
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



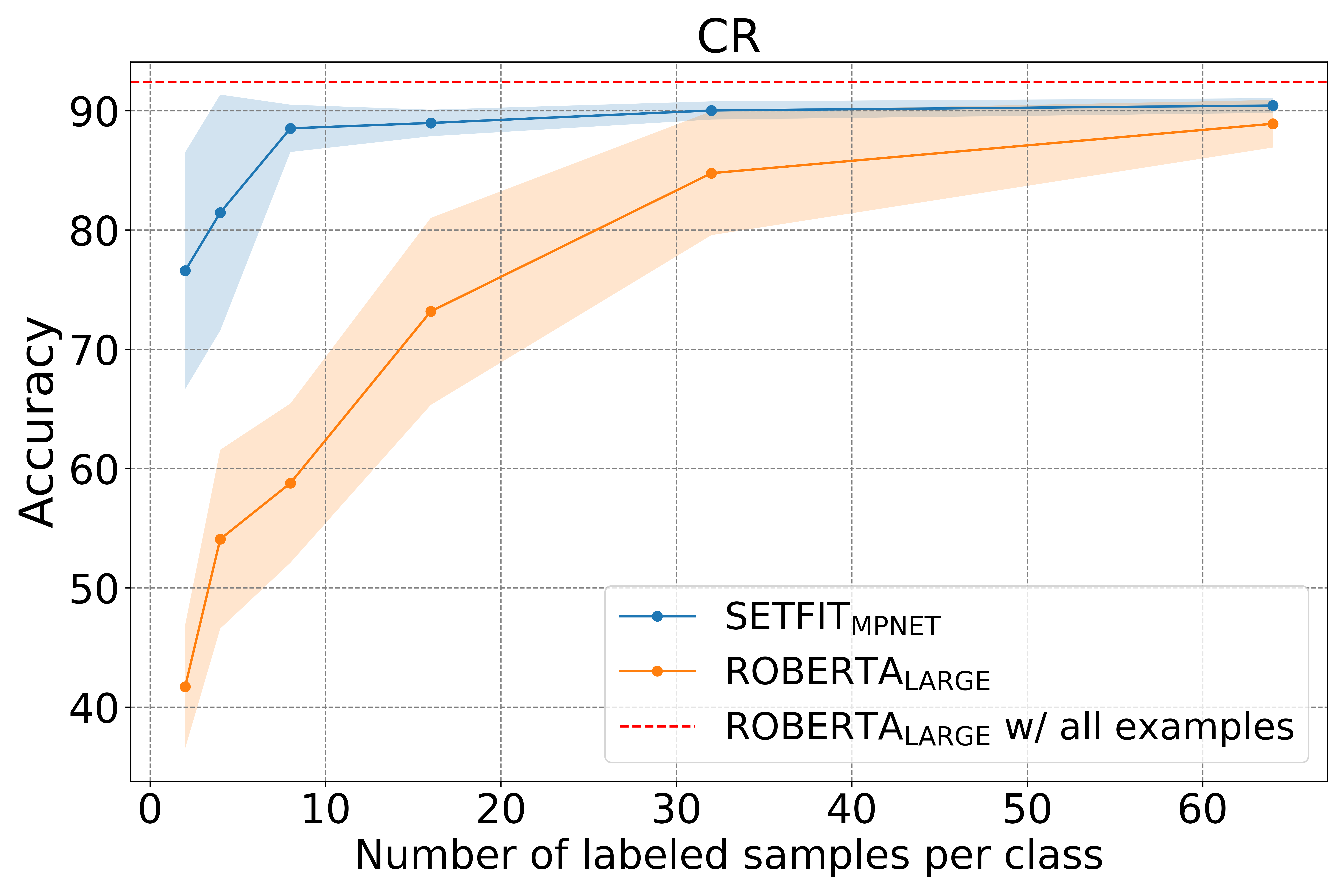
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。
今日推荐
Tensorflow中数据集的使用方法(tf.data.Dataset)
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
深度学习卷积操作的维度计算(PyTorch/Tensorflow等框架中Conv1d、Conv2d和Conv3d介绍)
重磅!谷歌开源Gemini同源技术大模型Gemma,分别为70亿参数和20亿参数,同等规模参数评测极其优秀!
多元正态(高斯)分布的贝叶斯推导(Bayesian Inference for the Multivariate Normal)
AI Agent进展再进一步!Anthropic发布大模型上下文连接访问协议MCP:让任何资源快速变成大模型的工具,突破大模型的能力边界!
text-davinci-003后继者!OpenAI发布了一个新的补全大模型:GPT-3.5-Turbo-Instruct,完全的指令模型,没有聊天优化