
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



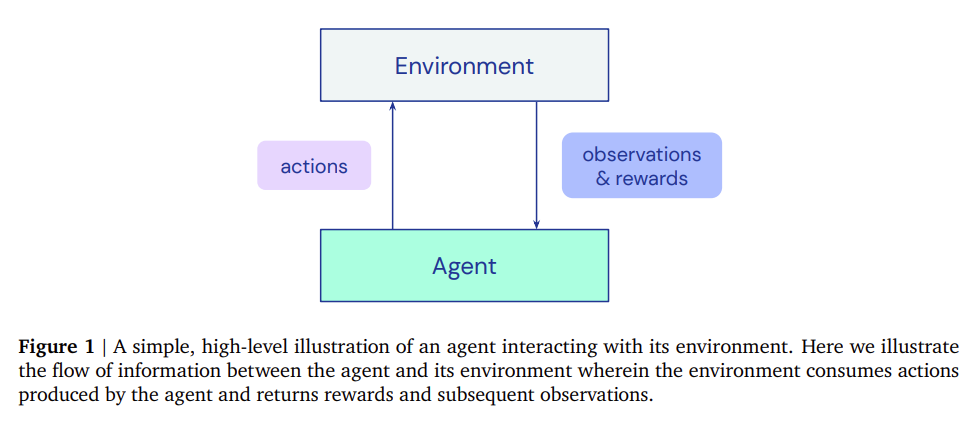
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的
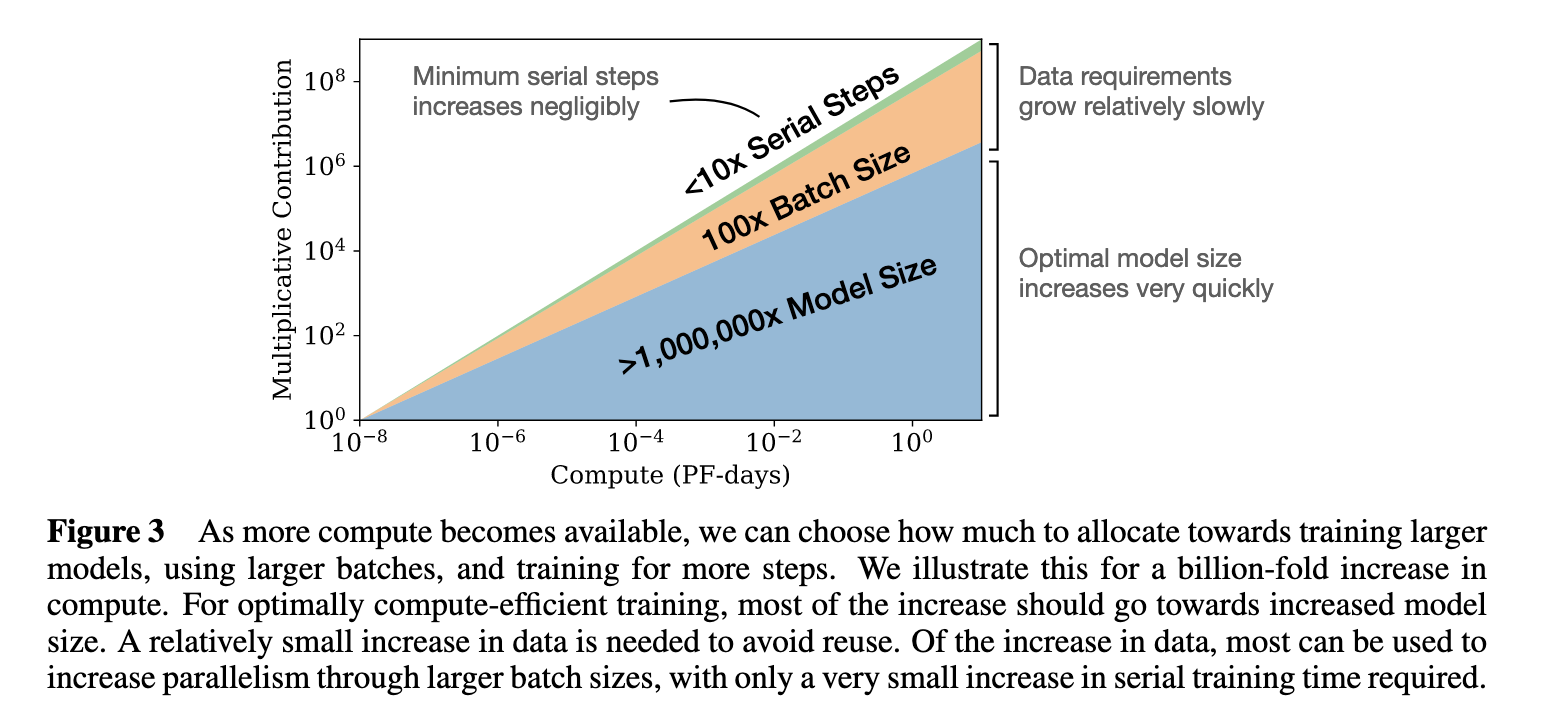
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。
今日推荐
为什么大语言模型的训练和推理要求比较高的精度,如FP32、FP16?浮点运算的精度概念详解
扩散模型是如何工作的:从0开始的数学原理——How diffusion models work: the math from scratch
开源大语言模型再次大幅进步:微软团队开源的第二代WizardLM2系列在MT-Bench得分上超过一众闭源模型,得分仅次于GPT-4最新版
马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
Claude Artifacts的复制?OpenAI发布ChatGPT协作新组件:Canvas,让你与ChatGPT共同处理写作与编程问题!