
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
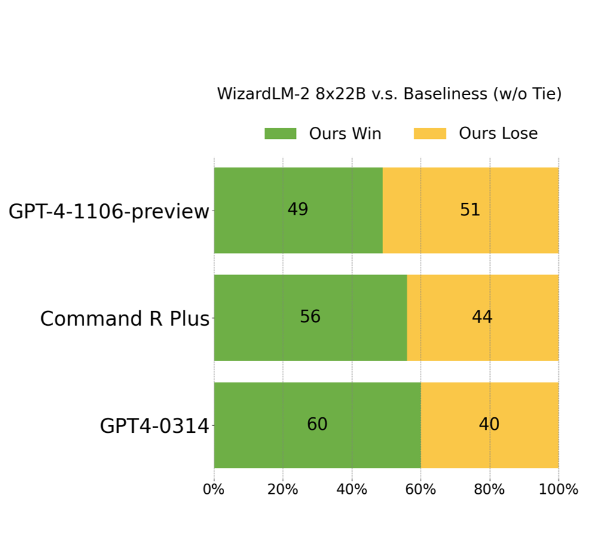
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
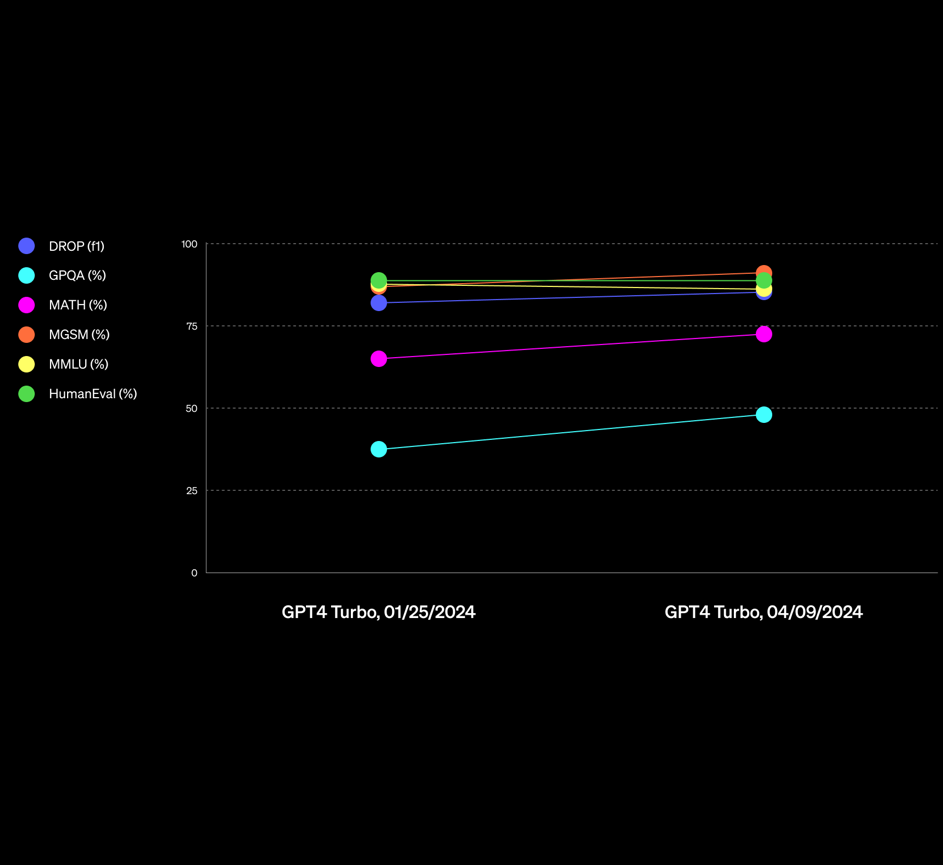
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!
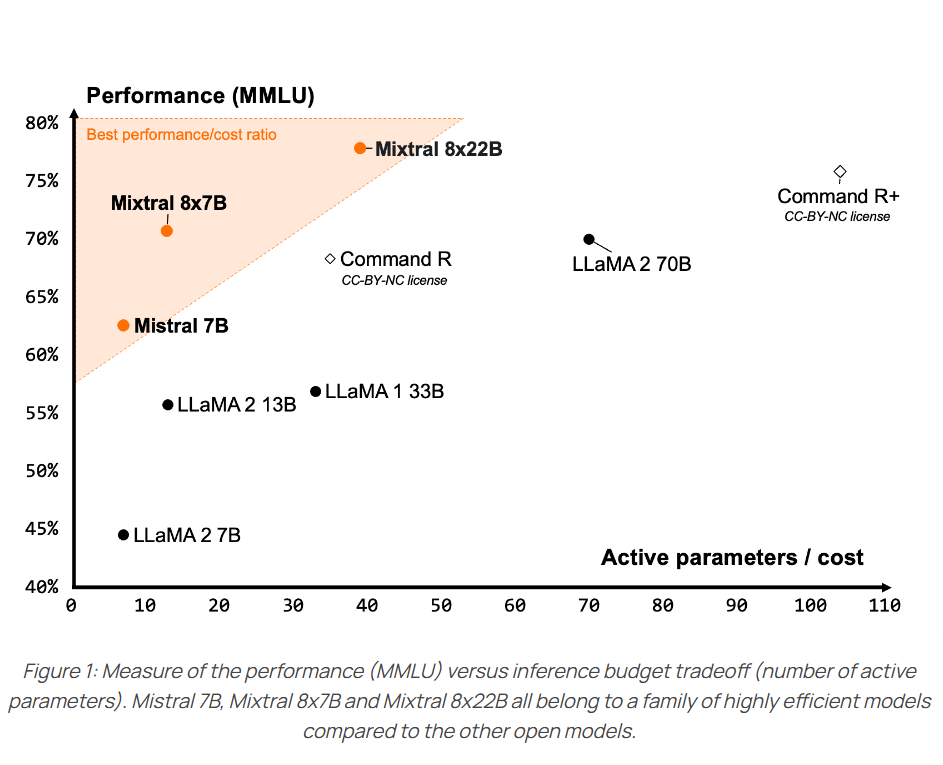
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。
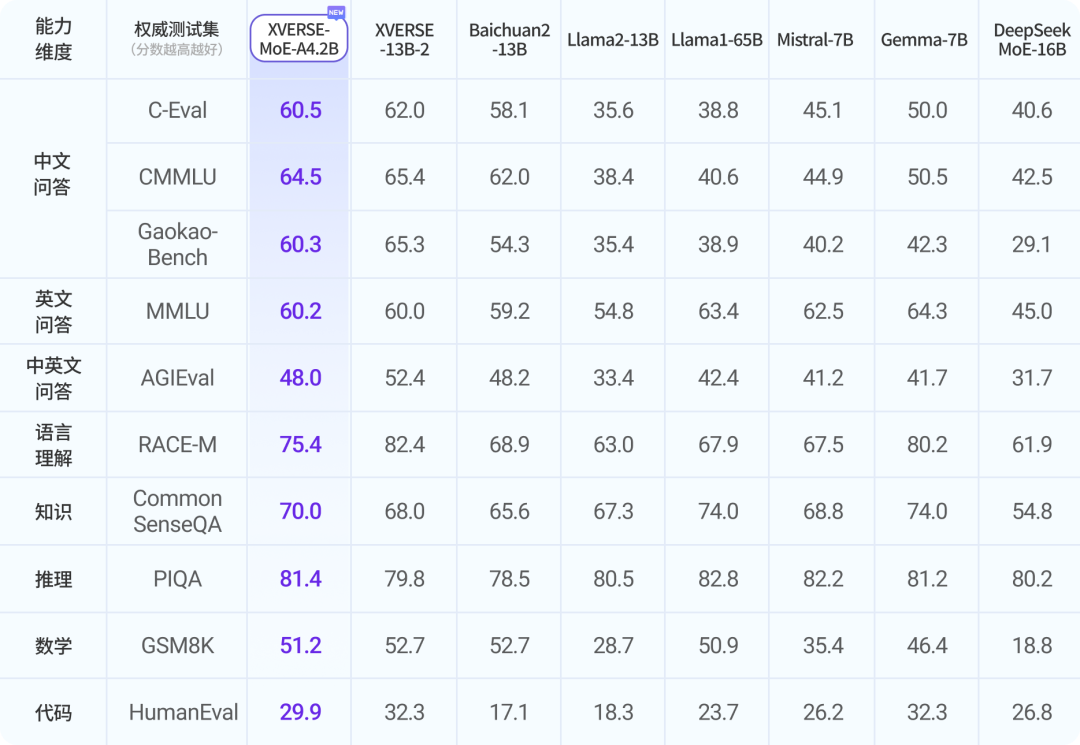
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
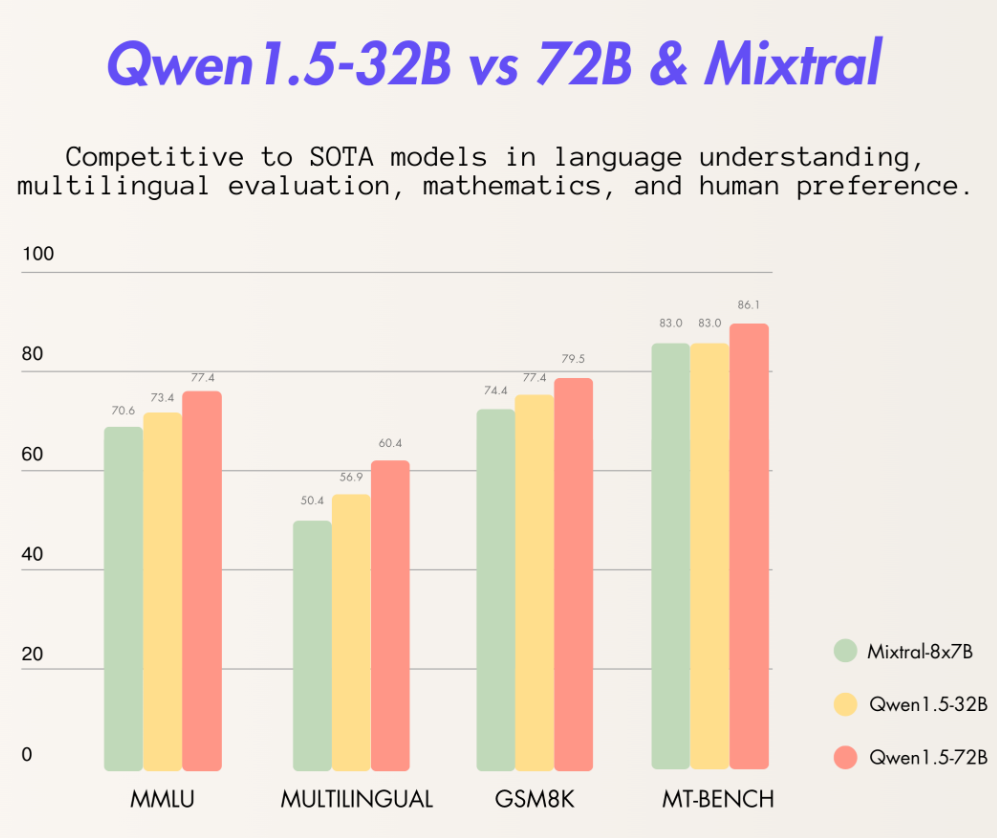
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

Mistral-7B是由MistralAI开源的一个73亿参数规模的大语言模型,最早在2023年9月底开源。因为其良好的性能和友好的开源协议被很多人使用。今天,这个模型升级到来v0.2版本Mistral-7B-v0.2。基于Mistral-7B-v0.2进行指令微调的模型 Mistral-7B-Instruct-v0.2在2023年11月11日公布,而这个基座模型则是在2023年3月24日开源。

NVIDIA在2024年GPU技术大会(NVIDIA GPU Technology Conference,GTC)发布了全新的算力芯片和服务,即基于最新的Blackwell架构的算力芯片B200和GB200服务器。但是,大多数人对于NVIDIA芯片的升级只有数字的变化,本文将针对NVIDIA的GPU算力芯片做简单的介绍,并说明NVIDIA B200以及GB200的升级的地方。

在近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)在代码生成和编辑领域的应用越来越广泛,成为软件开发中不可或缺的助手。今天,我想向大家介绍一个由BigCode项目与Software Heritage合作开发的下一代代码大型语言模型——StarCoder 2。
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。
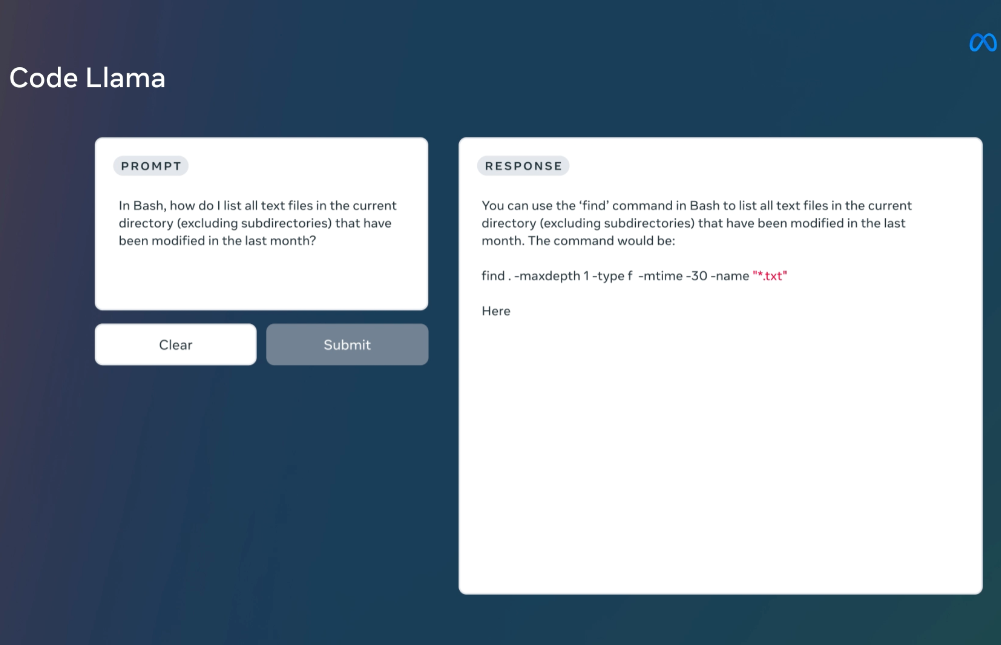
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst
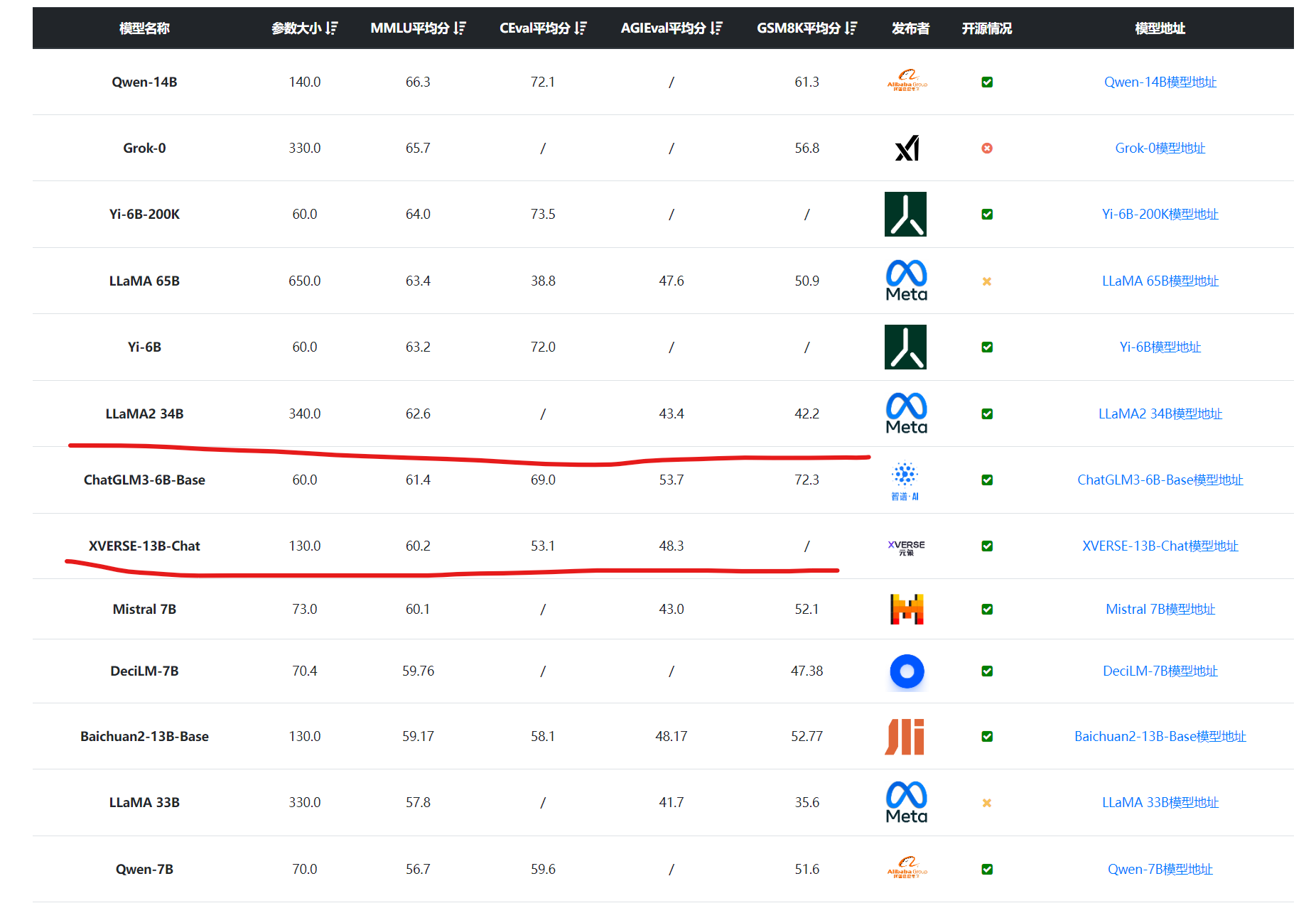
深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。

2022年11月底,ChatGPT横空出世,全球都被这样一个“好像”有智能的产品吸引力。随后,工业界、科研机构开始疯狂投入大模型。在2023年,这个被称为大模型元年的年份,有很多令人瞩目的AI产品与模型发布。2023年,DataLearner收集了大量的大模型,并发布了很多大模型相关的技术博客,在即将结束的2023年,我们以这个『2023年最令人瞩目的AI产品』结束本年的技术分享。
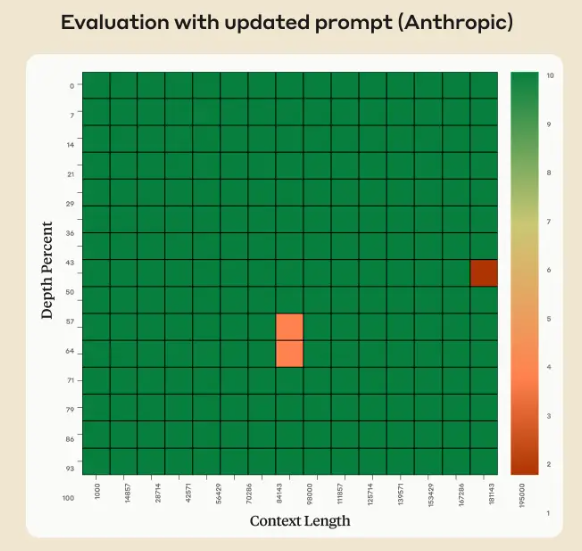
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。