
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



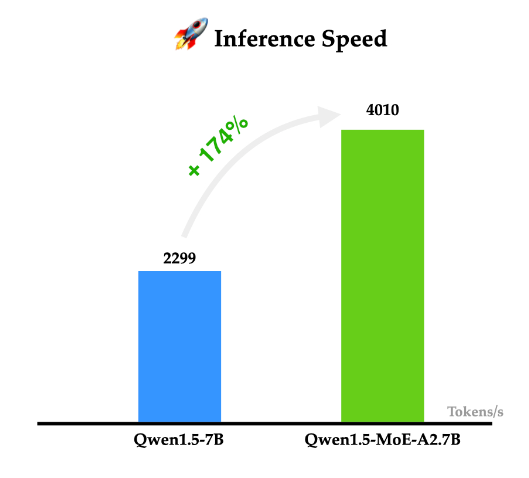
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
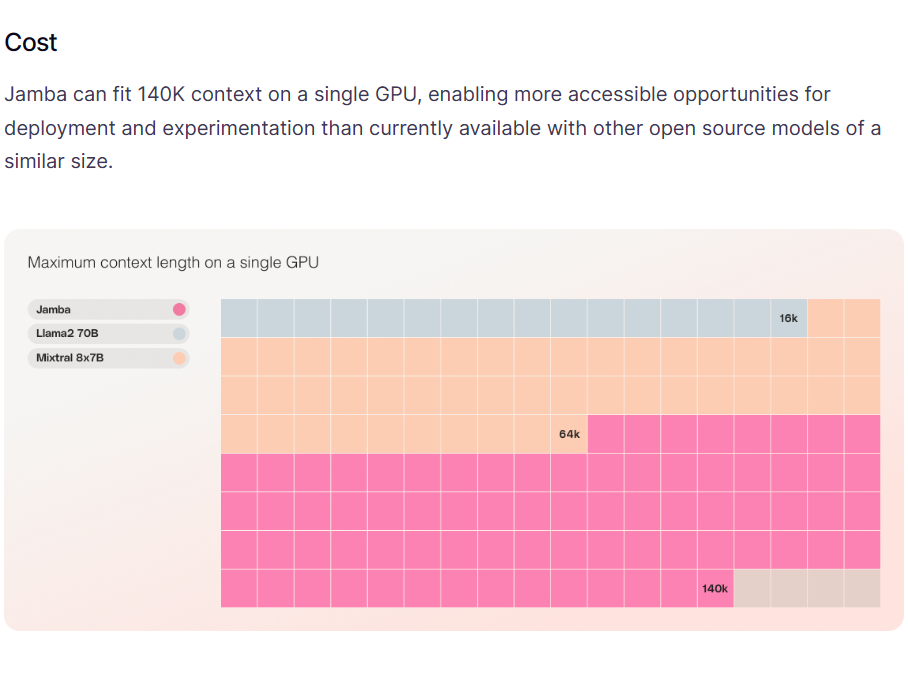
A21实验室是一家以色列的大模型研究机构,专门从事自然语言处理相关的研究。就在今天,A21实验室开源了一个全新的基于混合专家的的大语言模型Jamba,这个MoE模型可以在单个GPU上支持最高140K上下文的输入,非常具有吸引力。
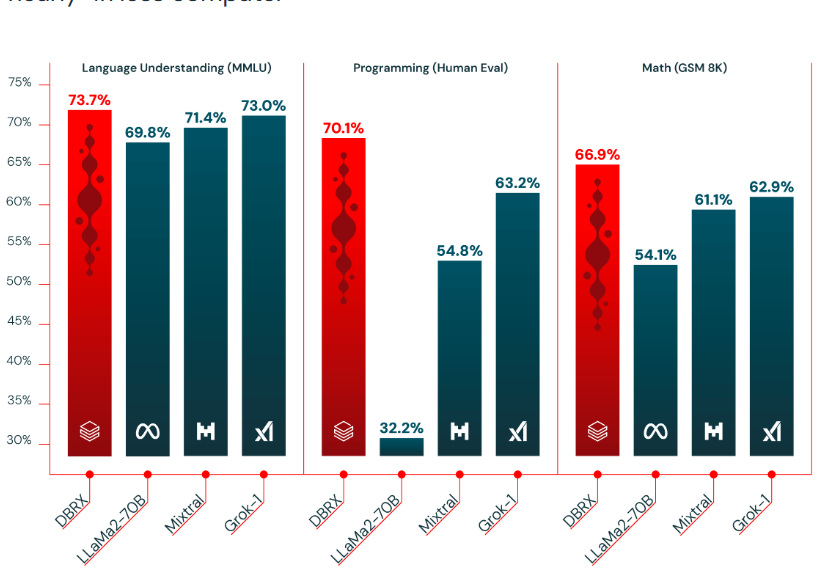
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。
今日推荐
OpenAI的推理大模型o1模型的强有力竞争者!DeepSeekAI发布DeepSeek-R1-Lite-Preview~实测结果令人惊喜!
大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
Python入门的基本概念之包管理——pip与conda的简介对比
“GPT”的模型太多无法选择?让大模型帮你选择大模型!浙江大学发布HuggingGPT!
ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
开源领域大语言模型再上台阶:Databricks开源1320亿参数规模的混合专家大语言模型DBRX-16×12B,评测表现超过Mixtral-8×7B-MoE,免费商用授权!