
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。
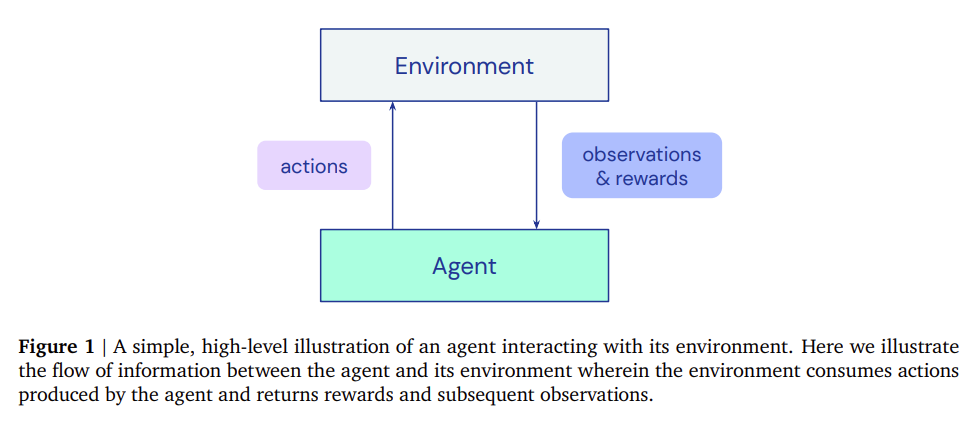
深度强化学习(RL)导致了许多最近的和突破性的进展。然而,强化学习的实施并不容易,与使深度学习拥有PyTorch这样简单的框架支持不同,强化学习的训练缺少强有力的工具支撑。为了解决这些问题,DeepMind发布了Acme,一个用于构建新的RL算法的框架,该框架是专门为实现代理而设计的
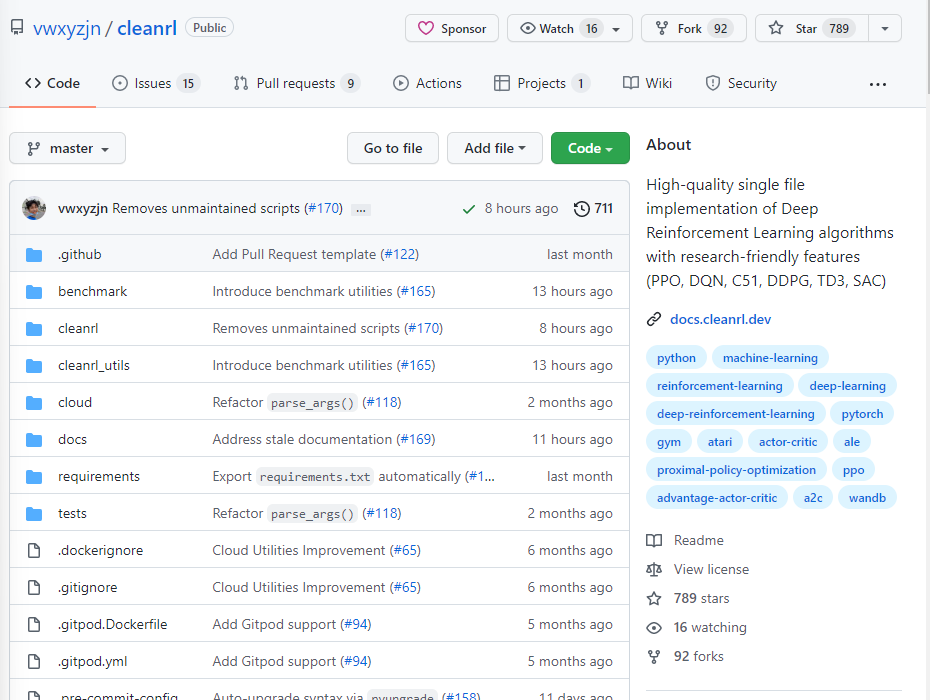
很多算法的开源实现都包含多个文件,因此,学习这些开源代码的时候通常难以找到入口,也无法快速理解作者的逻辑,对于学习的童鞋来说都带来了不小的挑战。这里推荐一个非常优秀的强化学习开源库,它将经典的强化学习算法都实现在一个文件中,想要学习源代码的童鞋只需要看单个文件即可,这就是ClearRL!