GPT-4 - Generative Pre-trained Transformer 4
模型详细情况和参数
GPT-4
- 模型全称
- Generative Pre-trained Transformer 4
- 模型简称
- GPT-4
- 模型类型
- 基础大模型
- 发布日期
- 2023-03-14
- 预训练文件大小
- 未知
- 是否支持中文(中文优化)
- 是
- 最高支持的上下文长度
- 128K
- 模型参数数量(亿)
- 1750.0
- 模型代码开源协议
- 不开源
- 预训练结果开源商用情况
- 不开源 - 不开源
- 模型GitHub链接
- 暂无
- 模型HuggingFace链接
- 暂无
- 在线演示地址
- 暂无
- 官方博客论文
- GPT-4 Technical Report
- 基础模型
-

GPT
查看详情 - 发布机构
- 评测结果
-
评测名称 评测能力方向 评测结果
Generative Pre-trained Transformer 4 简介
2023年3月14日(咱们北京时间应该是3月15日凌晨了),OpenAI发布了GPT-4模型。这是GPT系列最新的模型,是一个多模他的模型。
一、基本能力
与之前系列最大的不同,GPT-4是一个多模态模型,可以接受图像与文本的输入,输出文本内容。
GPT-4在很多专业和学术基准上表现与人类差不多,比如通过模拟的律师考试,得分在应试者前10%左右(GPT-3.5在后10%,也就是说提升了很多)!但是在现实世界中的很多场景表现还不如人类。
基于之前模型训练的经验,GPT-4的训练是基于重建的深度学习堆栈进行的,因此训练过程可以稳定预测!
二、GPT-4的测试结果
与GPT-3.5相比,他们的区别可能不是那么明显,但是当任务足够复杂时候,它们的区别就明显了,GPT-4更加可靠、稳定且有创造性!
下图是GPT4、GPT-4(不带vision)和GPT-3.5的各种考试结果对比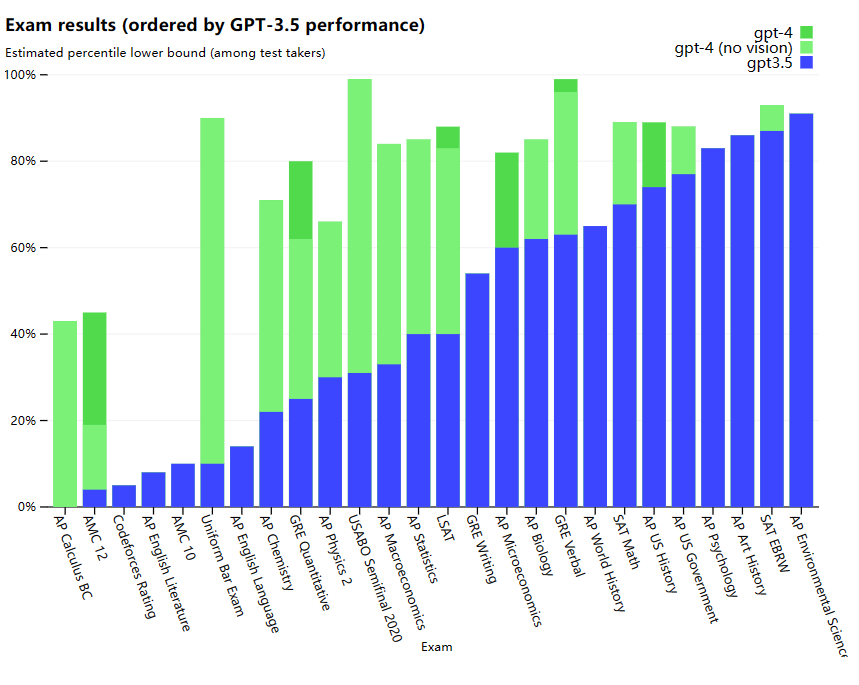
可以看到,GPT4效果更好。
传统的机器学习任务中,GPT-4表现更好。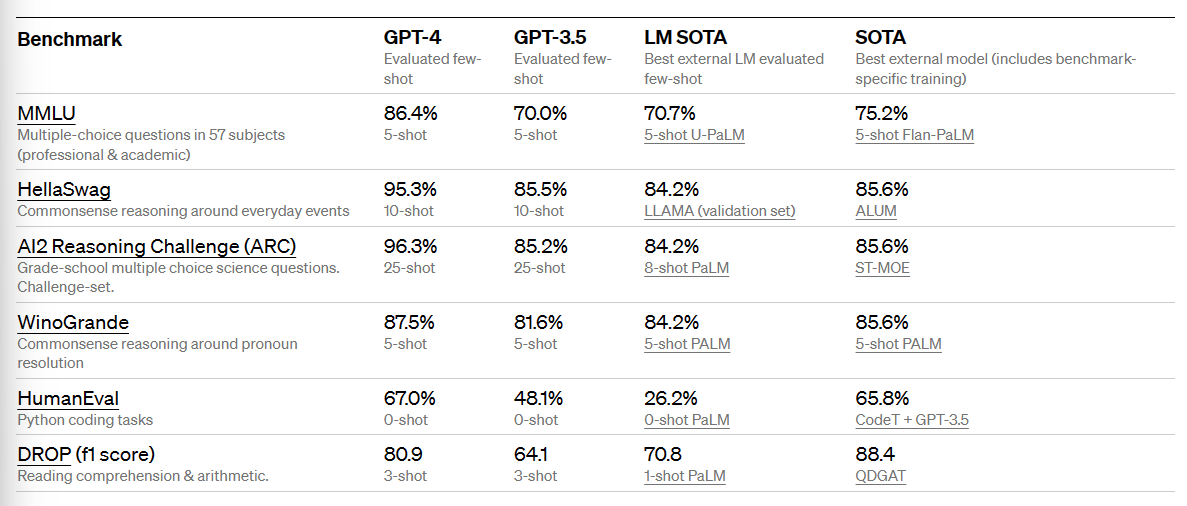
这里可以看到,在专业学术问答(MMLU)、日常推理(HellaSwag)、多项选择考试(AI2 Reasoning Challenge)等方面,GPT-4比GPT-3.5高出了一大截。在AI不太擅长的Python编程、阅读理解方面也有较大提高。
三、多语言特性
GPT-4的多语言能力也有较大提升,在MMLU的多选测试中,GPT-3.5的英文题目准确率70.1%,而GPT-4是85.5%。但是在其他语言上,GPT-4性能也很强(为啥没有中文???!!!)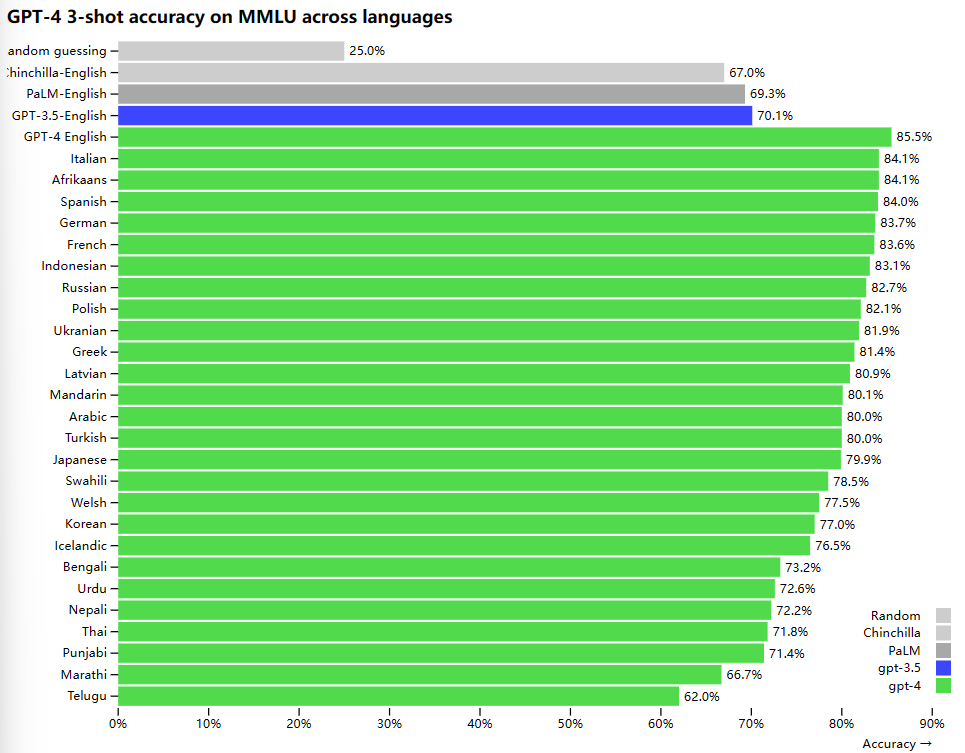
即便在很多非英语的结果上,GPT-4的表现也比GPT-3.5好很多。
四、GPT-4的训练过程
和以前的GPT模型一样,GPT-4基础模型的训练是为了预测文档中的下一个词,并使用公开的数据(如互联网数据)以及授权的数据进行训练。这些数据是一个网络规模的语料库,包括对数学问题的正确和错误的解决方案,薄弱和强大的推理,自相矛盾和一致的声明,并代表了大量的意识形态和想法。
因此,当被提示有问题时,基础模型可以做出各种各样的反应,可能与用户的意图相去甚远。为了使其与用户的意图保持一致,OpenAI使用人类反馈的强化学习(RLHF)对模型的行为进行了微调。
请注意,模型的能力似乎主要来自于预训练过程—RLHF并不能提高考试成绩(如果不主动努力,它实际上会降低考试成绩)。但是对模型的引导来自于训练后的过程—基础模型需要及时的工程,甚至知道它应该回答问题。
五、GPT-4的训练过程可预测
GPT-4项目的一大重点是建立一个可预测扩展的深度学习栈。主要原因是,对于像GPT-4这样的大型训练运行,进行广泛的特定模型调整是不可行的。所以OpenAI开发了基础设施和优化,在多种规模下都有非常可预测的行为。为了验证这种可扩展性,他们提前准确地预测了GPT-4在我们内部代码库(不属于训练集)上的最终损失,方法是通过使用相同的方法训练的模型进行推断,但使用的计算量要少10000倍。
六、GPT-4的开放及其他信息
OpenAI开源了一个OpenAI Evals的软件框架,它是用来创建评估GPT-4基准的框架,它可以用来引导GPT-4的一些回答,同时逐个样本检查其性能。他们使用Evals来指导模型的开发(包括识别缺点和防止倒退),我们可以应用它来跟踪不同模型版本(现在将定期推出)和不断发展的产品集成的性能。例如,Stripe已经使用Evals来补充他们的人工评估,以衡量他们的GPT驱动的文档工具的准确性。该框架即将开源!
ChatGPT Plus用户将很快可以有权限使用GPT-4,不过OpenAI表示,可能会推出一个新的订阅级别,以满足更高的GPT-4使用量(估计得加钱了!)。
GPT-4的API现在就可以加入申请,一旦你有了访问权,你就可以向gpt-4模型提出纯文本请求(图像输入仍处于有限的alpha阶段),随着时间的推移,OpenAI会自动更新为我们推荐的稳定模型(你可以通过调用gpt-4-0314来锁定当前版本,它将支持到6月14日)。定价为每1k tokens币0.03美元,每1k补全 tokens约0.06美元。默认的速率限制是每分钟40k tokens和每分钟200个请求。
GPT-4的上下文长度为8,192个tokens。并且还提供对32,768个上下文(约50页文本)版本的有限访问,gpt-4-32k,它也将随着时间的推移自动更新(当前版本gpt-4-32k-0314,也支持到6月14日)。价格是每1K prompt的tokens0.06美元,每1K completion tokens是0.12美元。
官方GPT-4的论文: https://cdn.openai.com/papers/gpt-4.pdf
系统card: https://cdn.openai.com/papers/gpt-4-system-card.pdf
欢迎大家关注DataLearner官方微信,接受最新的AI模型和技术推送
