
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



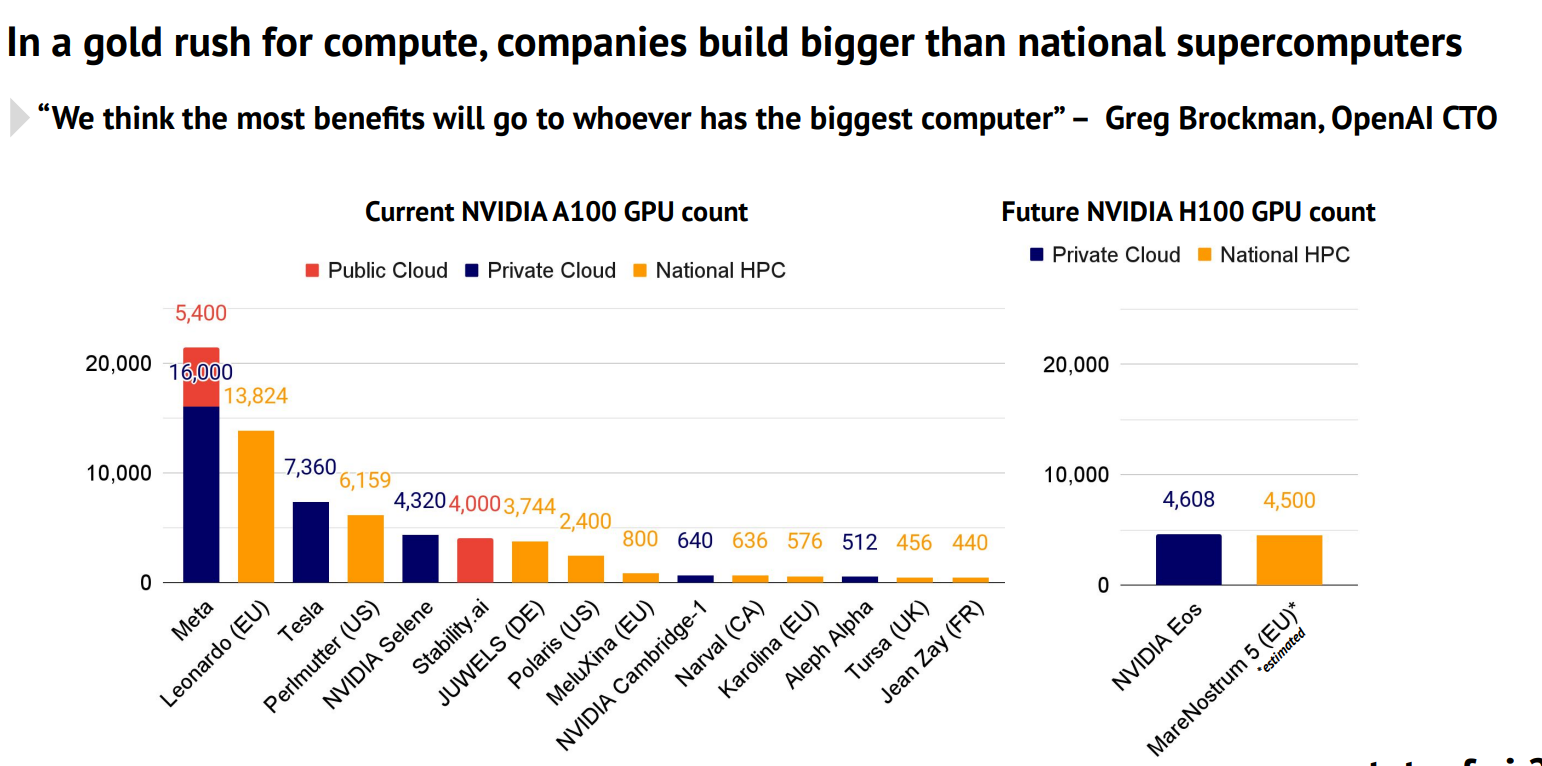
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。

Stable Diffusion XL是StabilityAI最新的开源模型。是目前业界流行的免费开源图像生成大模型。2023年4月份StabilityAI就宣布了SD XL的存在并在2023年7月26日开源。SD XL相比较此前的模型速度更快、提示词更短、生成的图像更加真实。但是,大多数人可能并没有实际运行过,感受过这个模型的魅力。在这篇博客中,我们给大家展示如何利用Google Colab的免费GPU资源,部署一个SD XL模型,并通过prompt生成一些图片。
文中整理和总结了几个关于开源大模型微调方面的问题,答案主要来自gpt4 + google,如果其中部分问题的答案不准确,烦劳指正 (文中引用了外部资源链接,如果涉及版权问题,烦劳联系作者删除)

GPU Utils最近总结了一个关于英伟达H100显卡在AI训练中的应用文章。里面透露总结了一些当前的主流厂商拥有的显卡数量以及一些模型训练所需的显卡数。文章主要描述的是H1000的供应与需求,也包含H100的性能描述,本文主要总结一下里面提到的显卡数相关统计供大家参考。
Kaggle是机器学习竞赛平台当之无愧的老大,除了提供了平台让企业和研究机构发布机器学习相关竞赛来让大家竞技和交流以外,他们还提供了免费的编程平台让大家使用免费的GPU和内存来训练模型和测试模型效果。而昨天,Kaggle升级了这些免费资源服务。
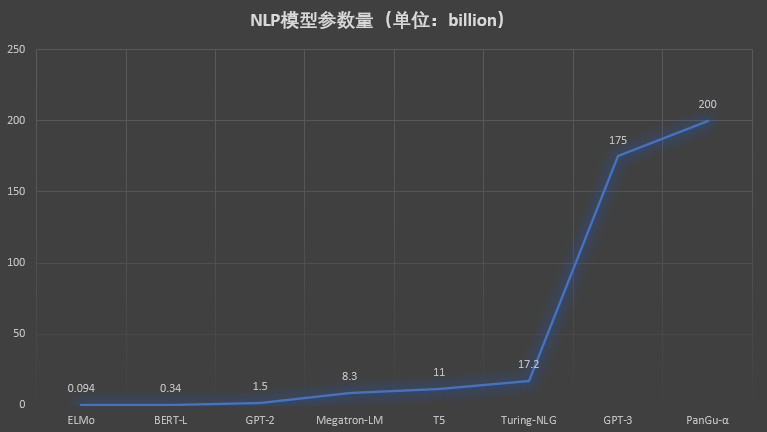
这几年深度学习的发展给人工智能相关应用的落地带来了很大的促进。随着NLP、CV相关领域的算法的发展,算法层面的创新已经逐渐慢了下来,但是工程方面的研究依然非常火热。从底层的硬件的创新,到平台框架的发展,为支撑超大规模模型训练与移动端小规模算法推断而创造的软硬件体系也在飞速革新。本文将总结深度学习平台框架软件及下层的硬件支撑系统。
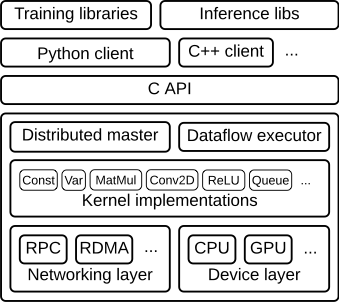
随着深度学习的火热,对计算机算力的要求越来越高。从2012年AlexNet以来,人们越来越多开始使用GPU加速深度学习的计算。 然而,一些传统的机器学习方法对GPU的利用却很少,这浪费了很多的资源和探索的可能。在这里,我们介绍一个非常优秀的项目——RAPIDS,这是一个致力于将GPU加速带给传统算法的项目,并且提供了与Pandas和scikit-learn一致的用法和体验,非常值得大家尝试。

今日推荐
如何基于PyTorch来优化大模型训练的内存(显存)使用:8种方法总结
手把手教你本地部署清华大学的ChatGLM-6B模型——Windows+6GB显卡本地部署
三层Dirichlet 过程(非参贝叶斯模型)-来自Machine Learning
Batch Normalization应该在激活函数之前使用还是激活函数之后使用?
让大模型支持更长的上下文的方法哪个更好?训练支持更长上下文的模型还是基于检索增强?
国产MoE架构模型大爆发!深圳元象科技XVERSE开源256亿参数MoE大模型XVERSE-MoE-A4.2B,评测结果接近Llama1-65B