
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



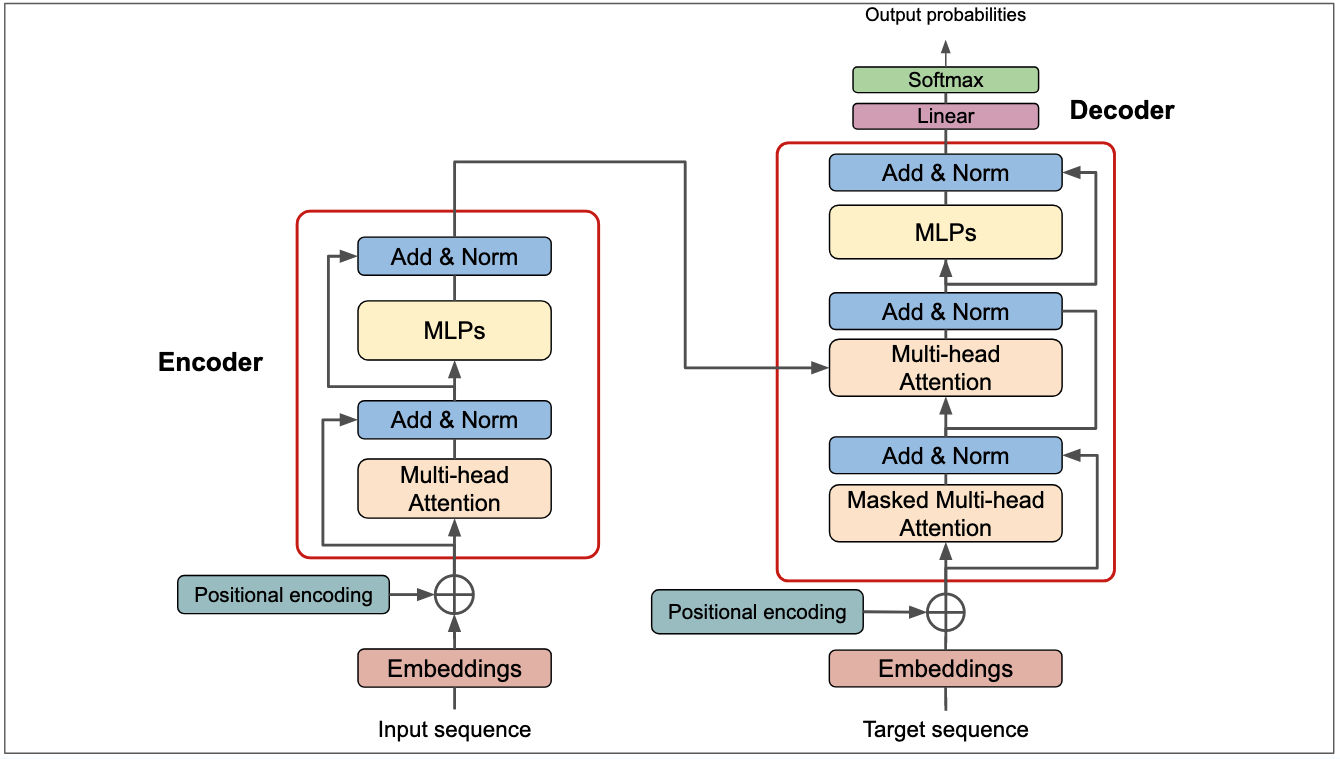
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。
今日推荐
自然语言处理中常见的字节编码对(Byte-Pair Encoding,BPE)简介
大语言模型的技术总结系列一:RNN与Transformer架构的区别以及为什么Transformer更好
Anthropic发布新一代Claude 3.5模型:全新的Haiku 3.5和升级版Sonnet 3.5
没有显卡也没关系!基于Google Colab免费GPU额度部署Stable Diffusion XL模型,可以生成4K的图!
20条关于DeepSeek的FAQ解释DeepSeek发布了什么样的模型?为什么大家如此关注这些发布的模型?他们真的绕过CUDA限制,打破了Nvidia的护城河了吗?
如何提高大模型在超长上下文的表现?Claude实验表明加一句prompt立即提升效果~