
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



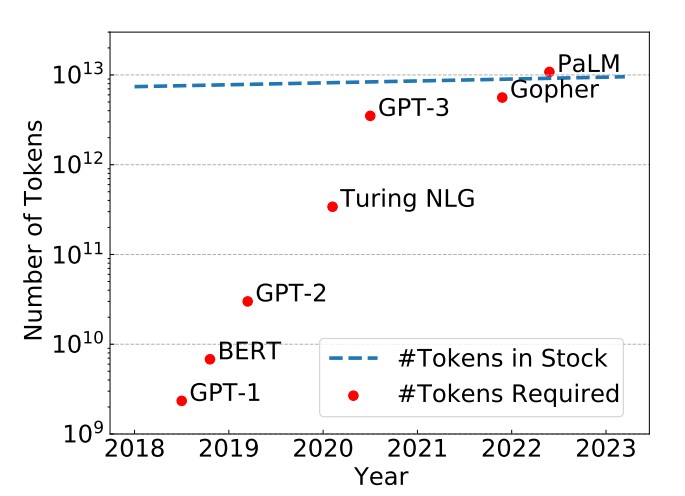
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
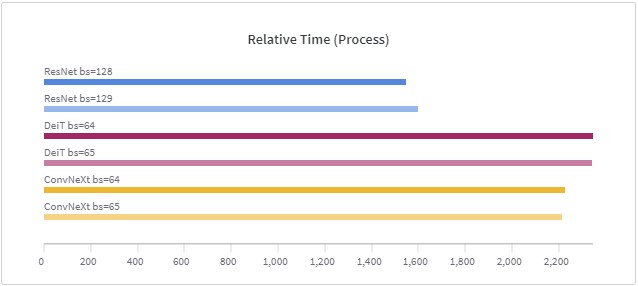
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。
今日推荐
最强AI对话系统ChatGPT不完全使用指南——已发掘功能展览!
Qwen1.5系列再次更新:阿里巴巴开源320亿参数Qwen1.5-32B模型,评测结果超过Mixtral 8×7B MoE,性价比更高!
开源界最新力作!230万篇arXiv的论文标题和摘要的所有embeddings向量数据集免费开放!
Anthropic的Claude 4即将发布前新功能曝光:带有Thinking模式,且可以看到推理过程
Gamma函数(伽玛函数)的一阶导数、二阶导数公式推导及java程序
提炼BERT——将BERT转成小模型(Distilling BERT — How to achieve BERT performance using Logistic Regression)