
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 **提示缓存(Prompt Caching)** 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结
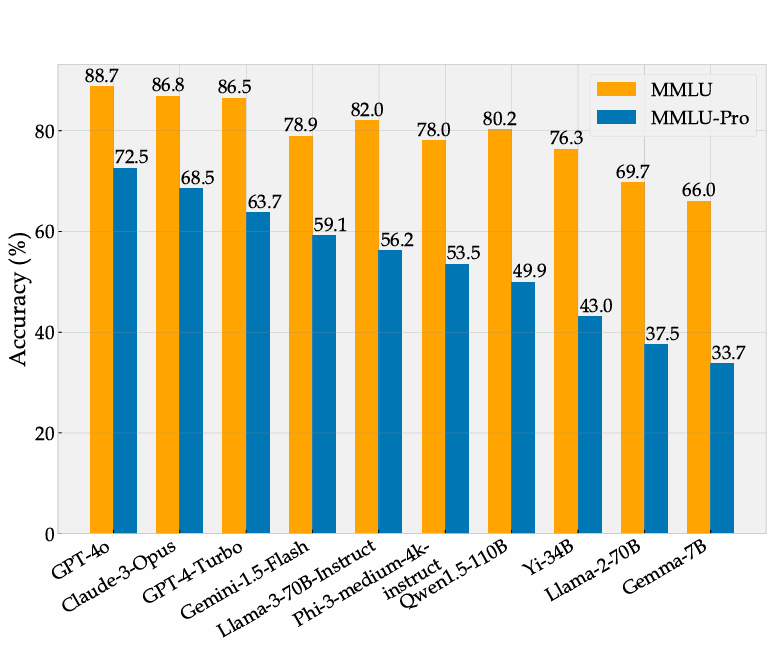
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。 以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。 为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU P
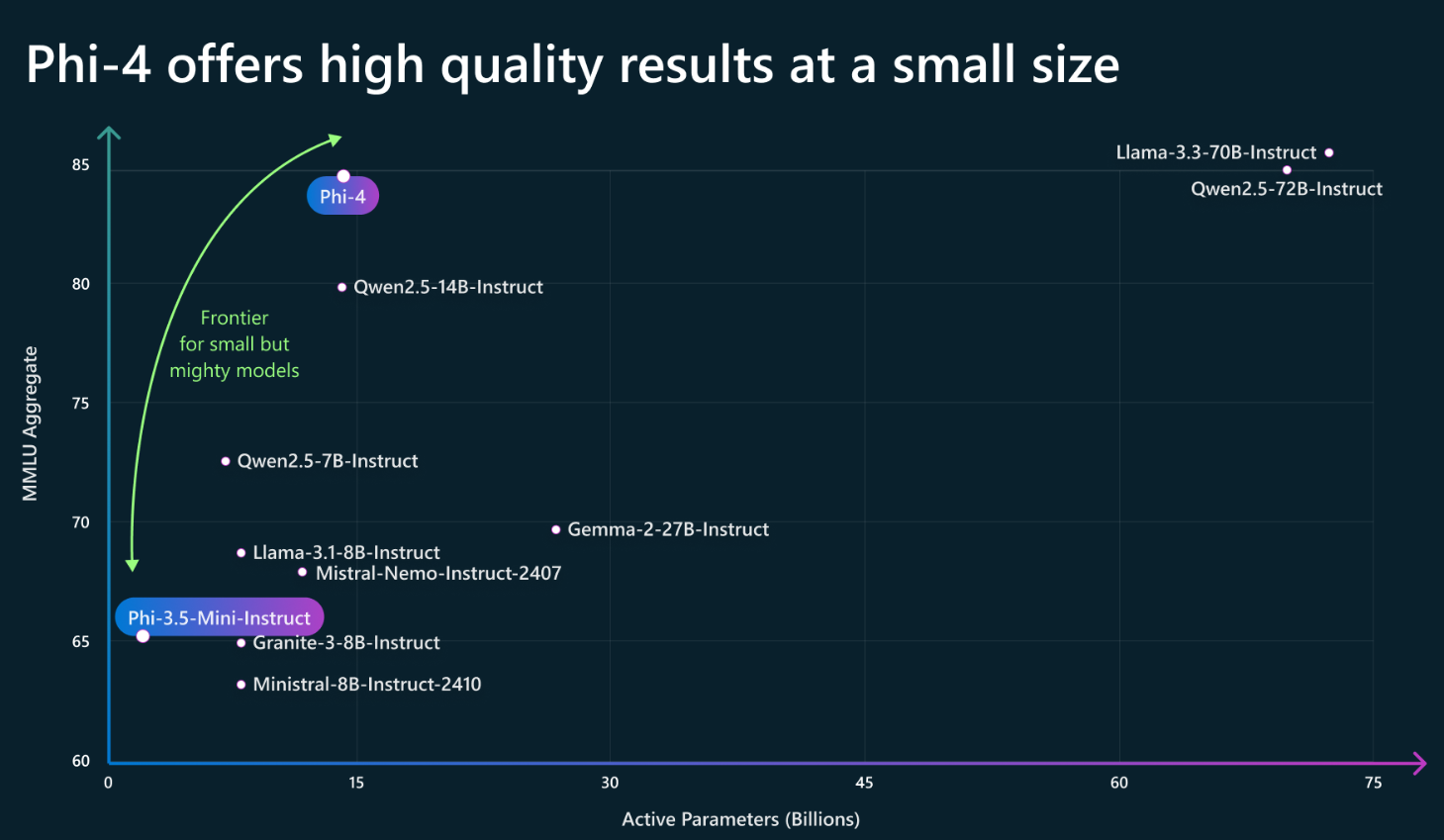
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。

Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。
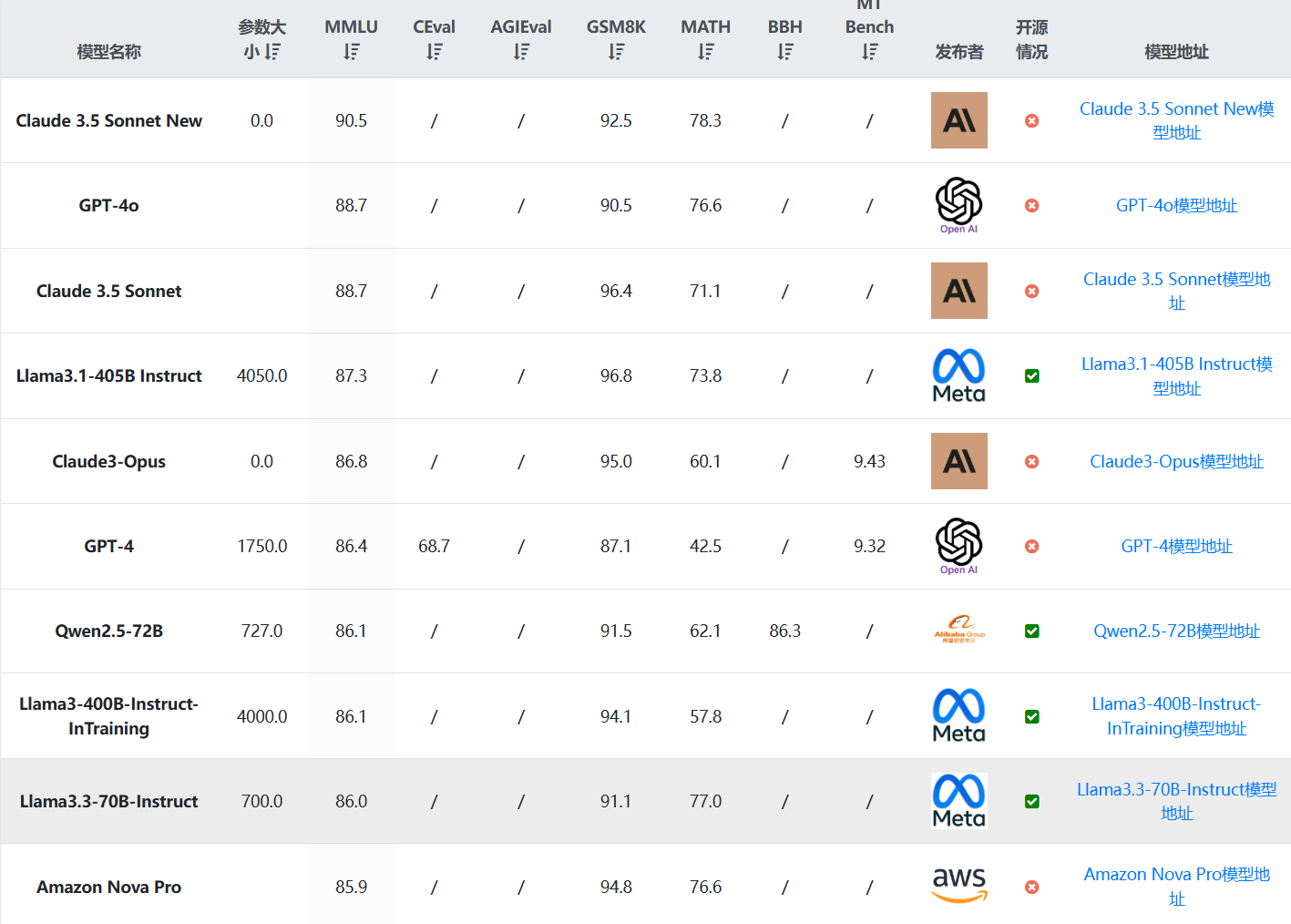
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。
几个小时前,OpenAI开启了今年密集的产品发布时间,本次发布会持续12天,直播12天。几个小时前,第一个发布的产品宣布,那就是OpenAI o1模型的正式版。同时也开启了一个全新的ChatGPT付费计划,即ChatGPT Pro,每个月200美元,可以不限量使用所有模型。本文详细介绍OpenAI o1模型。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!

随着OpenAI发布推理大模型o1,专注于推理能力的大模型开始被广泛关注。基于思维链探索的推理大模型也不断涌现。此前,DeepSeekAI与上海人工智能实验室都发布过推理大模型,也展现了很不错的推理能力,虽然DeepSeekAI官方承诺该模型会开源,但是目前还没有发布。今天,阿里开源了一个全新的推理大模型QwQ-32B-Preview,其推理能力在评测结果上超过o1-mini,是目前开源领域最强的推理大模型(也可能是目前唯一)。

最初,大模型的应用主要通过像ChatGPT这样的聊天机器人展现其智能理解能力。随着技术的进步,基于大模型的智能代理(AI Agent)成为突破大模型能力边界的重要方向。这些智能代理能够执行一系列任务、解决问题,并进行决策,具备深刻理解用户需求和自主规划解决方案的能力,并能够根据规划结果,选择和使用各种工具来完成任务。然而,AI Agent系统面临的关键挑战是如何高效地将外部工具、知识、资源等迅速接入大模型,并实现有效利用。尤其是,如何将现有的工具和资源整合进大模型,提升其生产力能力,是一个亟待解决的问题。
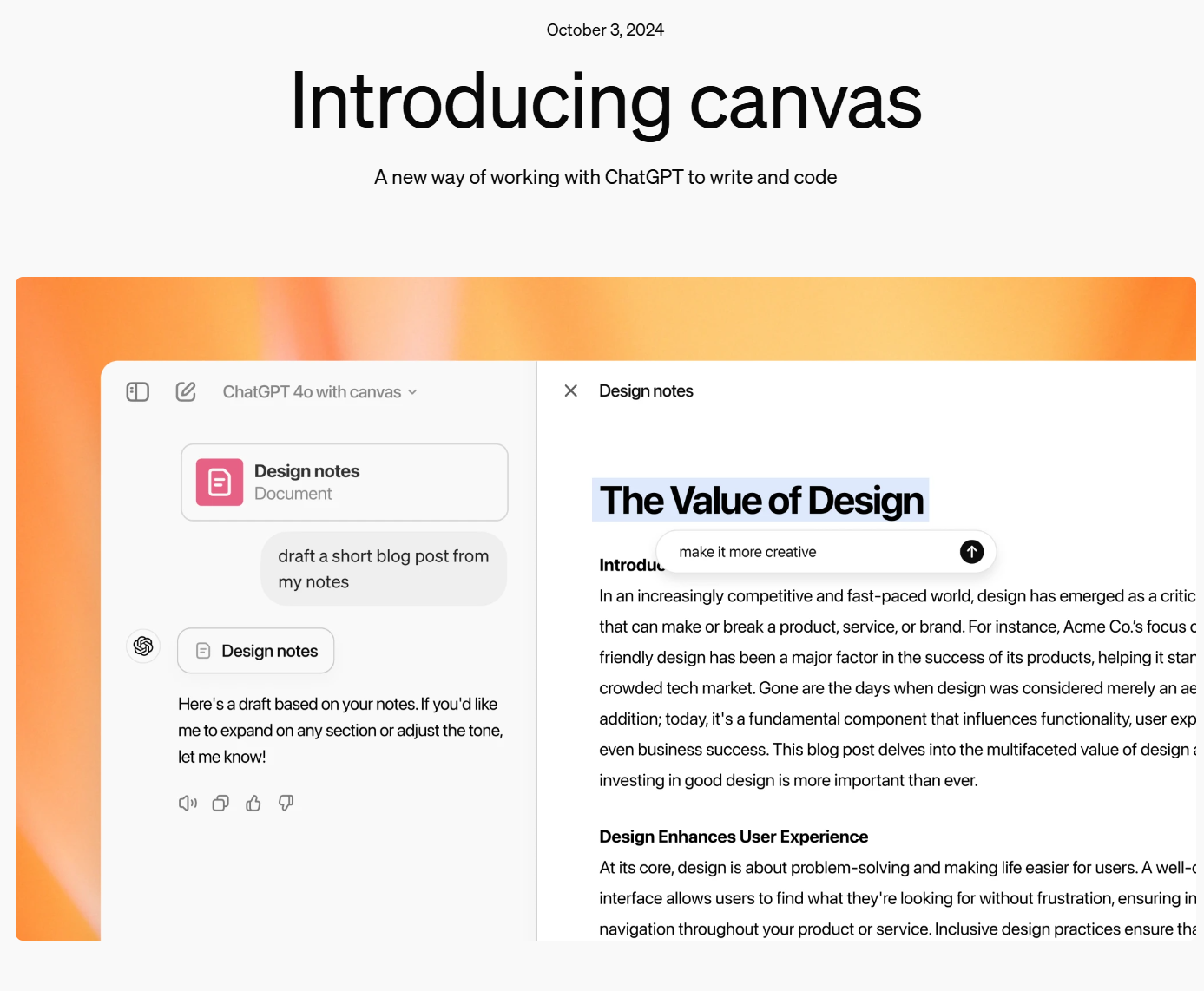
在写作和编程中,使用 ChatGPT 帮助用户处理各种复杂任务已变得越来越普遍。然而,这个过程中仍然存在一些挑战,比如上下文追踪不够连贯、实时反馈不足,以及在编程时难以精确地处理错误或优化代码。为此,OpenAI发布了一个新的特新:Canvas,它是为了解决上述问题而设计的一个全新工具,集成了写作、编程和实时协作的功能。

2024年10月22日,Anthropic发布了两个新模型:升级版的Claude 3.5 Sonnet和全新的Claude 3.5 Haiku。升级版的Claude 3.5 Sonnet在保持原有价格和速度的基础上,实现了全面性能提升,尤其在编码领域取得了显著进步。新推出的Claude 3.5 Haiku则以与Claude 3 Haiku相同的成本和类似的速度,在多个评测中达到了与Claude 3 Opus相当的性能水平。

OpenAI的o1模型是当前最强大的具有超强推理能力的大语言模型。但是,o1模型本身的能力如何,o1版本和o1-mini版本模型的差异在哪等似乎都很不清晰。为此,OpenAI在Twitter上举办了一次AMA(Ask me anything)活动,解答了很多大家关心的问题。在这篇博客中,我们根据这个讨论结果总结了一下其中比较重要的信息供大家参考。
OpenAI发布了一个全新的针对逻辑推理优化的大语言模型o1模型。官方宣称其推理能力相比较当前的大语言模型(GPT-4o)有了大幅提升。OpenAI宣称o1模型在编程竞赛问题(Codeforces)中排名第89百分位,在美国数学奥林匹克(AIME)的资格赛中位列美国前500名,并且在物理、 生物和化学问题的基准测试(GPQA)上超越了人类博士水平的准确率。

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!

Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!
今日推荐
UWMadison前统计学教授详解大模型训练最重要的方法RLHF,RLHF原理、LLaMA2的RLHF详解以及RLHF替代方法
国产全球最长上下文大语言模型开源:XVERSE-13B-256K,一次支持25万字输入,免费商用授权~
华为大模型生态重要一步!PyTorch最新2.1版本宣布支持华为昇腾芯片(HUAWEI Ascend)
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!