VisCPM-Chat - VisCPM-Chat
模型详细情况和参数
VisCPM-Chat
- 模型全称
- VisCPM-Chat
- 模型简称
- VisCPM-Chat
- 模型类型
- 聊天大模型
- 发布日期
- 2023-06-30
- 预训练文件大小
- 20.6GB
- 是否支持中文(中文优化)
- 是
- 最高支持的上下文长度
- 2K
- 模型参数数量(亿)
- 100.0
- 模型代码开源协议
- 通用模型许可协议-来源说明-宣传限制-非商业化
- 预训练结果开源商用情况
- 通用模型许可协议-来源说明-宣传限制-非商业化 - 收费商用授权
- 模型GitHub链接
- https://github.com/OpenBMB/VisCPM
- 模型HuggingFace链接
- https://huggingface.co/openbmb/VisCPM-Chat
- 在线演示地址
- 暂无
- 官方博客论文
- VisCPM
- 基础模型
-

CPM-Bee
查看详情 - 发布机构
- 评测结果
-
评测名称 评测能力方向 评测结果
VisCPM-Chat 简介
VisCPM-Chat是基于清华大学NLP小组发布的CPM-Bee模型(CPM Bee - 10B模型信息卡: https://www.datalearner.com/ai-models/pretrained-models/CPM-Bee )进行多模态训练得到的一个多模态对话模型。该系列模型包含2种,分别是VisCPM-Chat-balance与VisCPM-Chat-zhplus,前者是中英文能力平衡,后者则是中文能力更强。
关于VisCPM-模型的整体介绍参考: https://www.datalearner.com/blog/1051688132077366
VisCPM-Chat模型在中文多模对话、复杂推理方面都具有很好的效果。模型本身是基于基础语言模型外接视觉编解码得到的。如下图所示:
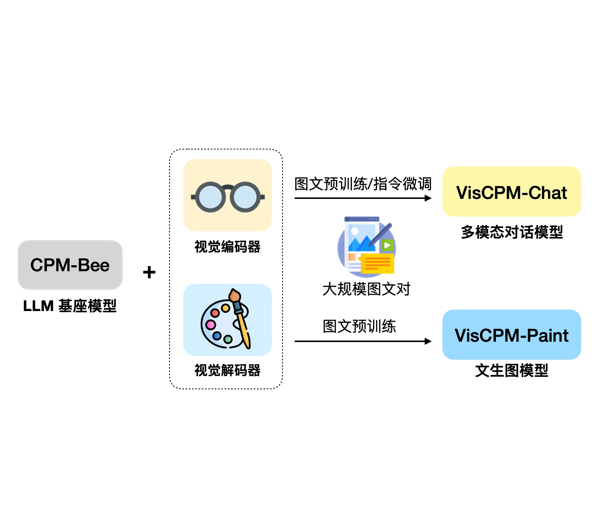
VisCPM-Chat模型训练细节
VisCPM-Chat模型是针对多模态对话进行优化的多模态大模型,是基座语言模型外接Q-Former视觉编码器和Diffusion-UNet视觉解码器其训练分为2个阶段:
预训练阶段:使用1亿条高质量英文图文对数据对VisCPM-Chat进行预训练,其中基座语言模型的参数保持固定,仅更新视觉编码器Q-Former部分的参数,用来做语言与视觉的对齐。
指令精调阶段:在预训练结束之后,需要让模型理解视觉相关的指令。因此,官方采用了LLaVA-150K英文指令精调数据集(LLaVA是微软官方发布的多模态大模型: https://www.datalearner.com/ai-models/pretrained-models/LLaVA )对模型进行精调。该阶段模型所有的参数都会更新。
官方在指令精调阶段发现一个有意思的现象:
有趣的是,我们发现即使仅采用英文指令数据进行指令精调,模型也可以理解中文问题,但仅能用英文回答。这表明模型的多语言多模态能力已经得到良好的泛化。
从这里也可以发现生成模型的优点,应该是其基础语言模型有中英文多语言的能力,基于中文问题,自然地可以生成英文回答,并生成了图像信息。
为了更好地支持中文的多模态对话能力,官方也收集了额外的2000万原生中文图文对数据以及1.2亿翻译后的中文图文数据对,然后在预训练阶段训练了另一个模型称为VisCPM-Chat-zhplus,也就是对中文理解的版本。原始版本则成为VisCPM-Chat-balance。
VisCPM-Chat模型开源和使用
不过可惜的是,该模型是收费商用授权(其语言模型的基座模型为CPM-Bee 10B,可免费商用授权),但是对个人和研究完全免费开源。
官方也放出了预训练结果的下载链接:
| VisCPM-Chat模型版本 | 版本说明 | 预训练下载地址 |
|---|---|---|
| VisCPM-Chat-balance | 中英文均衡 | huggingface/viscpm_chat_balance_checkpoint.pt |
| VisCPM-Chat-zhplus | 中文优化 | huggingface/viscpm_chat_zhplus_checkpoint.pt |
需要注意的是,VisCPM-Chat模型的载入需要40G的显存,开启CUDA_MEM_SAVE=True之后也需要22G显存,但是推理时间更长。
欢迎大家关注DataLearner官方微信,接受最新的AI模型和技术推送
