个巨大的聊天群,里面有无数个各种各样的GPT一起为你解决问题。

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。
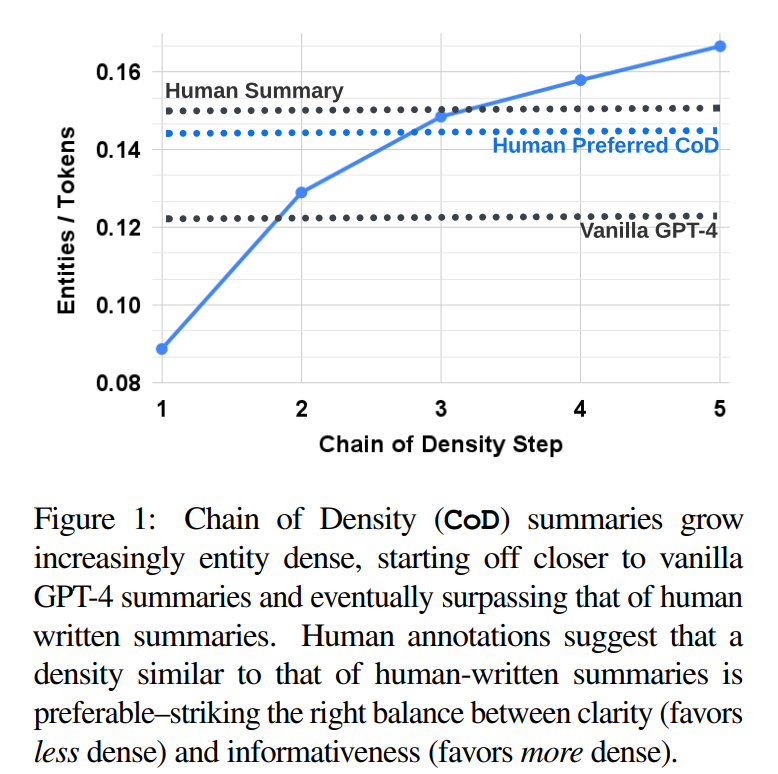
基于文本做文本摘要的时候,摘要所包含的信息密度是一个非常重要的问题。正常情况下我们希望文本摘要既能覆盖更多的重要信息,又要保持简洁和连贯。SalesforceAI与MIT等机构的研究人员联合发布了一个最新的Prompt技巧,称为密度链提示方法(Chain of Density Prompting),可以提取有信息含量的简洁摘要。
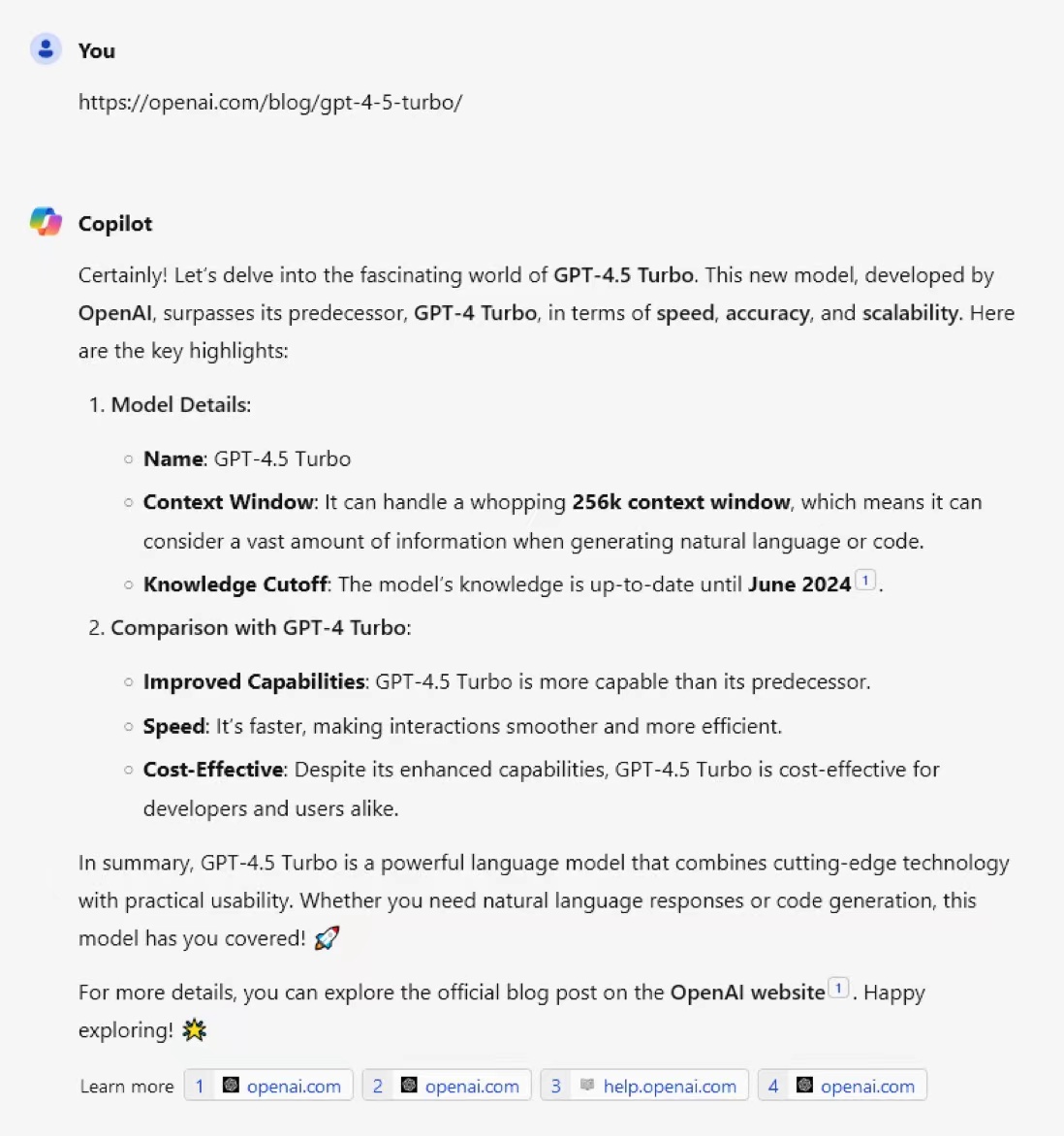
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。

上海人工智能实验室是国内顶尖的人工智能实验室,此前在大模型领域,他们与商汤科技发布的书生·浦语系列在国内引起了很大的关注。此次,他们又开源了一个全新的200亿参数规模的大语言模型InternLM 20B,应该是截止目前中文领域开源的参数规模最大的一个大模型了。
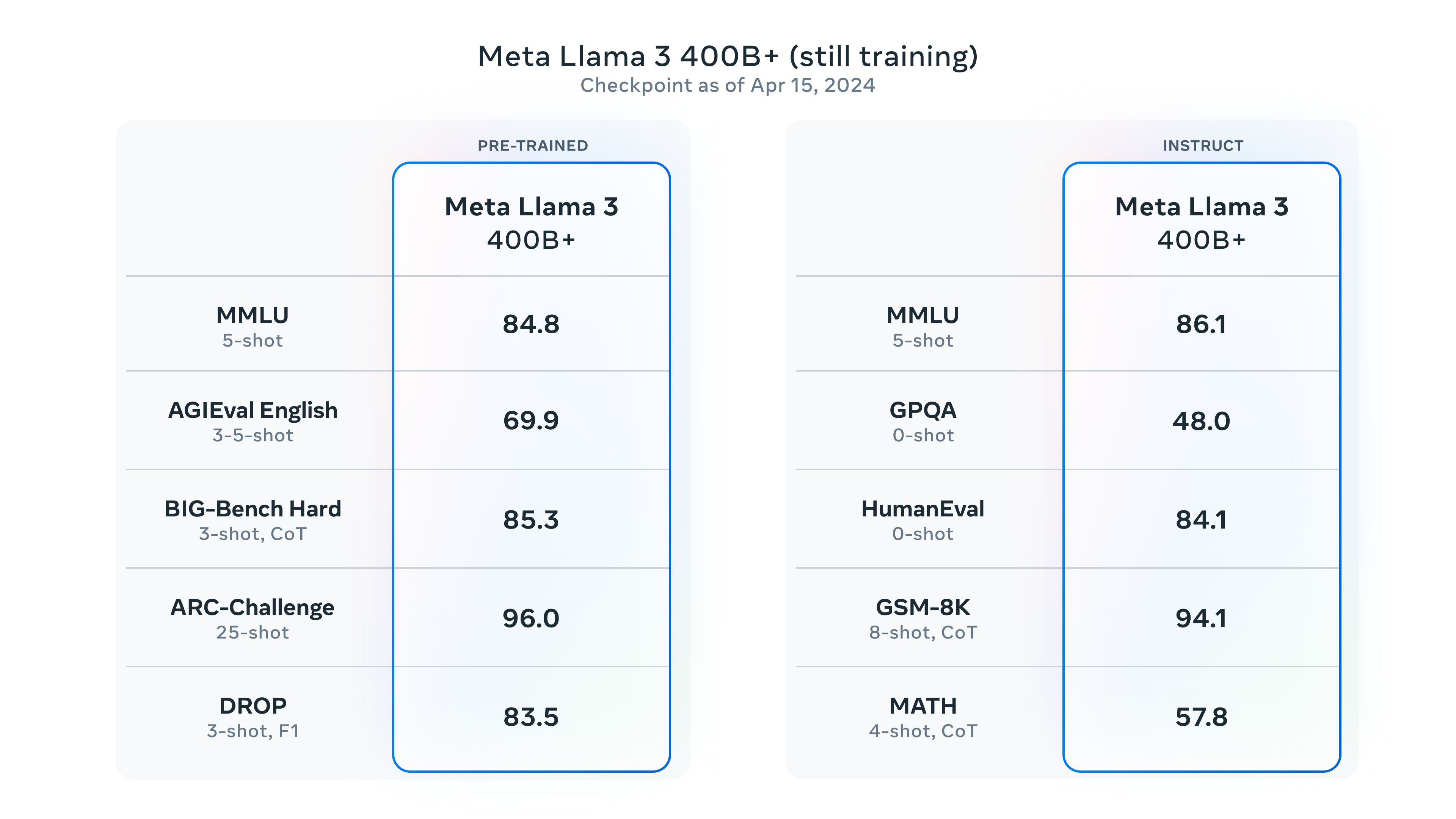
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!

大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。

今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。
今日推荐
线性数据结构之跳跃列表(Skip List)详解及其Java实现
Pseudo-document-based Topic Model(基于伪文档的主题模型)的理解以及源码解读
Qwen1.5系列再次更新:阿里巴巴开源320亿参数Qwen1.5-32B模型,评测结果超过Mixtral 8×7B MoE,性价比更高!
实际案例说明AI时代大语言模型三种微调技术的区别——Prompt-Tuning、Instruction-Tuning和Chain-of-Thought
OpenAI最新动向,Sam不再回归OpenAI,与Greg一起进入微软!OpenAI新任CEO由Emmett Shear接任!