
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



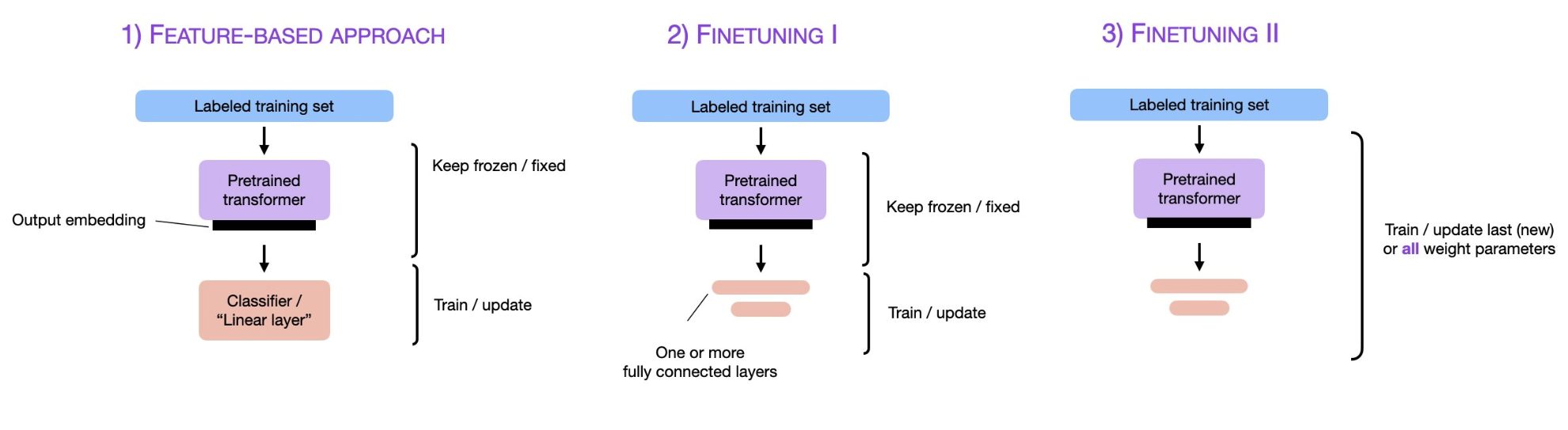
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
今日推荐
Google最新超大模型Pathways:一个会讲笑话的6400亿参数的语言模型
张华平分词(又名中科院分词/NLPIR分词)的使用(Java版本)
HuggingFace开源语音识别模型Distil-Whisper,基于OpenAI的Whisper-V2模型蒸馏,速度快6倍,参数小49%!
text-davinci-003后继者!OpenAI发布了一个新的补全大模型:GPT-3.5-Turbo-Instruct,完全的指令模型,没有聊天优化
开源界最新力作!230万篇arXiv的论文标题和摘要的所有embeddings向量数据集免费开放!
PyTorch 2.0发布——一个更快、更加Pythonic和灵活的PyTorch版本,让Tranformer运行更快!