
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。
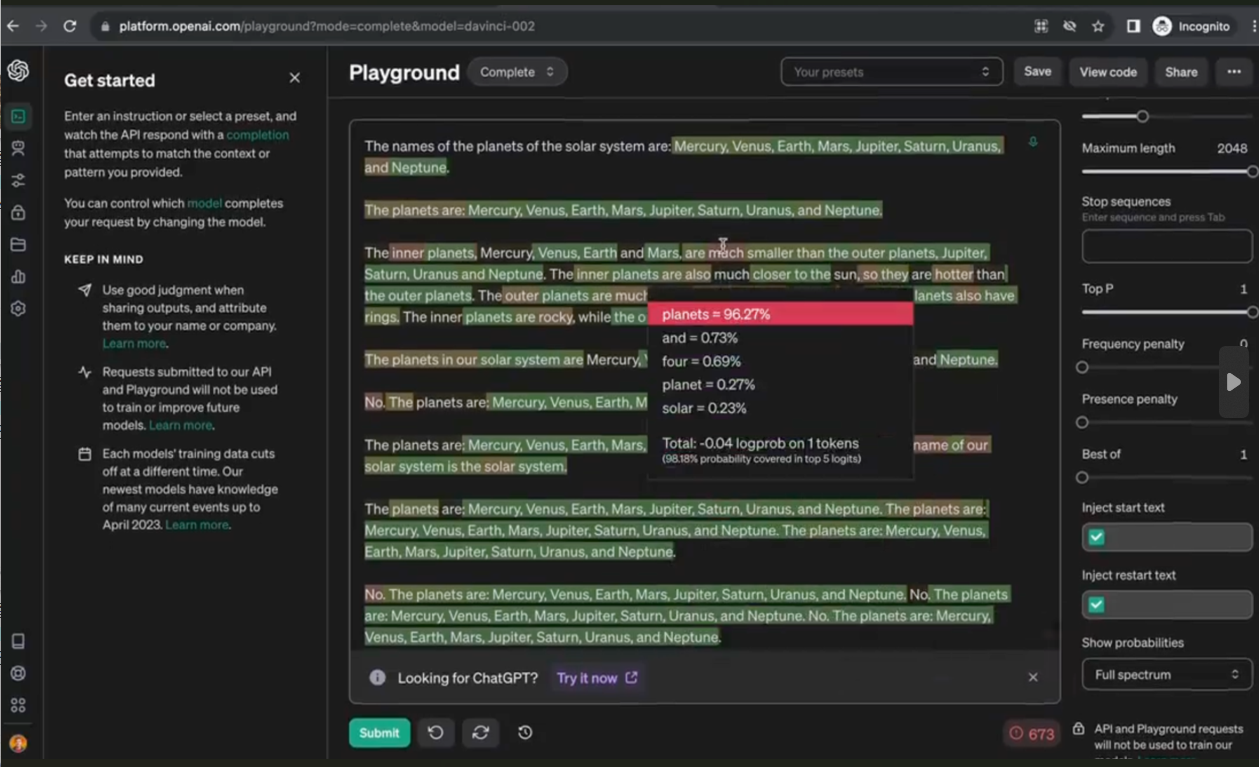
在最新的OpenAI官方接口文档中,新增了top_logprobs和logprobs这2个参数。这2个参数是一起配合使用的。后者是一个布尔类型,表明模型的返回结果中是否增加输出每个token的概率,而top_logprobs参数是一个整数类型,取值范围是0-5之间。如果top_logprobs设置为true,那么模型会根据top_logprobs的设置结果,返回输出结果中每个token及其后续的n个单词的概率。

今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。

网络流传了一张疑似GPT-4.5的定价截图,引爆了很多人的讨论。但是,目前没有人可以确定真假。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。
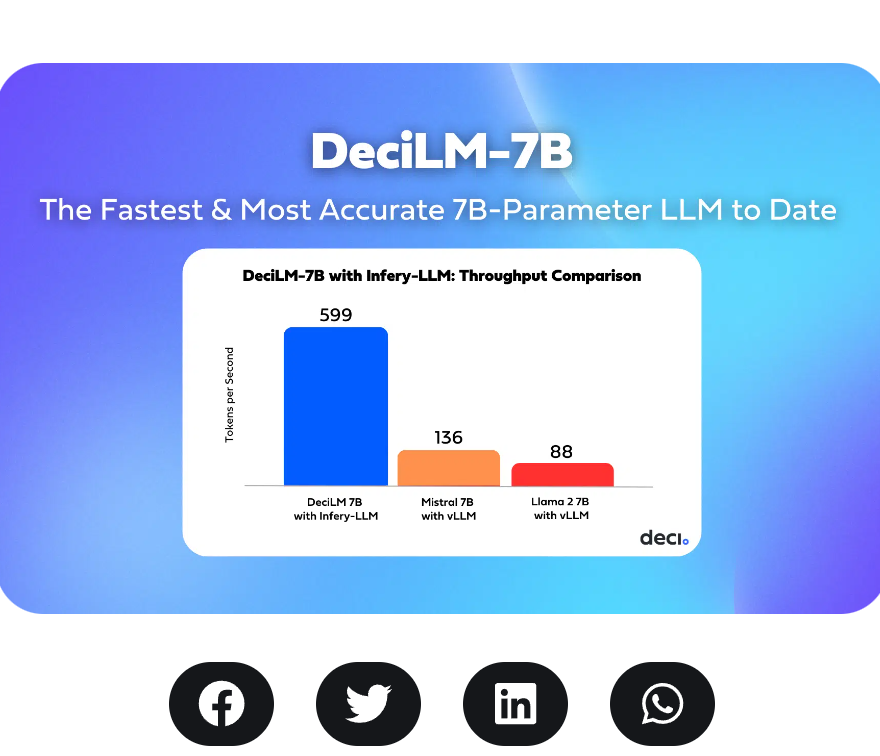
DeciAI是一家成立于2019年的以色列企业,他们最主要的产品是深度学习平台Deci,可以让大家部署运行更快、更准确的模型。包括Adobe、HPE等都是他们的客户。在昨天,他们开源了截止目前可能是Open LLM Leader综合评分最高的大语言模型DeciLM-7B以及指令优化版本的DeciLM-7B-Instruct。最重要的是,这个模型以Apache2.0的协议开源,可以免费商用。

最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。

MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。

OpenAI发布的产品中,有2个产品可以用来将GPT当作一个类似AI Agent工具使用,同时支持接入自定义的接口和数据。那就是GPTs和Assistant API,前者可以在界面直接操作,后者则是一个API,两者功能接近,为了让大家更加清晰理解二者区别,OpenAI官方最近发布了二者的解释。
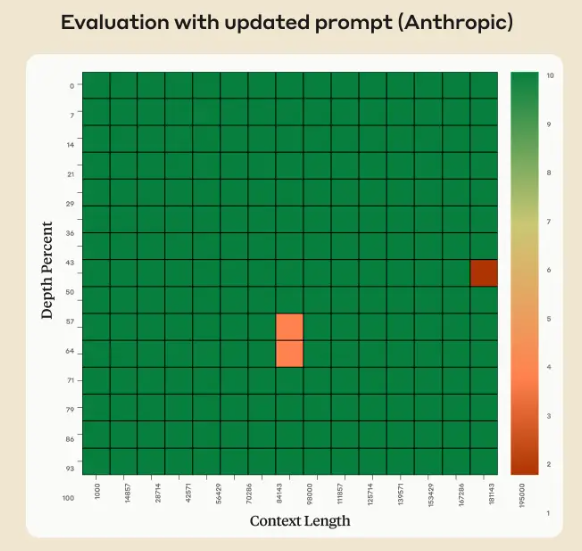
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。
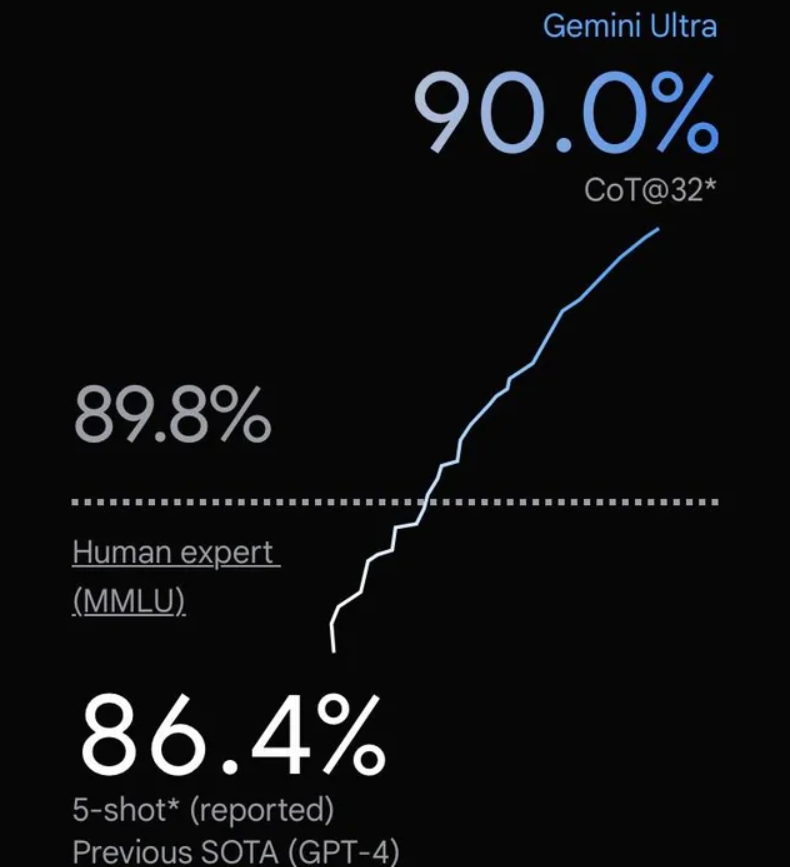
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。