
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



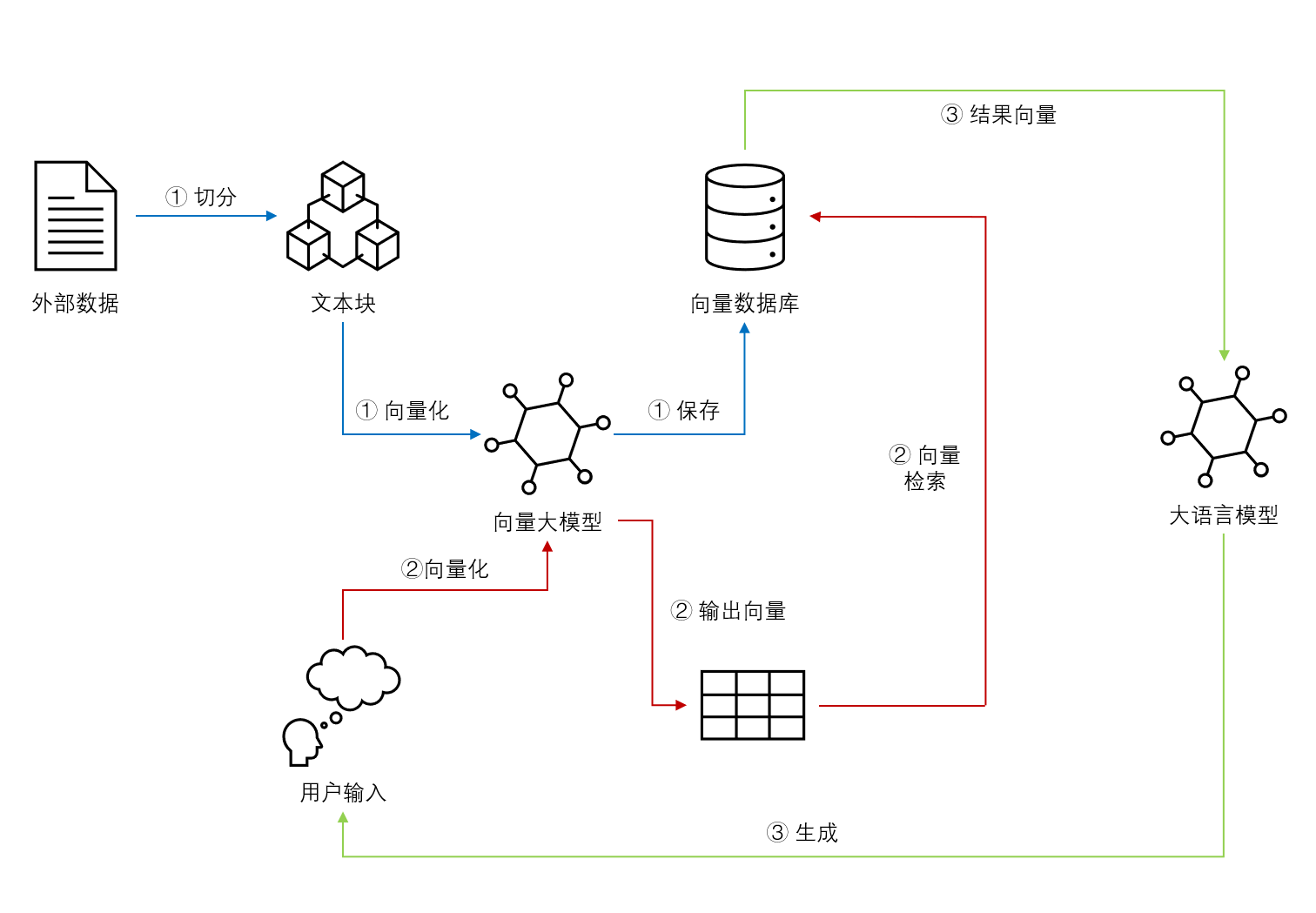
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。
今日推荐
超越Cross-Entropy Loss(交叉熵损失)的新损失函数——PolyLoss简介
OpenAI官方最新研究成果:如何用GPT-4这样的语言模型来解释语言模型中的神经元(neurons)
OpenAI正式开放ChatGPT Team订阅计划,价格每个月贵25%,更多的GPT-4,附ChatGPT付费计划对比
SlimPajama:CerebrasAI开源最新可商用的高质量大语言模型训练数据集,含6270亿个tokens!
华为大模型生态重要一步!PyTorch最新2.1版本宣布支持华为昇腾芯片(HUAWEI Ascend)
Google前AI研究人员认为2024年可能不会出现能与GPT-4竞争的开源模型/产品
一个基于Python的机器学习项目——各种Kaggle比赛的解决方案
Google发布迄今为止公开可用的最大的多语言网络数据集MADLAD-400,覆盖419种语言
开源大语言模型再次大幅进步:微软团队开源的第二代WizardLM2系列在MT-Bench得分上超过一众闭源模型,得分仅次于GPT-4最新版