
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
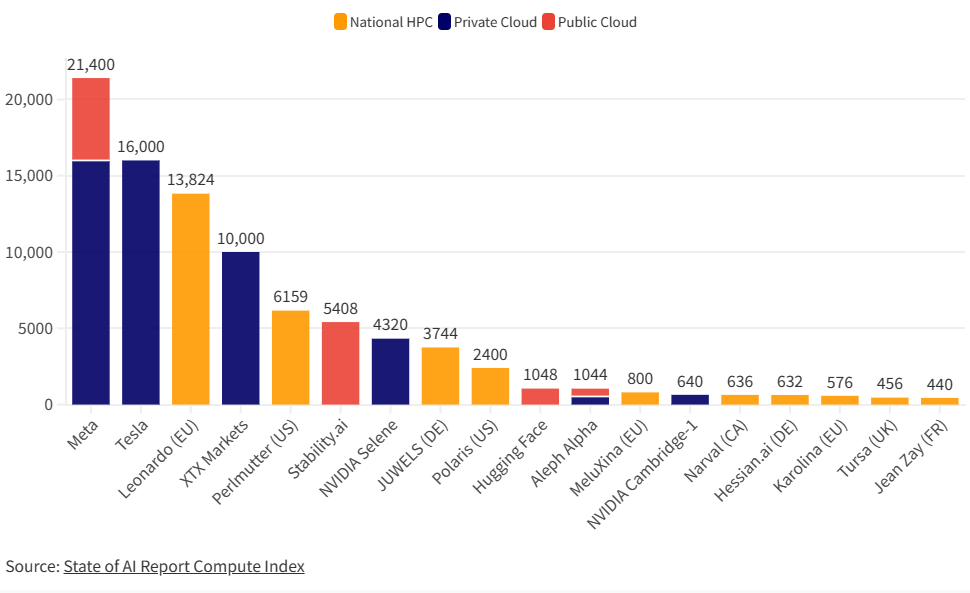
在高性能计算(HPC)、人工智能(AI)、和数据分析等领域,图形处理器(GPUs)正在发挥越来越重要的作用。其中,NVIDIA的 A100尤为引人注目。这是英伟达最强大的显卡处理器,也是当前使用最广泛大模型训练用的显卡。本文主要是各大企业最新的2023年9月份拥有的显卡数量统计。
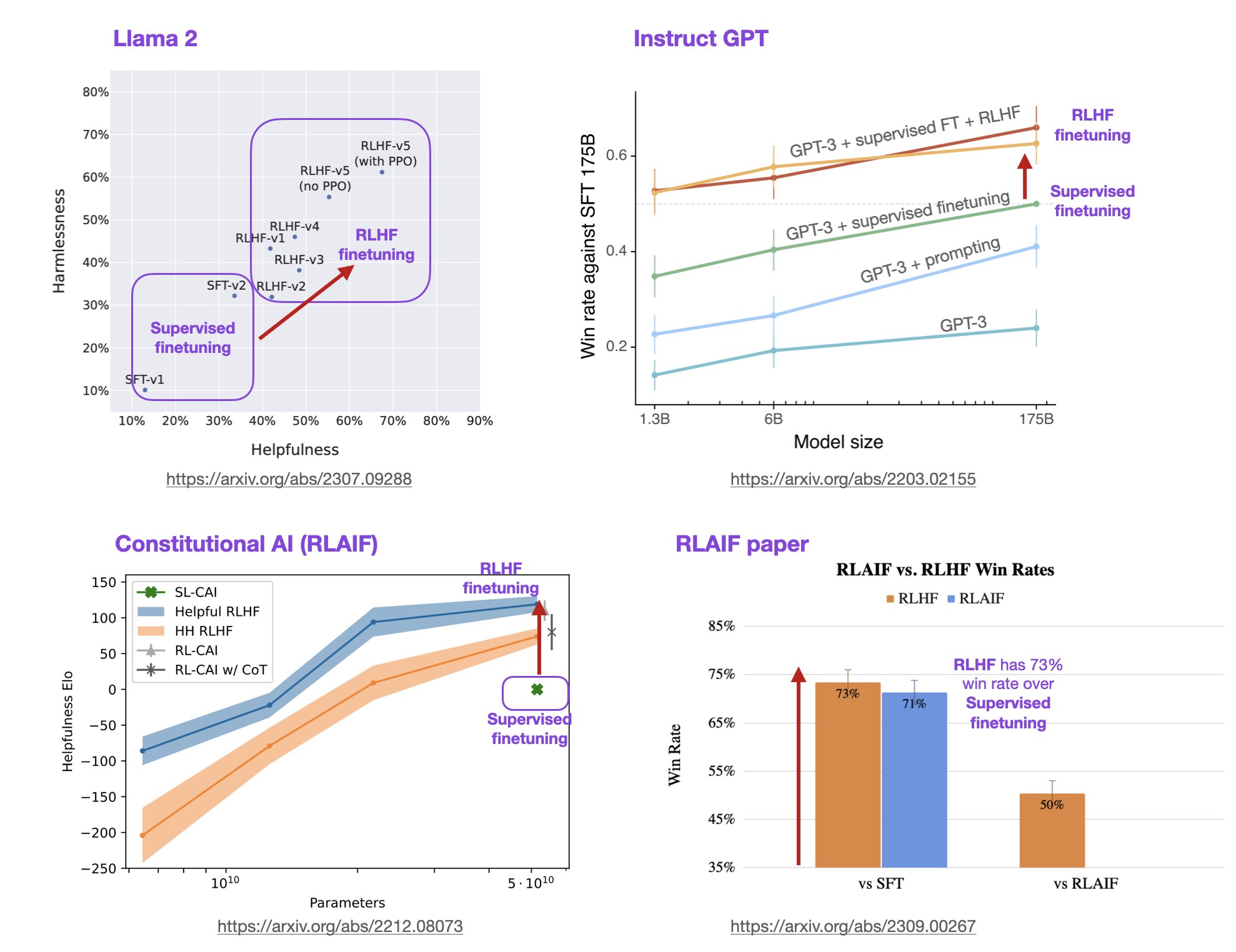
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
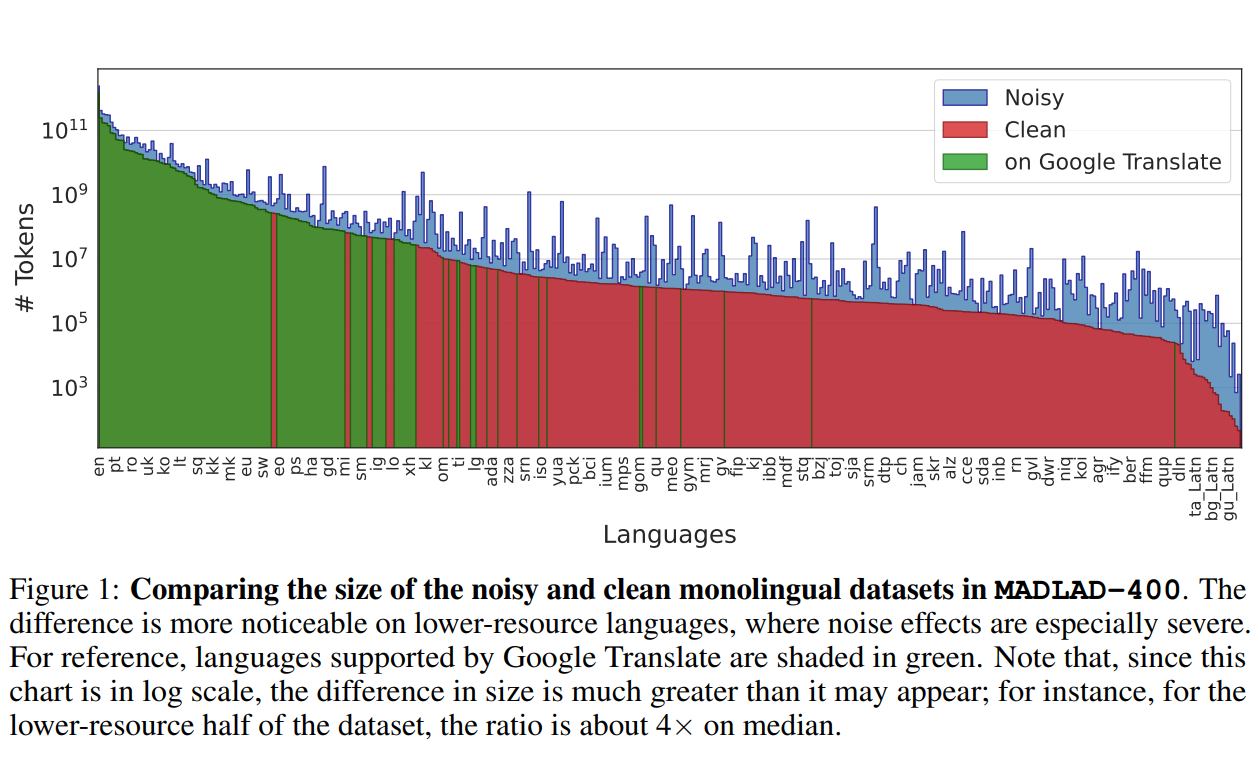
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。

随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型推理速度提升4倍!
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
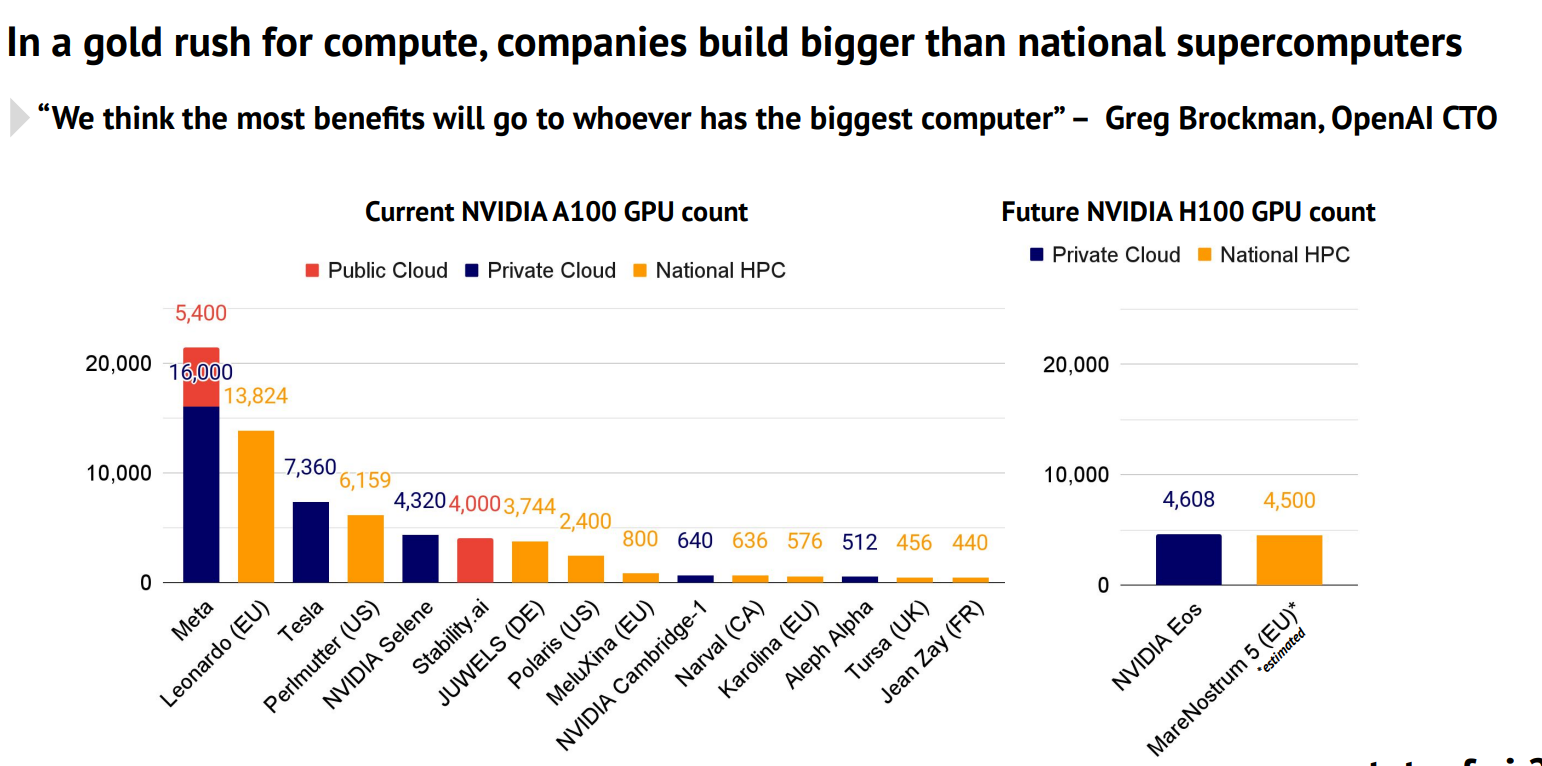
Stateof.AI上周发布了最新的AI的报告中报告了当前各大企业和机构拥有的NVIDIA A100的GPU数量。A100是目前商用的最强大的GPU,对于超级计算机、大规模AI模型的训练和推理来说都十分重要。这里透露的各大企业的GPU数量也让我们可以看到各家的竞争情况。
Anthropic公司宣布,其开发的智能助手Claude推出收费订阅服务,命名为Claude Pro,定价20美元一个月(或者18英镑)。免费用户依然可以使用,但是有发送频率限制。本篇博客将解释一下ClaudeAI的Claude服务是否收费以及收费之后的ClaudePro提供的服务等。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

Prompt技巧一直是提升ChatGPT等大语言模型使用效率的最重要方法之一。为此,OpenAI官方也在不断地分享官方的Prompt技巧。2023年的8月31日,OpenAI官方最新分享了一个教室使用的Prompt来帮助老师授课的案例。尽管这是针对老师的Prompt教程,但是其中的设计思路其实也可以广泛运用在客服、问答系统、编程等领域。

MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。
OpenAI发布了ChatGPT的企业版,这是一个专为企业设计的聊天机器人。这个版本不仅提供了企业级的安全和隐私保护,还具有更高的处理速度和更多的自定义选项。相比较个人版的ChatGPT,企业版主要是提升了性能、强调了安全等。

当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。

大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。