
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



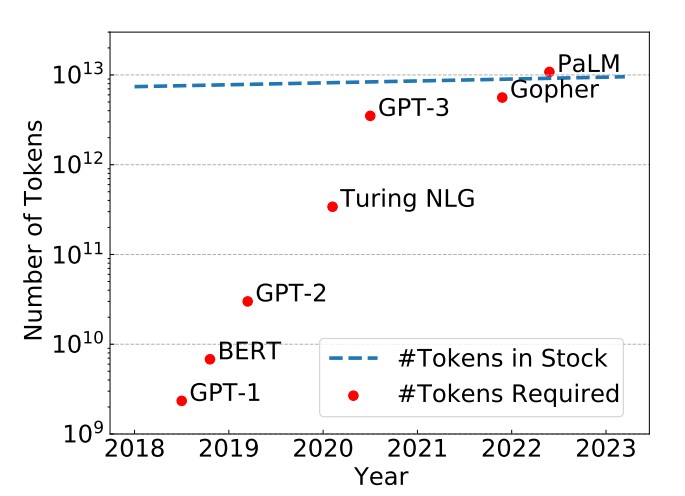
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?
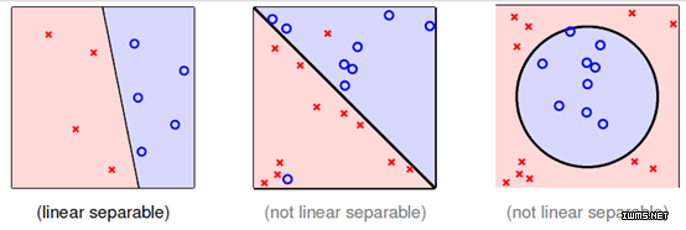
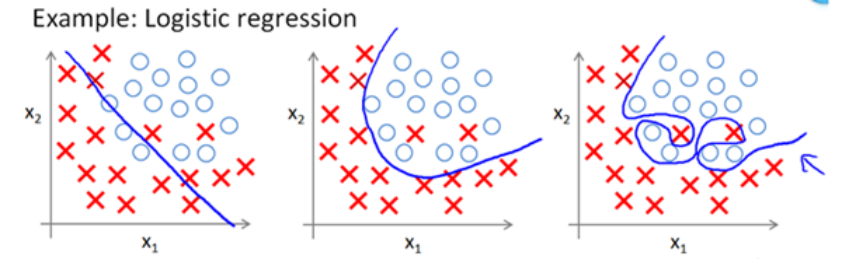
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?
今日推荐
Google发布Gemini 2.0 Pro:MMLU Pro评测超过DeepSeek V3略低于DeepSeek R1,最高上下文长度支持200万tokens!开发者每天免费50次请求!
重磅!OpenAI发布最强推理模型“OpenAI o1”(代号草莓),大模型逻辑推理能力大幅提升,官方宣称超越部分人类博士水平!
准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志
OpenAI的推理大模型o1模型的强有力竞争者!DeepSeekAI发布DeepSeek-R1-Lite-Preview~实测结果令人惊喜!
Let's Encrypt的Certbot自动生成证书和自动更新证书
OpenAI最新的GPT-4V的多模态API接口是如何计算tokens的?这些计算逻辑背后透露了GPT-4V什么样的模型架构信息?