
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
大语言模型的训练和微调的硬件资源要求很高。现行主流的大模型训练硬件一般采用英特尔的CPU+英伟达的GPU进行。主要原因在于二者提供了符合大模型训练所需的计算架构和底层的加速库。但是,最近苹果M2 Ultra和AMD的显卡进展让我们看到了一些新的希望。
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。

本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。
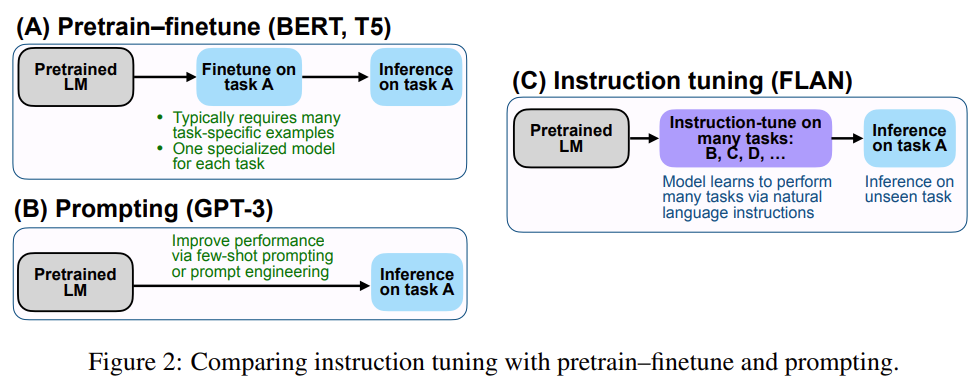
Prompt-Tuning、Instruction-Tuning和Chain-of-Thought是近几年十分流行的大模型训练技术,本文主要介绍这三种技术及其差别。
今日推荐
Seq2Seq的建模解释和Keras中Simple RNN Cell的计算及其代码示例
苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比!
ChatGPT 3.5只有200亿规模的参数?最新微软的论文暴漏OpenAI的ChatGPT的参数规模远低于1750亿!
HuggingFace开源语音识别模型Distil-Whisper,基于OpenAI的Whisper-V2模型蒸馏,速度快6倍,参数小49%!
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!
大模型驱动的自动代理(AI Agent):将语言模型的能力变成通用能力的一种方式——来自OpenAI安全团队负责人的解释与观点
来自Microsoft Build 2023:大语言模型是如何被训练出来的以及语言模型如何变成ChatGPT——State of GPT详解