
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



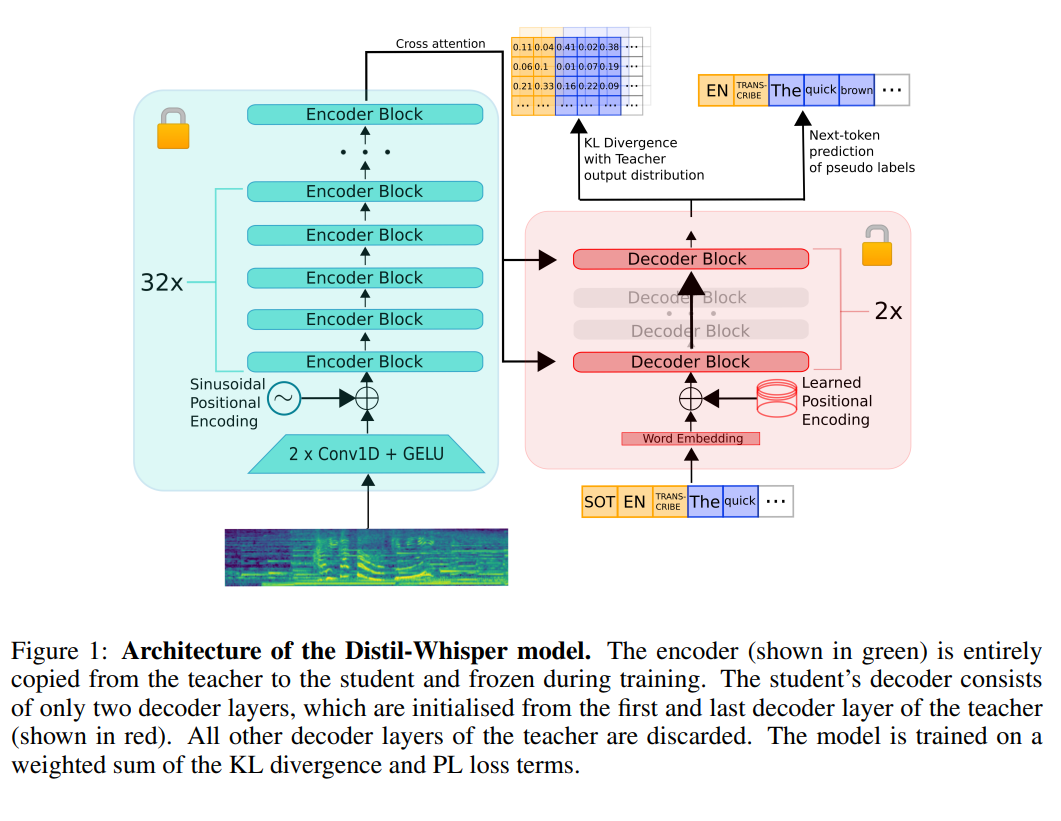
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!