
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



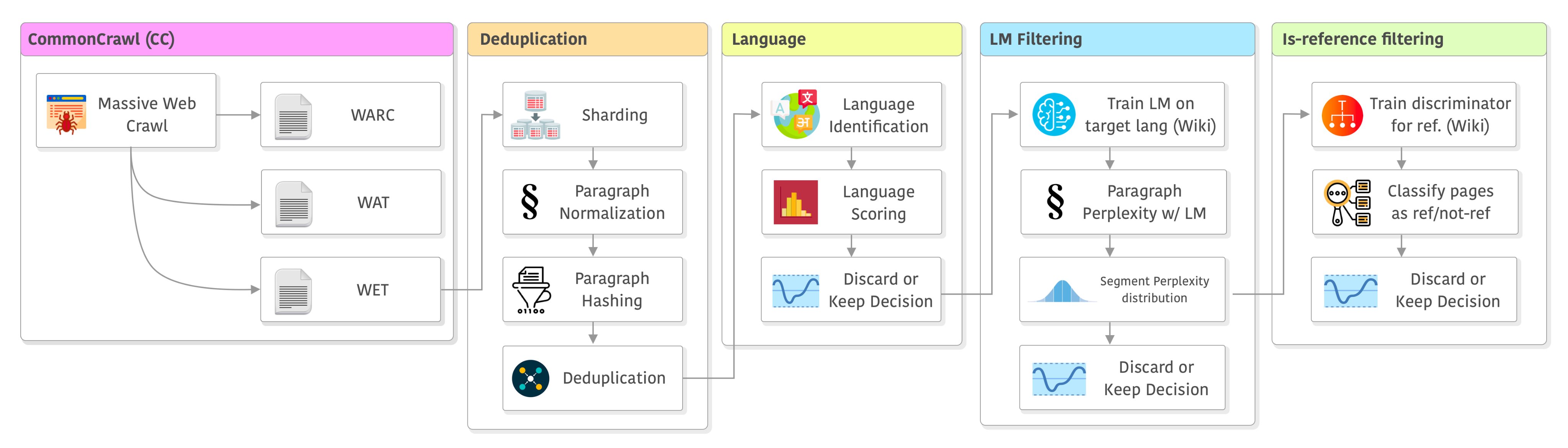
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。

当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
今日推荐
层次狄利克雷过程(Hierarchical Dirichlet Processes)
三层Dirichlet 过程(非参贝叶斯模型)-来自Machine Learning
重磅!来自Google内部AI研究人员的焦虑:We Have No Moat And neither does OpenAI
Java爬虫入门简介(四)——HttpClient保存使用Cookie登录
Falcon-40B:截止目前最强大的开源大语言模型,超越MetaAI的LLaMA-65B的开源大语言模型
70亿参数规模大模型新选择:Deci开源DeciLM-7B大模型,评测效果远超Llama2-7B,每秒可生成328个tokens。
可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数