
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



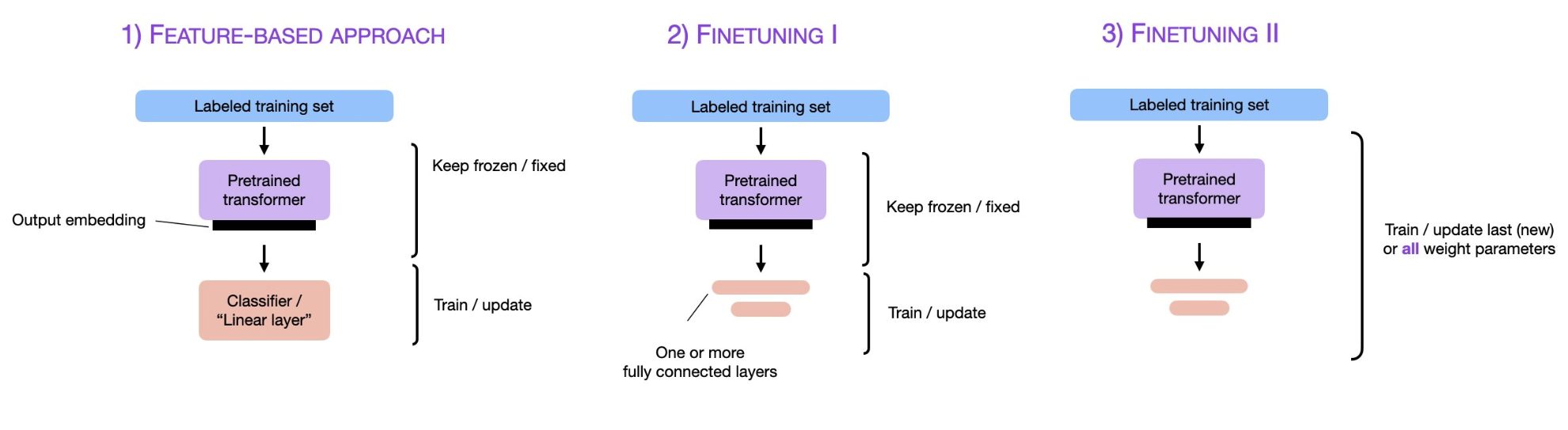
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。

OpenAI Startup Fund是OpenAI和微软等合作伙伴在2022年推出的一个创业基金,收到OpenAI Startup Fund投资的初创企业几乎可以等同于OpenAI认为的未来AI应用重要方向。这些企业不仅可以获得资金支持,还可以比其它企业更早使用OpenAI的模型。本文将简要介绍当前OpenAI已经投资的企业,它们可能是未来AI领域重要的角色!
通过调整提示文本,可以使语言模型更好地理解任务的要求和上下文,从而提高其在特定任务上的表现。Prompt tuning是使大型语言模型更加智能和高效的关键步骤之一。只有通过精心设计和优化提示文本,我们才能充分发挥大型语言模型的潜力,并使其更好地服务于人类的需求。因此,Prompt engineering,这一种新的工程能力也开始变得重要。
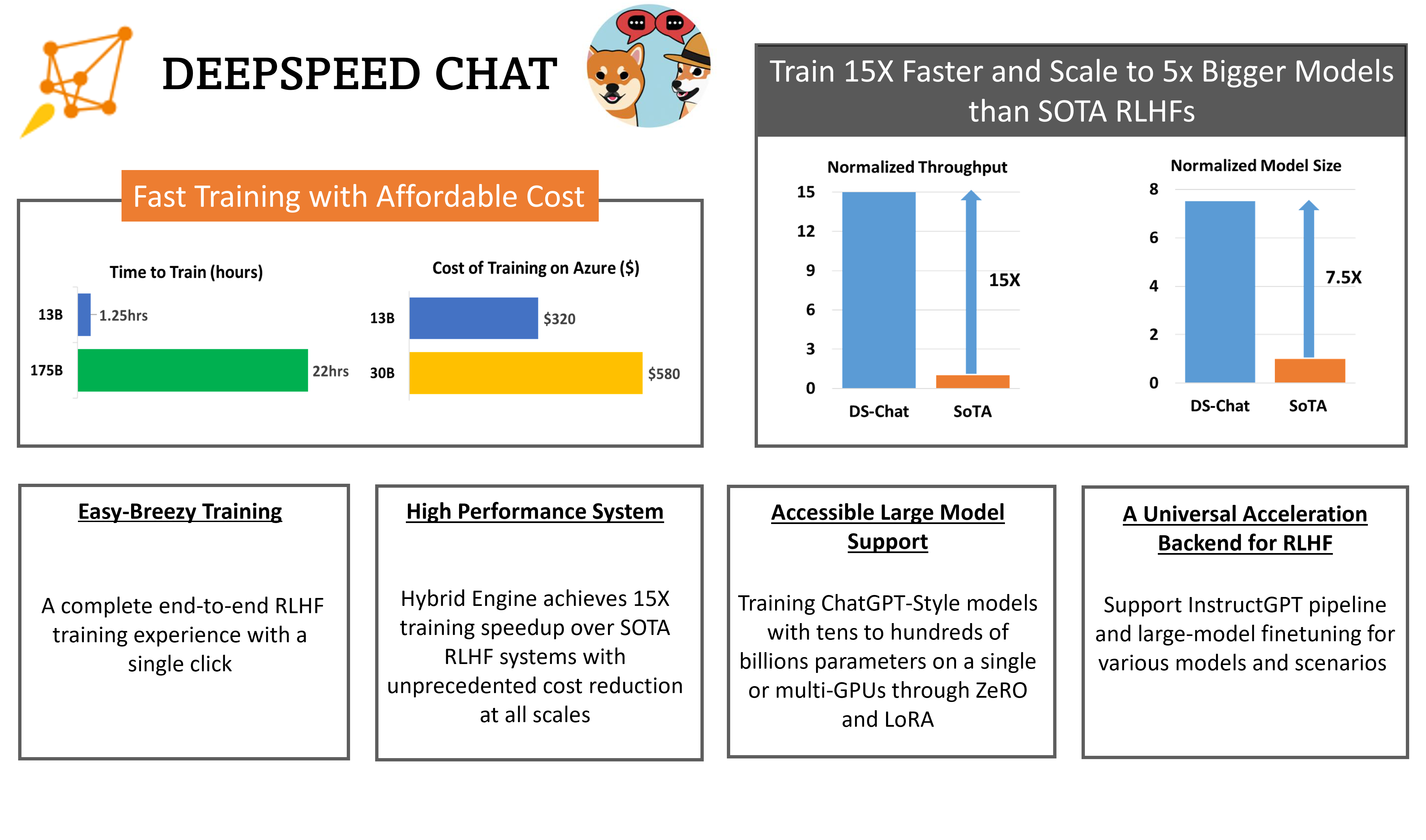
RLHF全称Reinforcement Learning from Human Feedback,是随着ChatGPT火爆之后而被大家所关注的技术。昨天,微软开源了业界第一个RLHF的pipeline框架,可以用来训练类似ChatGPT的模型。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
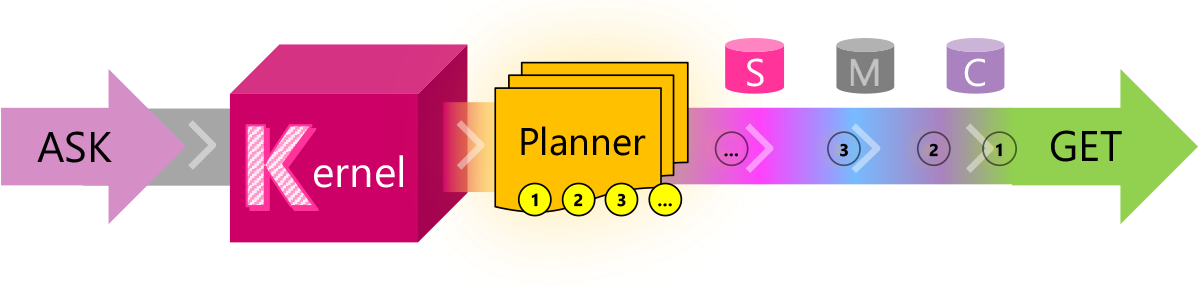
目前的LLM有很多限制,有很多问题并不能很好的解决,例如文本输入长度有限、无法记住很早之前的信息等。而这些问题目前也都缺少合适的解决方案。它们所依赖的技术:如任务规划、提示模板、向量化内存等需要的是编程的智慧。Semantic Kernel就是微软在这个背景下推出的一个结合LLM与传统编程技术的编程框架。

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。
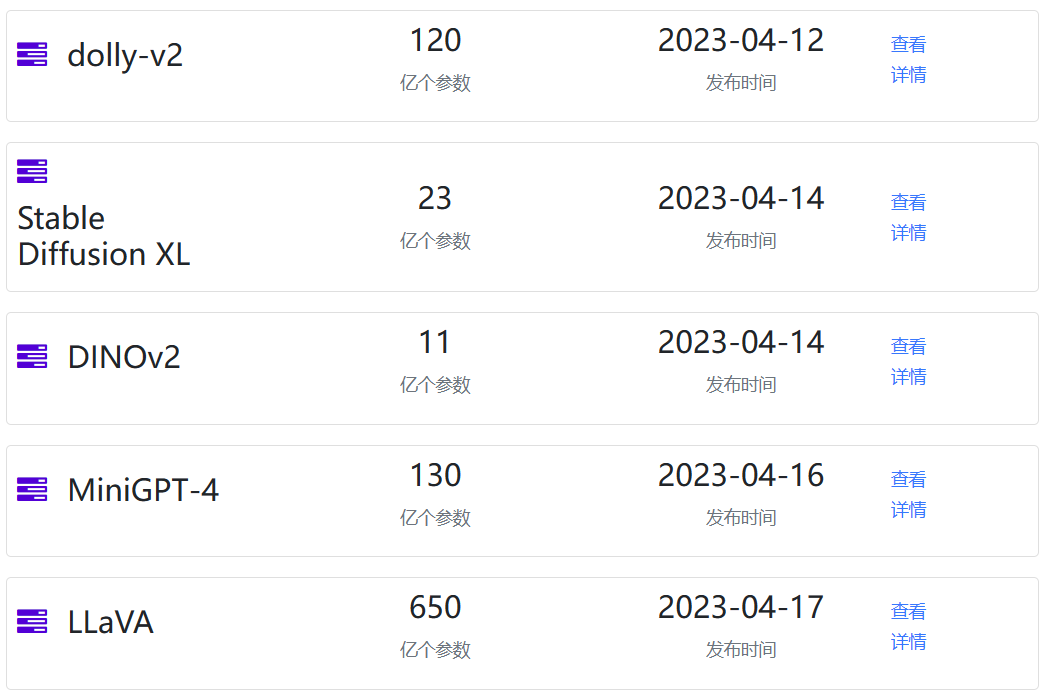
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。
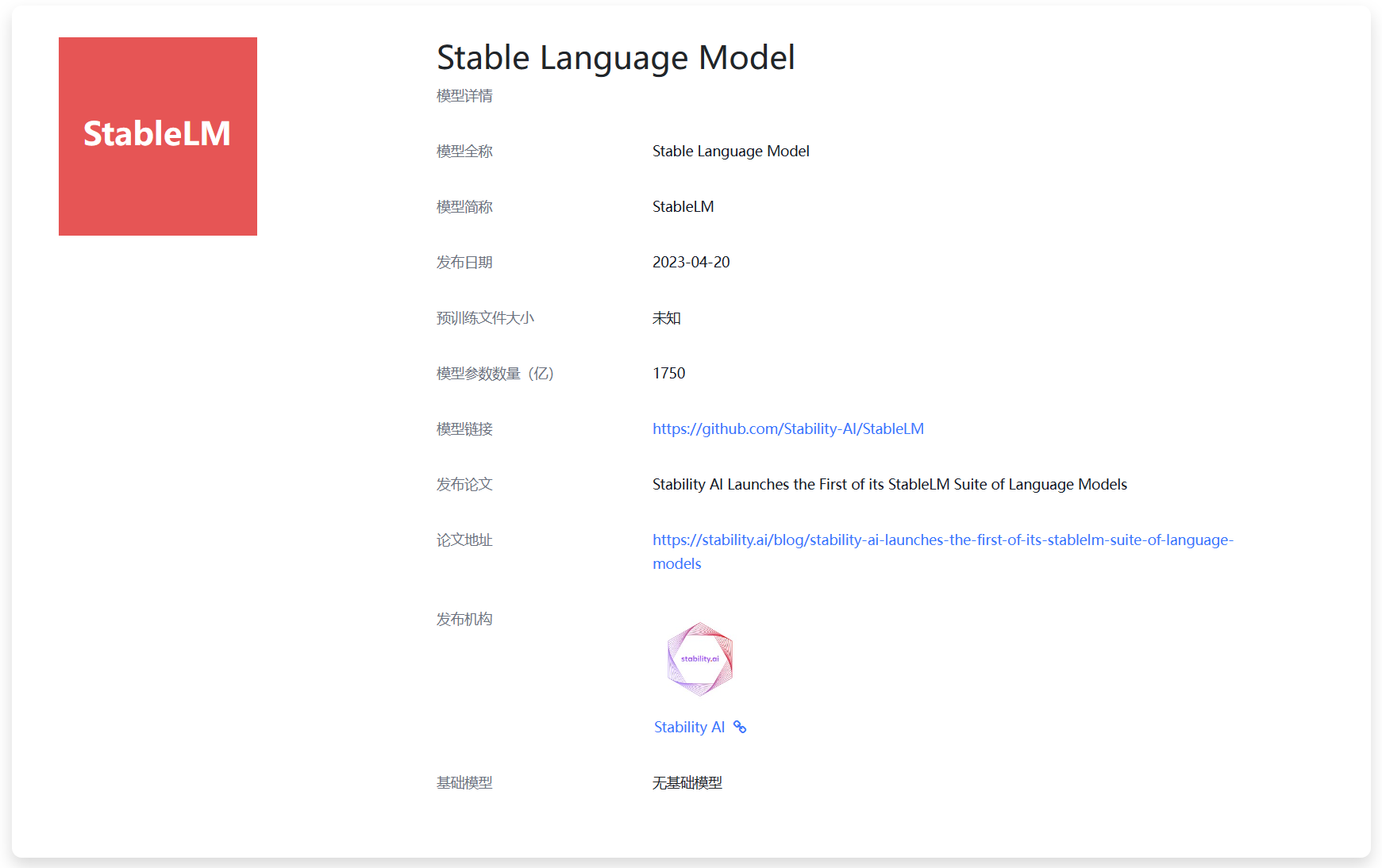
今天,Stability宣布开源StableLM计划,这是一个正在开发过程的大语言模型,但是它是开源可商用的模型。本文将对该模型做简单的介绍!

本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。
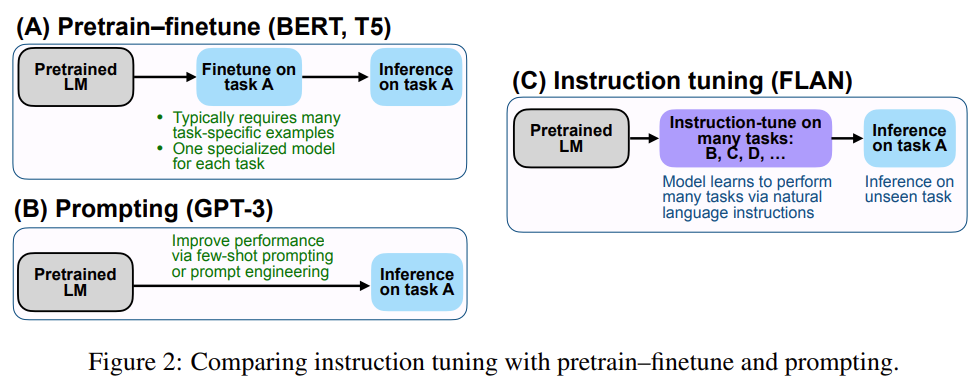
Prompt-Tuning、Instruction-Tuning和Chain-of-Thought是近几年十分流行的大模型训练技术,本文主要介绍这三种技术及其差别。
随着ChatGPT的火爆,Prompts概念开始被大家所熟知。早期类似如BERT模型的微调都是通过有监督学习的方式进行。但是随着模型越来越大,冻结大部分参数,根据下游任务做微调对模型的影响越来越小。大家开始发现,让下游任务适应预训练模型的训练结果有更好的性能。而ChatGPT的火爆让大家知道,虽然ChatGPT的能力很强,但是需要很好的提问方式才能让它为你所服务。
万众瞩目的GPT-4即将来临!3月9日晚上在德国举办的一个AI会议。微软德国的员工参与了讨论,在介绍微软云的AI能力的时候,微软德国CTO Andreas Braun透露了GPT-4将在下周发布。
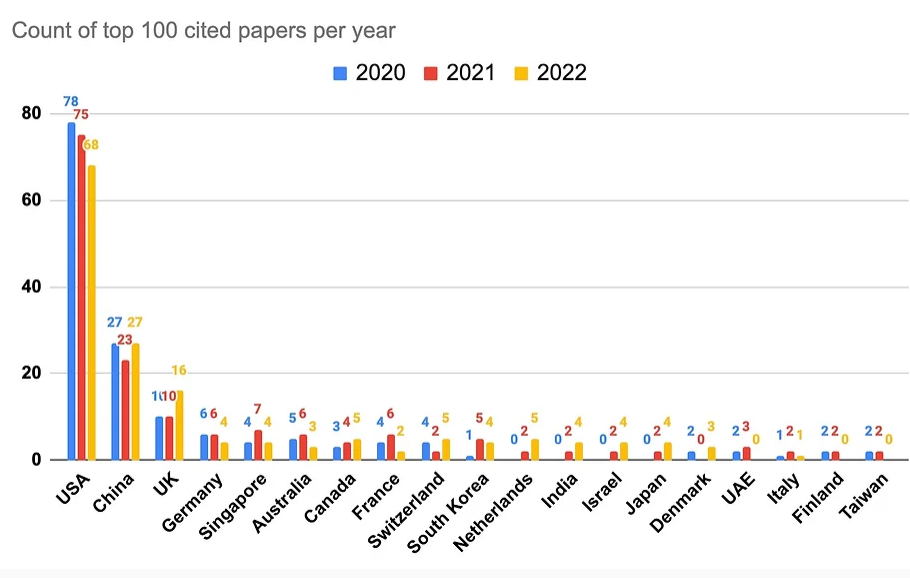
尽管AI领域在工业界发展迅速,企业研究机构在拼命的开发相关的产品以推动各自业务的发展。但是他们也在科研领域不断贡献大量的AI论文。Zeta Alpha的一篇博客分析了2022年发表的被引用最多的100篇AI论文,给大家提供一个洞察思路。
今日推荐
Qwen1.5系列再次更新:阿里巴巴开源320亿参数Qwen1.5-32B模型,评测结果超过Mixtral 8×7B MoE,性价比更高!
Python for Data Analysis第三版免费在线学习网站来临!
OpenAI世界最强的语音识别预训练模型WhisperV2即将来临
最新发布!截止目前最强大的最高支持65k输入的开源可商用AI大模型:MPT-7B!
使用LangChain做大模型开发的一些问题:来自Hacker News的激烈讨论~
支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
如何让大模型(GPT)按照特定的JSON格式输出?OpenAI给出新答案:GPT模型现在可以支持更加友好和精确的格式化JSON输出了!