
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
深度求索是著名量化机构幻方量化旗下的一家大模型初创企业,成立与2023年7月份。他们开源了很多大模型,其中编程大模型DeepSeek-Coder系列获得了非常多的好评。而在今天,DeepSeek-AI再次开源了全新的多模态大模型DeepSeek-VL系列,包含70亿和13亿两种不同规模的4个版本的模型。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。
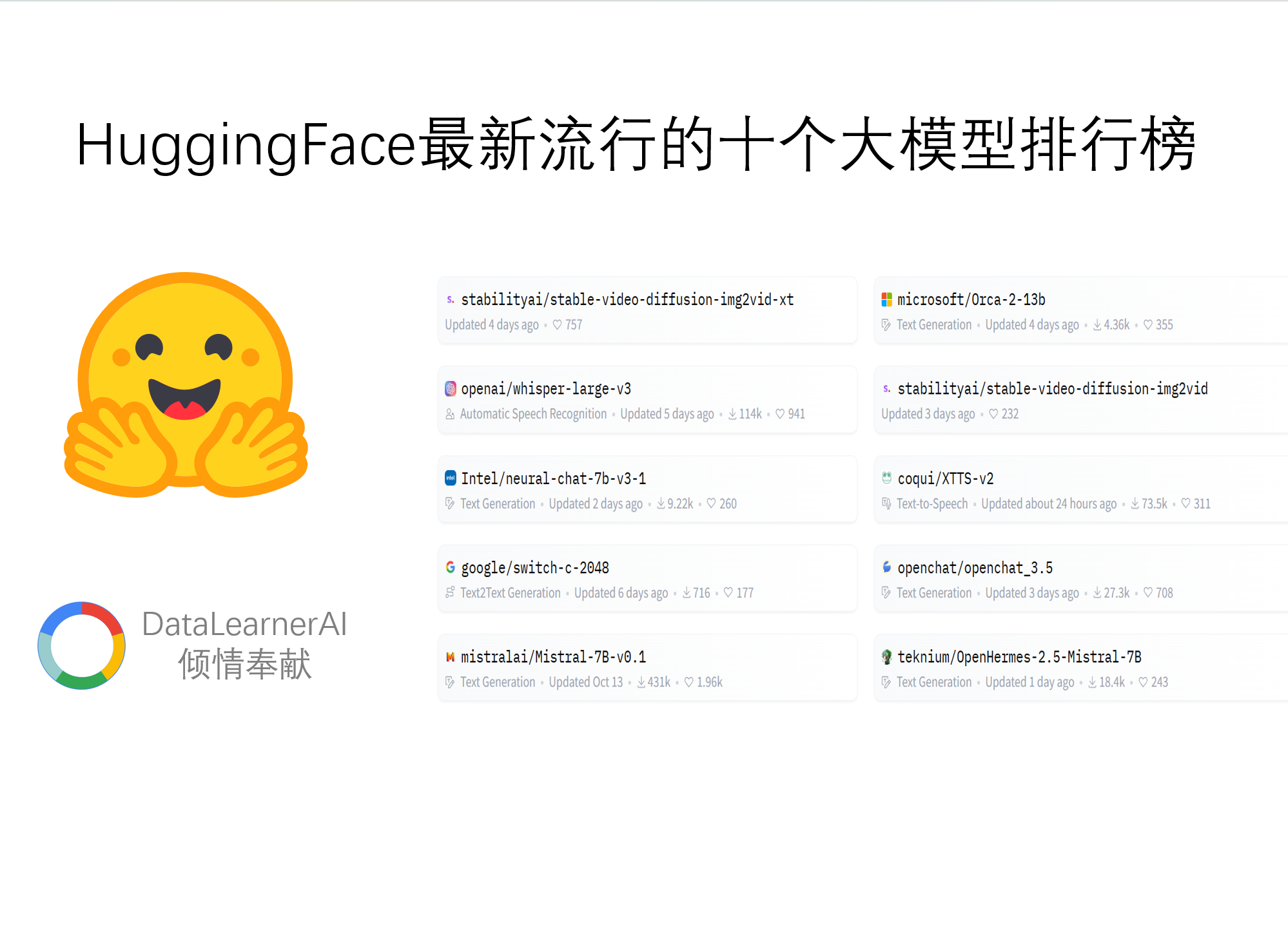
在本周,HuggingFace最流行的十个大模型多模态模型占了4个,包括StabilityAI最新开源的文本生成视频大模型Stable Video Diffusion、Coqui最新的语音合成大模型XTTS第二代等都吸引了大量的关注多。而大语言模型中,谷歌开源了2022年就已经发布的Switch大模型,该模型号称参数可以达到上万亿,也是十分有意思。

几分钟之前,OpenAI宣布ChatGPT支持多模态,目前已经支持语音的输入、语音的输出、理解图片的输入!不过目前似乎仅限于客户端~官方说的是未来2周内企业和Plus用户可以使用,后面会普及到其它用户!

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。
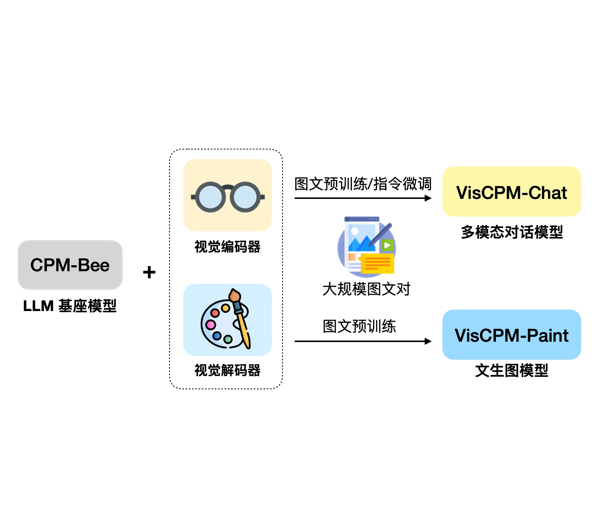
大模型的发展正在从单纯的语言模型向多模态大模型快速发展。尽管GPT-4号称也是一个多模态大模型,但是受限于GPU资源,GPT-4没有开放任何多模态的能力(参考:https://www.datalearner.com/blog/1051685866651273 )。目前大家所能接触到的多模态大模型很少。今天,清华大学NLP小组带来了新的选择,发布了VisCPM系列多模态大模型。VisCPM系列包含2类多模态大模型,分别针对多模态对话和文本生成图片进行优化。
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
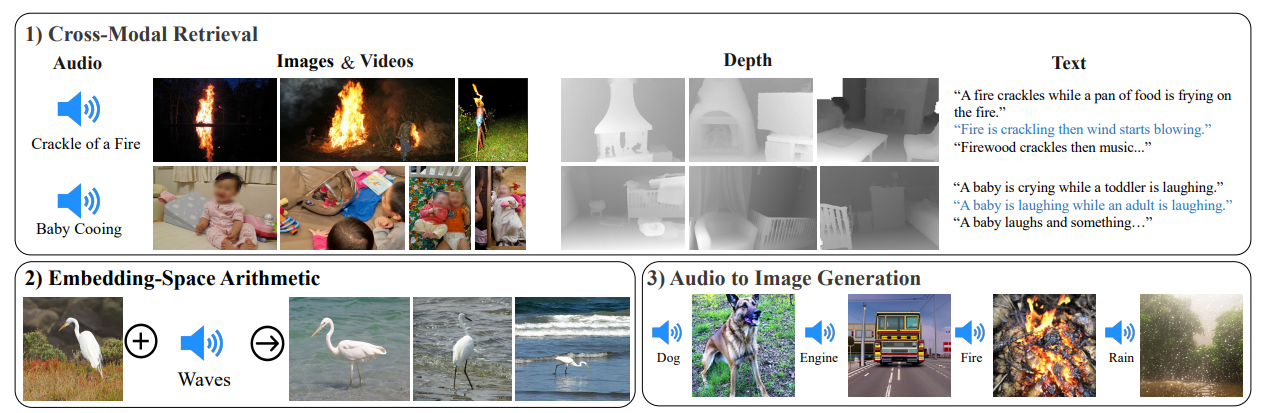
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。
今日推荐
Seq2Seq的建模解释和Keras中Simple RNN Cell的计算及其代码示例
Pseudo-document-based Topic Model(基于伪文档的主题模型)的理解以及源码解读
2022年9月份最火的10个AI研究——基于GitHub的Star数量排序
Claude Artifacts的复制?OpenAI发布ChatGPT协作新组件:Canvas,让你与ChatGPT共同处理写作与编程问题!
截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
5月3日,2个重磅开源的AI模型发布:Replit代码补全大模型和LLaMA复刻版OpenLLaMA发布
Hugging Face发布最新的深度学习模型评估库Evaluate!
智源人工智能研究院开源可商用的编程大模型:悟道·天鹰AquilaCode系列,超过清华大学CodeGeeX
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!
Google Gemini Pro多模态接口开放!DataLearnerAI第一时间测试Gemini Pro多模态能力,比想象惊喜!