
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



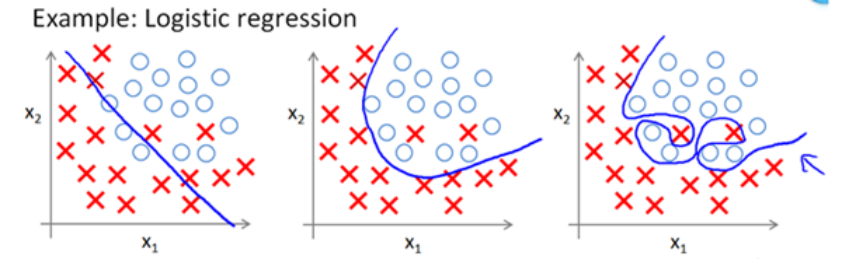
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?
今日推荐
为什么大语言模型的训练和推理要求比较高的精度,如FP32、FP16?浮点运算的精度概念详解
预训练大语言模型的三种微调技术总结:fine-tuning、parameter-efficient fine-tuning和prompt-tuning
可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数
Dirichlet Distribution(狄利克雷分布)与Dirichlet Process(狄利克雷过程)
抛弃RLHF?MetaAI发布最新大语言模型训练方法:LIMA——仅使用Prompts-Response来微调大模型
OpenAI开源GPT-2的子词标记化神器——tiktoken,一个超级快的(Byte Pair Encoder,BPE)字节对编码Python库