Mixtral-8×7B-MoE - Mixtral-8×7B-MoE-Instruct-v0.1
模型详细情况和参数
Mixtral-8×7B-MoE
- 模型全称
- Mixtral-8×7B-MoE-Instruct-v0.1
- 模型简称
- Mixtral-8×7B-MoE
- 模型类型
- 聊天大模型
- 发布日期
- 2023-12-08
- 预训练文件大小
- 86.99GB
- 是否支持中文(中文优化)
- 否
- 最高支持的上下文长度
- 32K
- 模型参数数量(亿)
- 450.0
- 模型代码开源协议
- Apache 2.0
- 预训练结果开源商用情况
- Apache 2.0 - 免费商用授权
- 模型GitHub链接
- 暂无
- 模型HuggingFace链接
- https://huggingface.co/mistralai/Mixtral-8x7B-v0.1
- 在线演示地址
- 暂无
- DataLearnerAI的模型介绍
- MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
- 基础模型
- 无基础模型
- 发布机构
Mixtral-8×7B-MoE-Instruct-v0.1 简介
12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)(详情参考DataLearnerAI此前的介绍:MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
Mistral-7B×8-MoE的特点
根据官方的介绍,Mistral-7B×8-MoE是一个高质量稀疏型的专家混合模型。是8个70亿参数规模大模型的混合。它的主要特点如下:
- 它可以非常优雅地处理32K上下文数据
- 除了英语外,在法语、德语、意大利语和西班牙语表现也很好
- 在代码能力上表现很强
- 指令微调后MT-Bench的得分8.3分(GPT-3.5是8.32、LLaMA2 70B是6.86)
在MoE模型中,有两个关键组件:
- 专家(Experts):这些是网络中的小型子网络,每个专家通常专注于处理一种特定类型的数据或任务。专家的设计可以是多种形式,如完全连接的网络、卷积网络等。
- 门控机制(Gating Mechanism):这是一个智能路由系统,负责决定哪些专家应该被激活来处理当前的输入数据。门控机制基于输入数据的特性,动态地将数据分配给不同的专家。
官方介绍,这个模型是基于网络数据预训练的,其中,专家网络和门控路由是同时训练的。
Mistral-7B×8-MoE评估效果
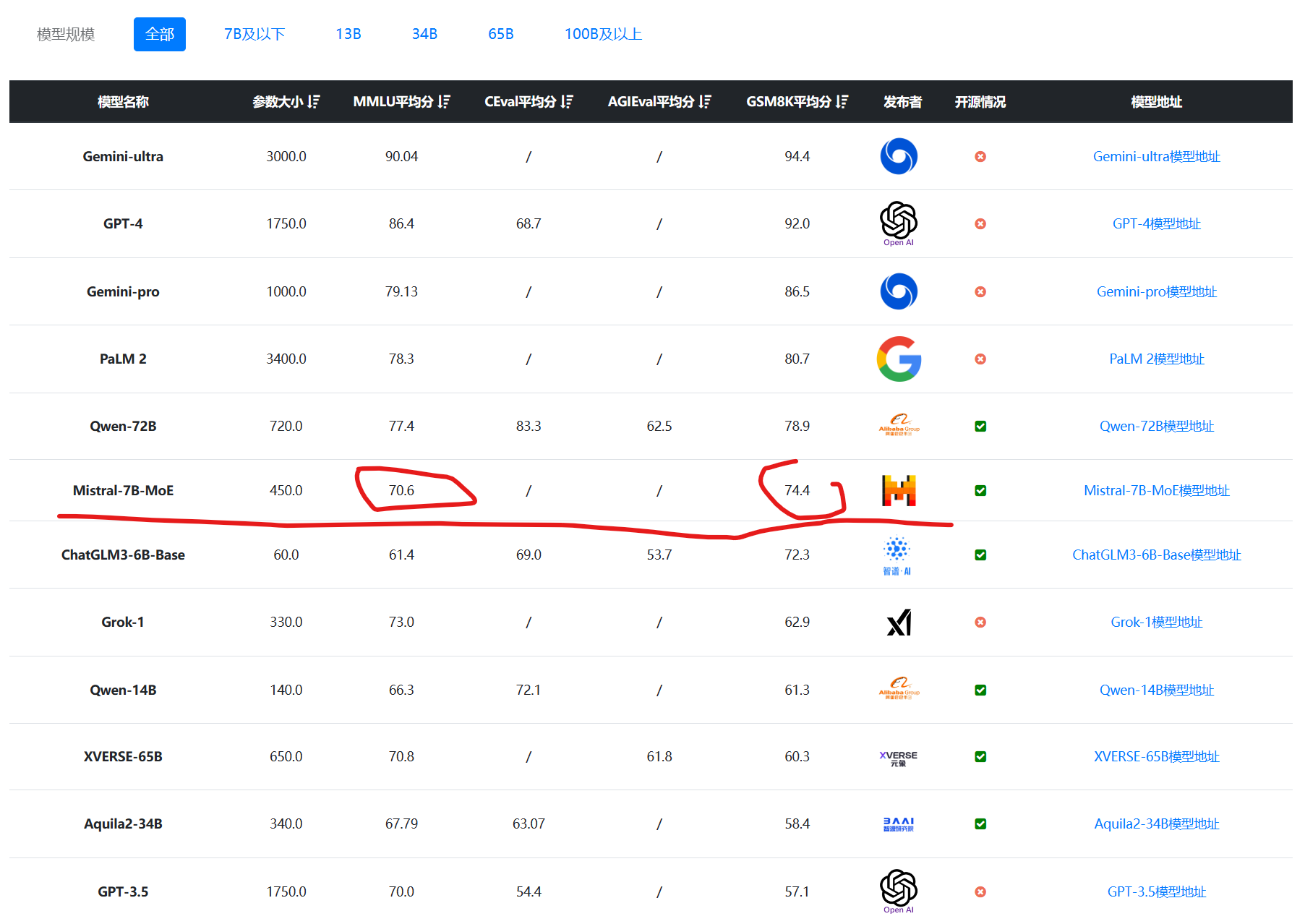
此次,官方详细公布了Mistral-7B×8-MoE在各个评测数据集上的评测效果。结果如下:
| 评测数据集 | LLAMA 270B | GPT-3.5 | Mixtral 8x7B |
|---|---|---|---|
| MMLU (MCQ in 57 subjects) | 69.9% | 70.0% | 70.6% |
| HellaSwag (10-shot) | 87.1% | 85.5% | 86.7% |
| ARC Challenge (25-shot) | 85.1% | 85.2% | 85.8% |
| WinoGrande (5-shot) | 83.2% | 81.6% | 81.2% |
| MBPP (pass@1) | 49.8% | 52.2% | 60.7% |
| GSM-8K (5-shot) | 53.6% | 57.1% | 58.4% |
| MT Bench (for Instruct Models) | 6.86 | 8.32 | 8.30 |
从这个角度看,Mistral-7B×8-MoE与GPT-3.5、LLaMA2-70B是一个水平的。
Mistral-7B×8-MoE和LLaMA系列更加详细的对比:
| 模型 | 参数 | MMLU (MCQ in 57 subjects) | HellaSwag (10-shot) | ARC Challenge (25-shot) | WinoGrande (5-shot) | MBPP (pass@1) | GSM-8K (5-shot) | MT Bench (for Instruct Models) | |
|---|---|---|---|---|---|---|---|---|---|
| LLAMA 2 7B | 7B | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 17.5% | 16.0% |
| LLAMA 2 13B | 13B | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 16.7% | 34.3% |
| LLAMA 1 33B | 33B | 56.8% | 83.7% | 76.2% | 82.2% | 79.6% | 54.4% | 24.1% | 44.1% |
| LLAMA 270B | 70B | 69.9% | 85.4% | 80.4% | 82.6% | 79.9% | 56.5% | 25.4% | 69.6% |
| Mistral 7B | 7B | 62.5% | 81.0% | 74.2% | 82.2% | 80.5% | 54.9% | 23.2% | 50.0% |
| Mixtral 8x7B | 12B | 70.6% | 84.4% | 77.2% | 83.6% | 83.1% | 59.7% | 30.6% | 74.4% |
可以看到,Mistral-7B×8-MoE模型在各方面的指标都很不错,几乎与LLaMA2-70B在一个水平,但是由于每次只有120亿参数在工作,这意味着它的成本要远低于LLaMA2 70B,官方的说法是推理速度比LLaMA2 70B快6倍!
下图是DataLearnerAI大模型评测排行结果:
数据来源: https://www.datalearner.com/ai-models/llm-evaluation
而代码生成能力的结果,则和CodeLLaMA2-34B在一个水平,要知道,这是一个基座大模型,不是编程大模型,这个结果非常不错,具体参考DataLearnerAI的大模型编程能力排行:https://www.datalearner.com/ai-models/llm-coding-evaluation
Mistral-7B×8-MoE的多语言能力
除了前面的常规评测外,Mistral-7B×8-MoE另一个吸引人的特点是它多语言支持效果很好。目前在法语、西班牙语、德语、意大利语上的表现都非常亮眼。
不愧是法国企业,在支持欧洲语言上非常棒。从图中也可以看到,Mistral-7B×8-MoE在法语、德语、西班牙语和意大利语表现比LLaMA2-70B系列明显更优!
混合专家技术为Mistral-7B×8-MoE带来的价值
Mistral-7B×8-MoE模型在多个评测基准上都超过了LLaMA2 70B模型,但是它的推理速度比LLaMA2-70B快6倍。因此是一个性能与速度兼备的大模型。
根据官方的介绍,Mistral-7B×8-MoE实际的参数为450亿,但是每次运行只会利用其中120亿参数(单个模型在56.5亿,但是可能有共享参数,每个token会被2个模型处理)。因此,这个模型的推理速度和成本与120亿参数规模的大模型是一样的。
如果GPT-3.5是1750亿的话,这意味着,Mistral-7B×8-MoE混合专家模型,可以每次只需要120亿参数参与推理就可以达到700亿的LLaMA2、1750亿的GPT-3.5的水平。而代码能力则和340亿的编程大模型CodeLLaMA2-34B差不多!这个成本与性能表现十分强悍!
Mistral-7B×8-MoE资源和其它信息
首先,Mistral-7B×8-MoE的官方HF库上有兼容vLLM的权重,非常快。而且支持bitsandbytes的8-bit和4-bit量化使用。并且支持Flash Attention 2。
Mistral-7B×8-MoE模型开源协议是Apache2.0,商用友好,更多Mistral-7B×8-MoE信息参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE
-----发布时信息-----------
Mistral-7B-MoE是MistralAI发布的一个基于混合专家(Mixture-of-Experts,MoE)技术的大语言模型。也是开源领域稍有的MoE实现的大模型。
在2023年12月8日,MistralAI的官方突然发布了一个大模型的下载链接(由于这个下载链接的文件夹名字是mixtral-8x7b-32kseqlen,因此,该模型也被很多人直接称mixtral-8x7b-32kseqlen),下载完成之后大家发现模型的配置显示这个模型是一个混合专家模型,具体的参数配置如下:
| 参数 | 值 |
|---|---|
| 维度(dim) | 4096 |
| 层数(n_layers) | 32 |
| 头维度(head_dim) | 128 |
| 隐藏层维度(hidden_dim) | 14336 |
| 头数(n_heads) | 32 |
| 键/值头数(n_kv_heads) | 8 |
| 归一化参数(norm_eps) | 1e-05 |
| 词汇表大小(vocab_size) | 32000 |
| MoE - 每令牌专家数(num_experts_per_tok) | 2 |
| MoE - 专家总数(num_experts) | 8 |
可以看到,这个模型的输入序列维度是4K,有8个专家网络,每个token会交由2个专家网络处理。这意味着完整的模型支持32K的输入!
该模型的下载链接:magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce
欢迎大家关注DataLearner官方微信,接受最新的AI模型和技术推送
