
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
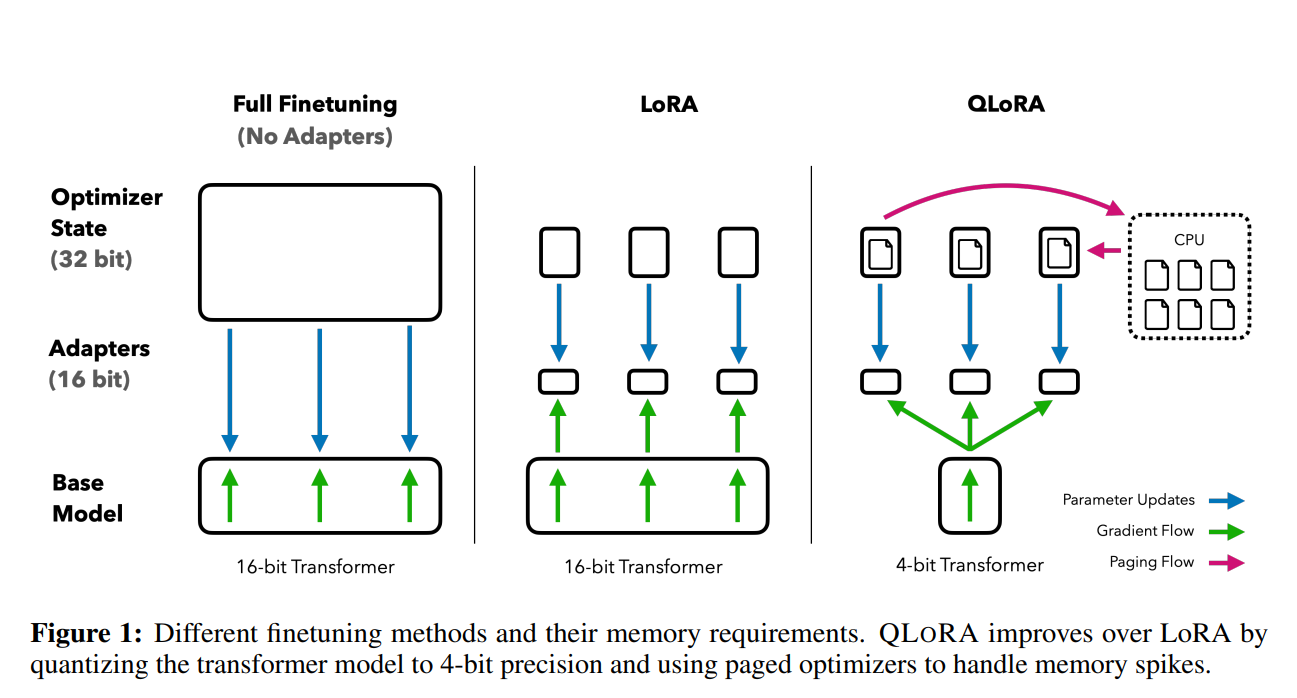
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
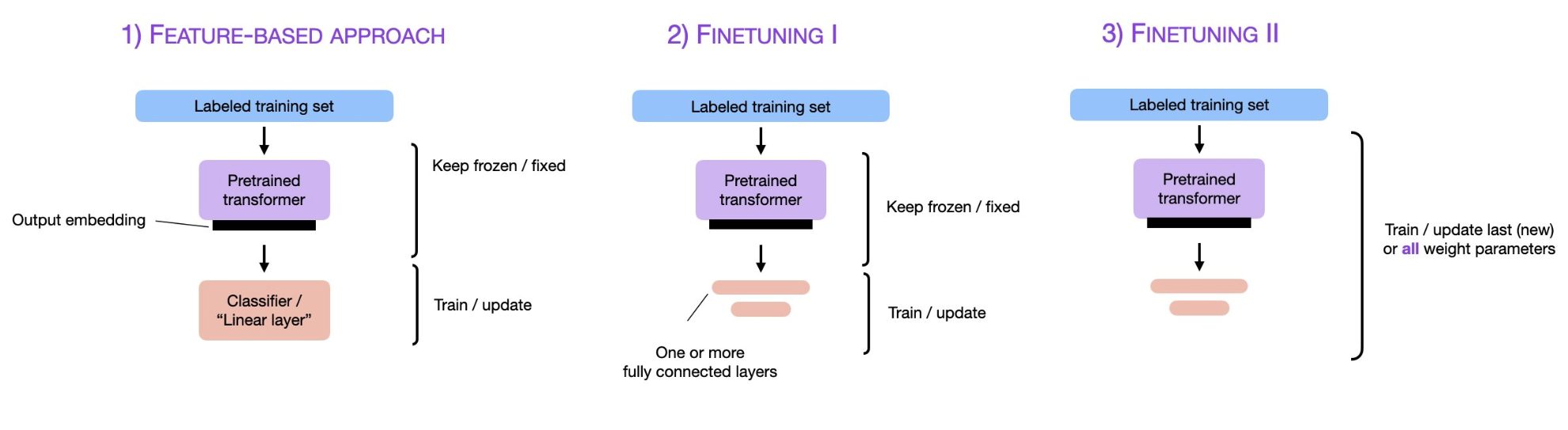
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
今日推荐
python中configparser读取配置文件的大小写和重复项问题
比Office Copilot更快一步~基于AI大语言模型生成PPT、Word和网页的应用的新产品测试~Gamma.APP,PPT打工人必备
关于OpenAI最新的营收和成本数据估算:包括ChatGPT Plus付费用户数以及OpenAI的月度成本等
Saleforce发布最新的开源语言-视觉处理深度学习库LAVIS
ChatGPT官方代码解释器插件Code-Interpreter大揭秘:Code-Interpreter背后都有什么(执行环境、硬件资源、包含的Python库等)?
重磅!MetaAI开源4050亿参数的大语言模型Llama3.1-405B模型!多项评测结果超越GPT-4o,与Claude-3.5 Sonnet平分秋色!