
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



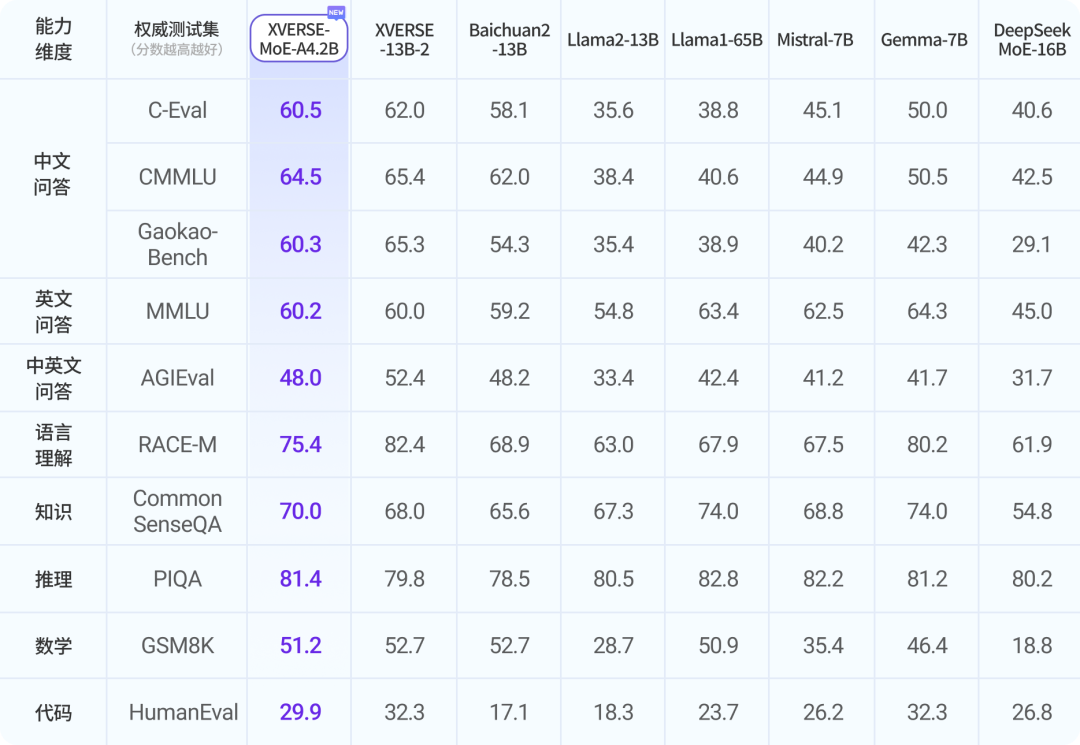
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
今日推荐
最新发布!基于推文(tweet)训练的NLP的Python库TweetNLP发布了!
吴恩达AI系列短课再添精品课程:如何基于LangChain使用LLM构建私有数据的问答系统和聊天机器人
大模型领域的GGML是什么?GGML格式的大模型文件与原有文件有什么不同?它是谁提出的?如何使用?
Mistral AI开源全新的120亿参数的Mistral NeMo模型,Mistral 7B模型的继任者!完全免费开源!中文能力大幅增强!
总结一下截止2023年中旬全球主要厂商拥有的GPU数量以及训练GPT-3/LLaMA2所需要的GPU数量
吴恩达联合OpenAI推出免费的面向开发者的ChatGPT Prompt工程课程——ChatGPT Prompt Engineering for Developers