
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。
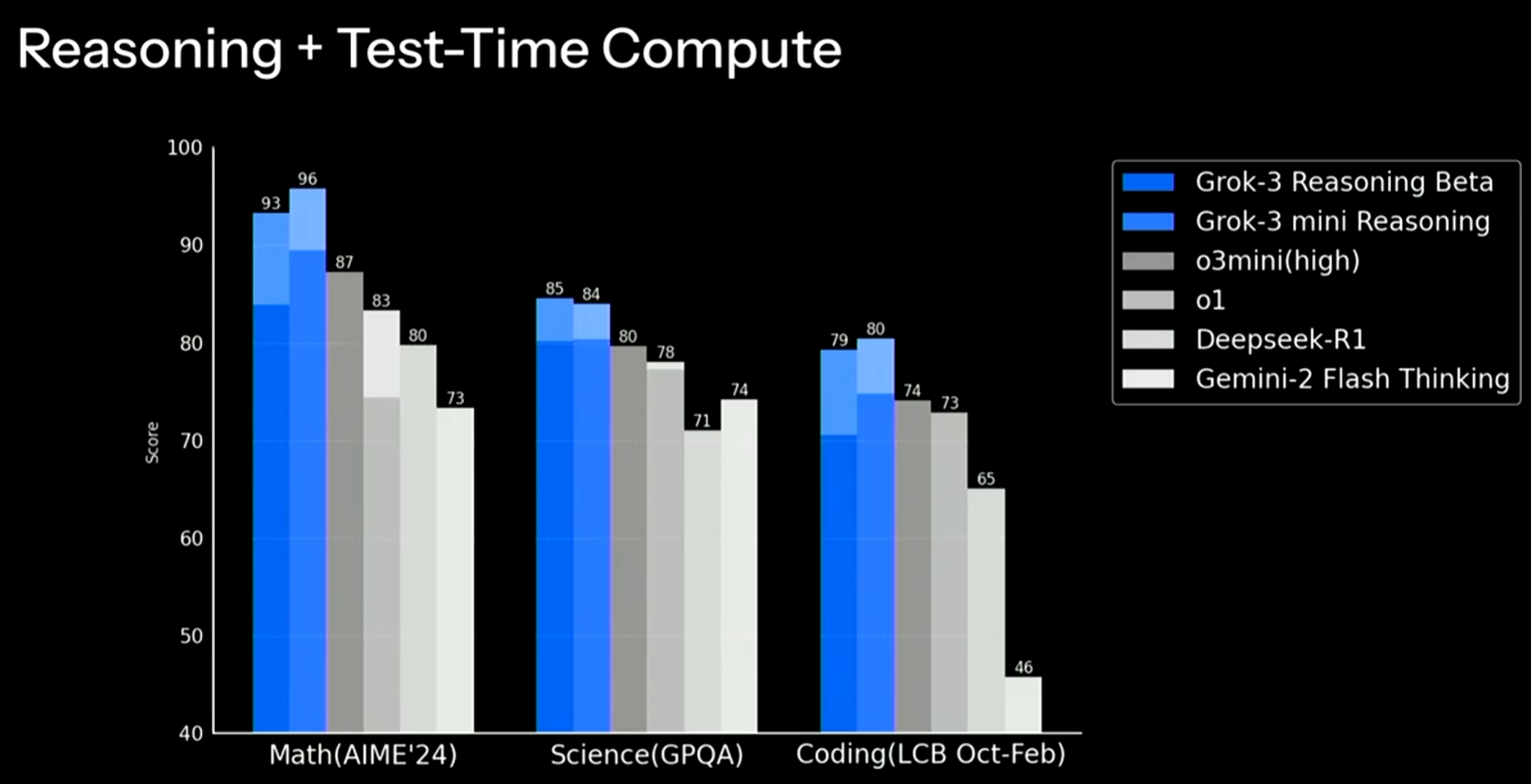
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。
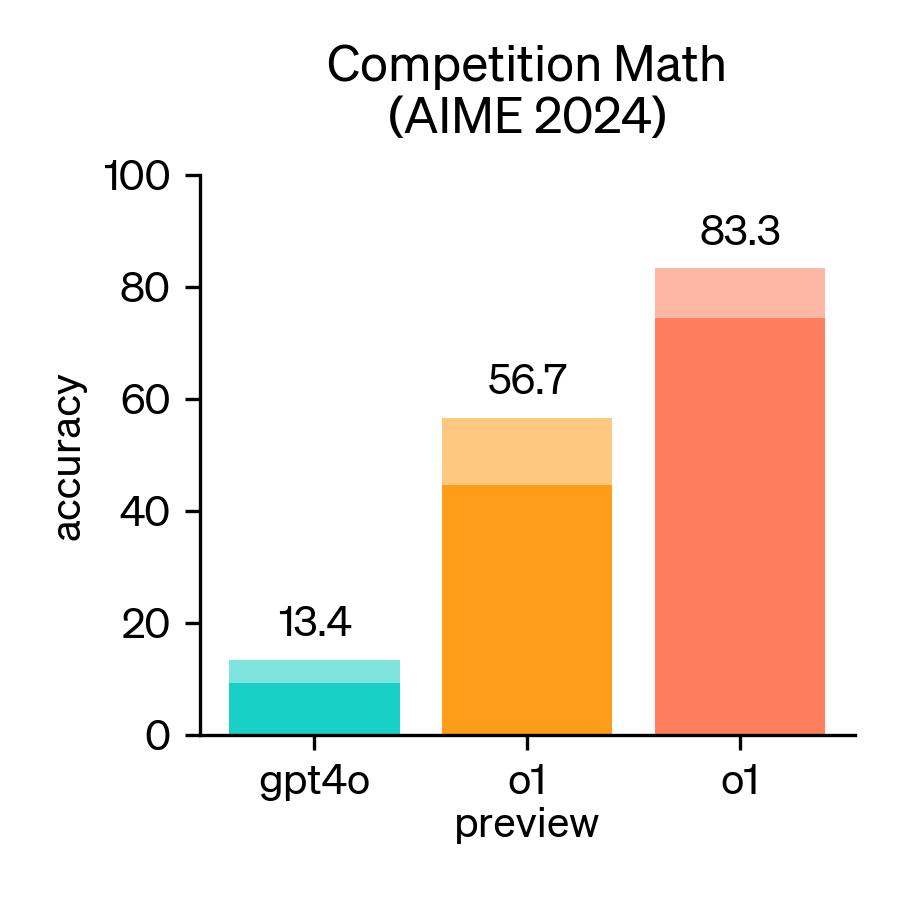
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。

最近,一些未公开但即将发布的内容被曝出,显示出Anthropic正在为其AI模型(Claude)推出一项名为Thinking的新功能。这一功能将极大提升AI在推理和决策时的透明度,允许用户查看AI的思考过程,并提供更长时间的推理分析,帮助用户更好地理解和验证AI的决策逻辑。
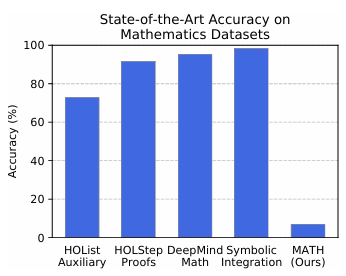
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。

随着DeepSeek R1和OpenAI的o1、o3等推理大模型的发布,我们当前可使用的大模型种类也变多了。但是,推理大模型和普通大模型之间并不是二选一的关系,在不同的问题上二者各有优势。为了让大家更清晰理解推理大模型和普通大模型的应用场景。OpenAI官方推出了一个推理大模型最佳实践指南。描述了二者的对比。本文将总结这份推理大模型最佳实践指南。
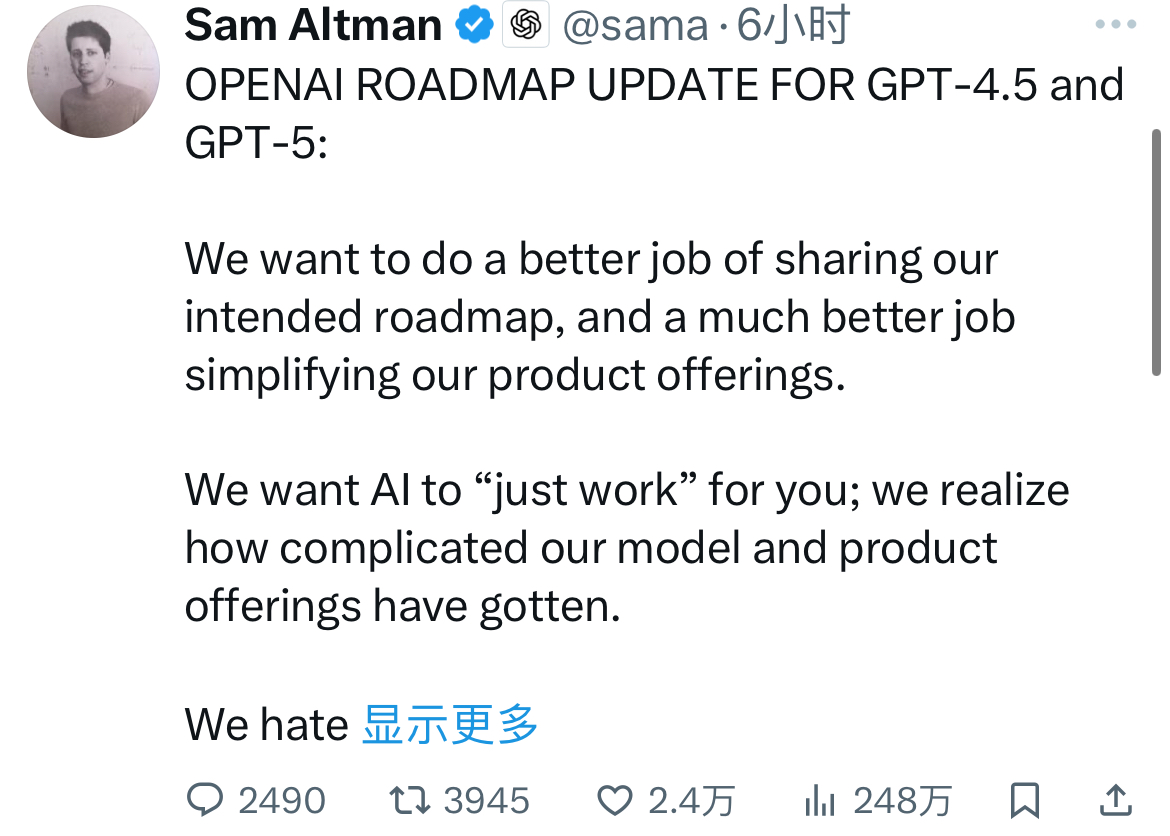
三个小时前,Sam Altam在推特上说明了OpenAI未来的大模型路线图。比较重磅的消息是即将在未来几周发布GPT-4.5,并且在几个月后发布GPT-5。
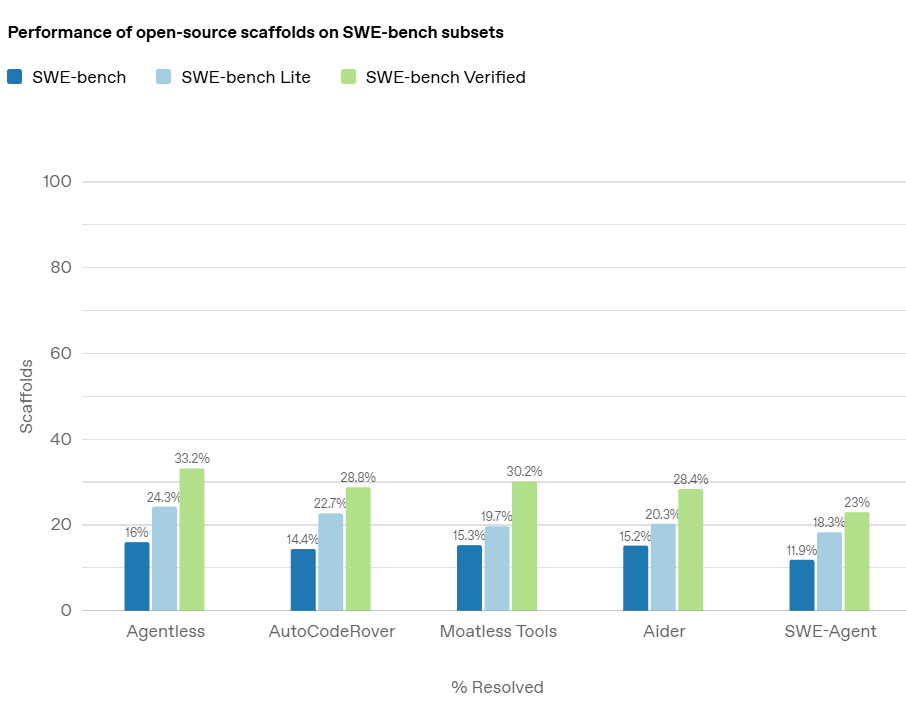
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
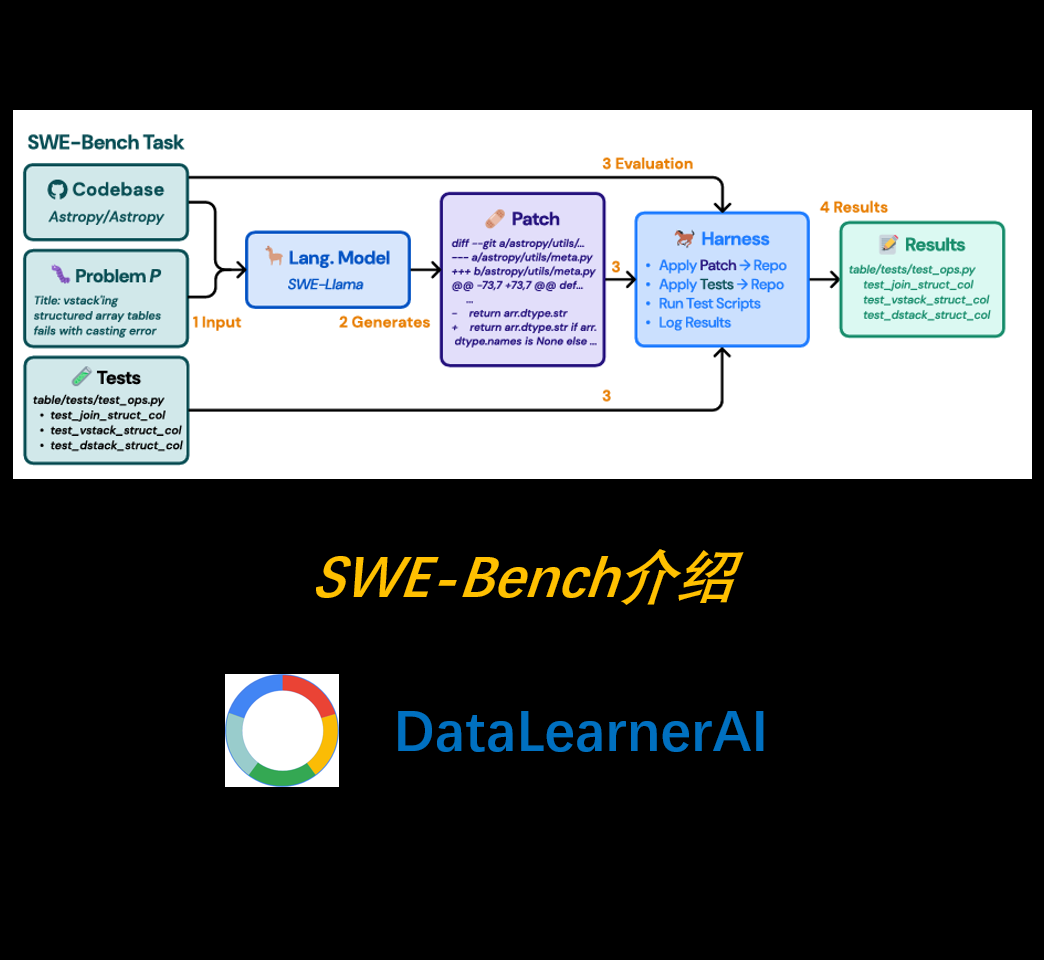
随着大语言模型(LLM)的快速发展,它们在自然语言处理(NLP)、代码生成等领域的表现已达到前所未有的高度。然而,现有的代码评测基准(如 HumanEval)通常侧重于**自包含的、较短的代码生成任务**,而未能充分模拟真实世界的软件开发环境。为弥补这一空白,研究者提出了一种全新的评测基准——**SWE-Bench**,旨在测试 LLM 在**真实软件工程问题**中的能力。

全球知名AI基准测试机构Artificial Analysis最新发布的2025年第一季度报告揭示了一个引人注目的重要趋势:在大语言模型领域,全球正在形成中美双极主导的新格局。这份权威报告通过严谨的技术指标评测体系,首次以数据量化的方式确认了中国AI技术水平的跨越式发展,特别是在顶尖大模型的研发领域,中国已经实质性地跻身全球第一梯队。本文根据报告的主要内容,为大家总结他们的一些观点和数据。

最近,随着DeepSeek R1的火爆,推理大模型也进入大众的视野。但是,相比较此前的GPT-4o,推理大模型的区别是什么?它适合什么样的任务?推理大模型是如何训练出来的?很多人并不了解。本文将详细解释推理大模型的核心内容。
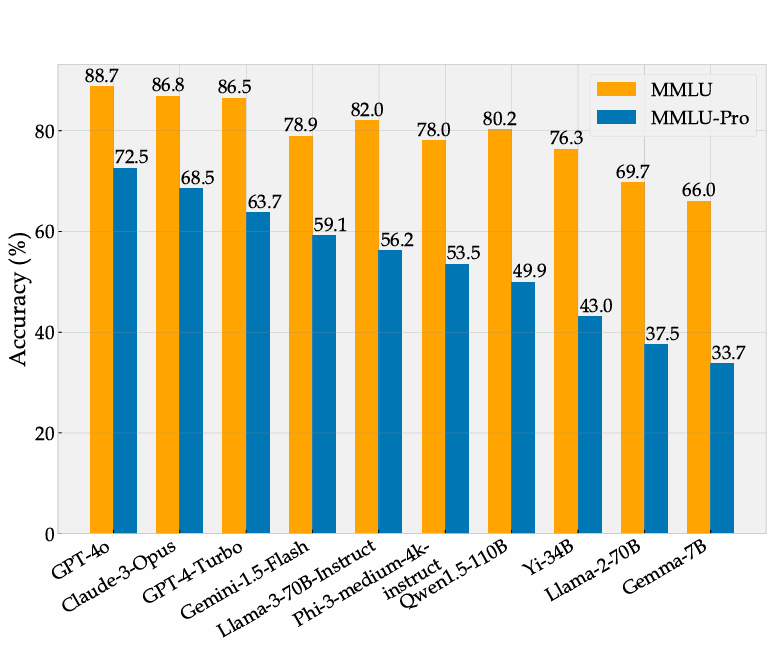
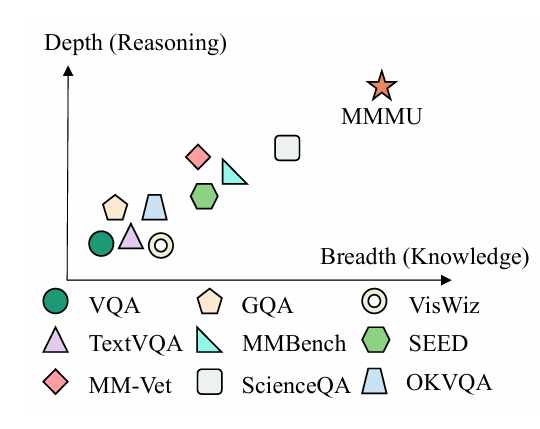
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。 以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。 为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU P

通用人工智能(AGI)的进步需要可靠的评估基准。GPQA (Grade-Level Problems in Question Answering) Diamond 基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力。该基准由纽约大学、CohereAI 及 Anthropic 的研究人员联合发布,其相关论文可在 arXiv 上查阅 (https://arxiv.org/pdf/2311.12022 )。GPQA Diamond是GPQA系列中最高质量的评测数据,包含198条结果。
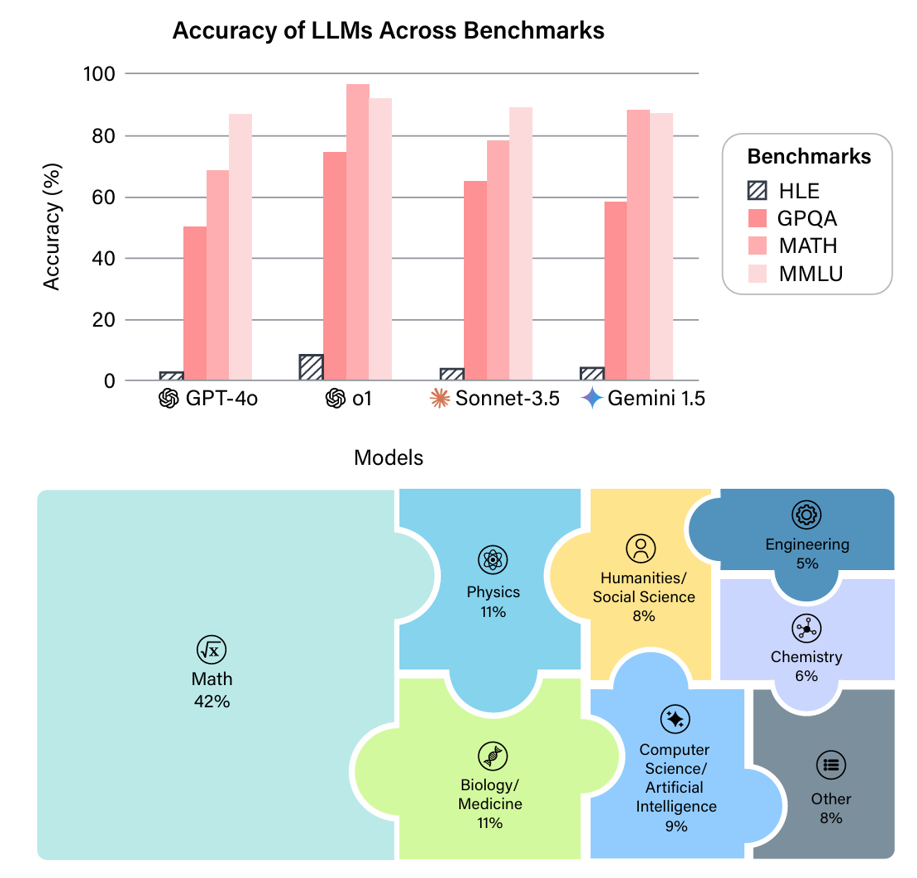
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。