
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




OpenAI在其官方GitHub上公开了一个最新的开源Python库:tiktoken,这个库主要是用力做字节对编码的。相比较HuggingFace的tokenizer,其速度提升了好几倍。

OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。

刚刚,StabilityAI宣布Stable Diffusion2.1发布。距离Stable Diffusion2.0大版本发布刚2个星期,2.1版本就发布了,2.1版本有诸多改进功能。
Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。
12月1日OpenAI官宣了其目前最强的AI对话系统之后,大家发现这个强大的系统能做的事情远超过大家的想象。我们也在第一时间发布了相关的博客:https://datalearner.com/blog/1051669904657253 。由于这个系统实在是太过强大,大家发现的能力越来越强。连Musk也在几个小时之前感叹这个系统是so much better at bullshit than they are!在这篇博客中,我们将收集关于这个系统目前的使用案例,给大家一个更加全面的展示结果。
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT,是基于GPT3.5微调的结果,试用显示效果惊人!
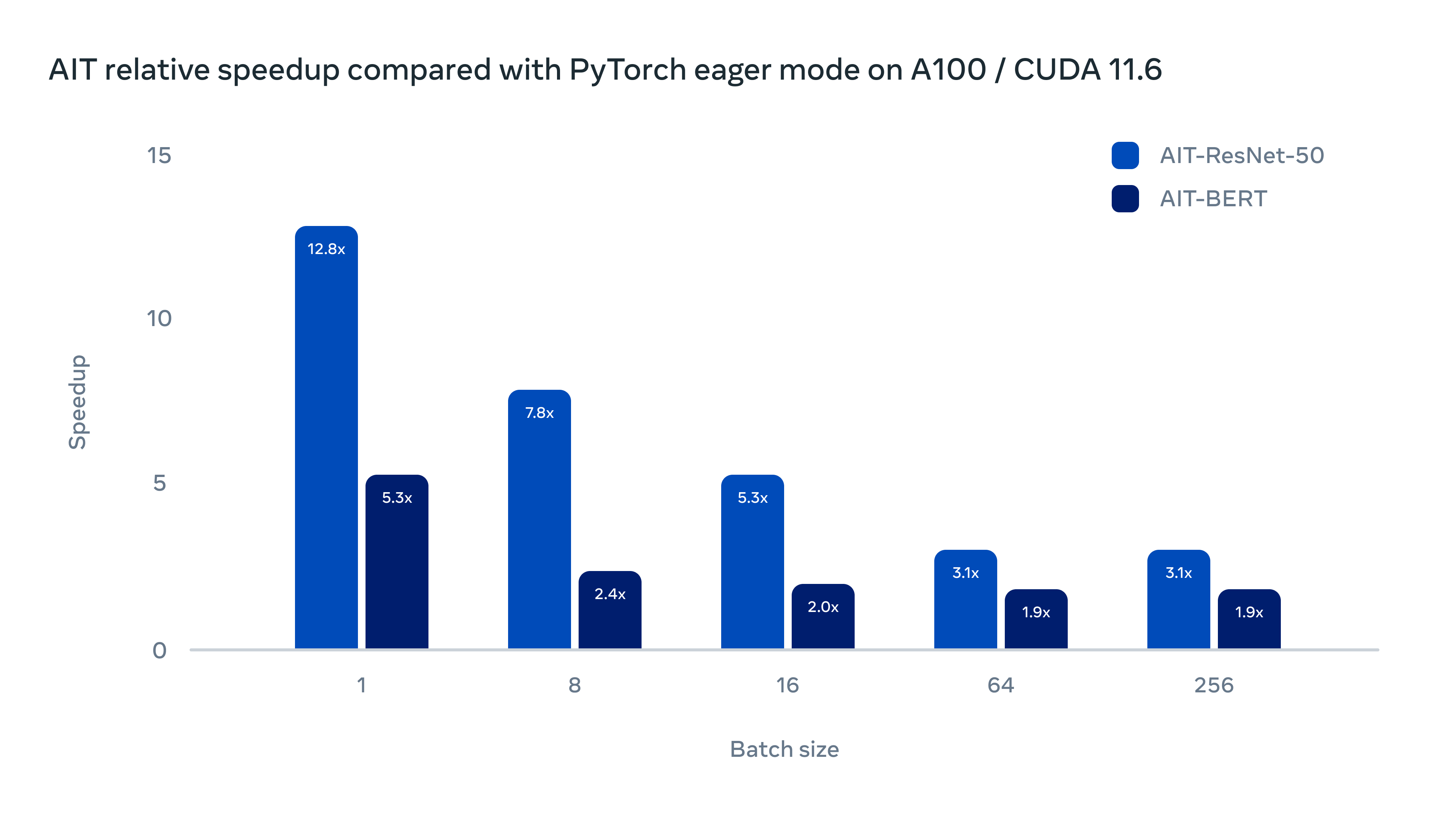
为了提高AI模型的推理速度,降低在不同GPU硬件部署的成本,Meta AI研究人员在昨天发布了一个全新的AI推理引擎AITemplate(AIT),该引擎是一个Python框架,它在各种广泛使用的人工智能模型(如卷积神经网络、变换器和扩散器)上提供接近硬件原生的Tensor Core(英伟达GPU)和Matrix Core(AMD GPU)性能。

九月份刚过去,GitHub上最火的AI研究排序出炉。这是根据9月份GitHub上创建的新的AI研究相关的项目排序,根据Star的数量来的。都是AI各大领域比较受欢迎和重要的项目。

前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
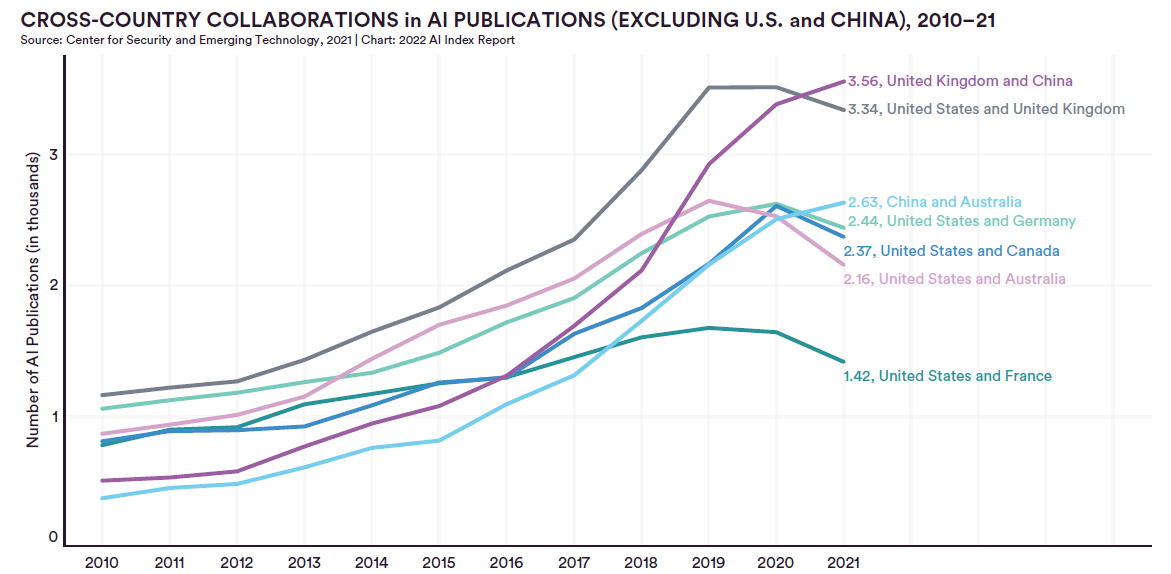
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。

MLPerf™是MLCommons发布的一个用来测试AI相关软硬件性能的基准测试工具。2021年12月1日, Training v1.1的结果发布,这个结果不仅展示了最新的AI相关软硬件的进展,也有一个新的现象,就是AI训练正在超越摩尔定律。本文将简要解读一下相关数据。
影响者营销将是极好的机会,可以使你的形象更加完善,并接触到新的受众,是一个人性化的宏伟机会?的确如此。它是否充满了影响者和品牌宁愿不管理的问题?同样地,是的。
基于算法的业务或者说AI的应用在这几年发展的很快。但是,在实际应用的场景中,我们经常会遇到一些非常奇怪的偏差现象。例如,Facebook将黑人标记为灵长类动物、城市图像识别系统将公交车上的董明珠形象广告识别为闯红灯的人等。算法系统出现偏差的原因有很多。本篇博客将总结在数据获取相关方面可能导致模型出现偏差的原因。
今日推荐
Google反击OpenAI的大杀器!下一代语言模型PaLM 2:增加模型参数并不是提高大模型唯一的路径!
好消息!吴恩达再发大模型精品课程:Generative AI with Large Language Models,一个面向中级人员的生成式AI课程
比OpenAI原始的Whisper快70倍的开源语音识别模型Whisper JAX发布!
Text-to-Video来临!——Meta AI发布最新的视频生成预训练模型
二叉查找树(Binary Search Trees,BST)数据结构详解
正则化和数据增强对模型的影响并不总是好的:The Effects of Regularization and Data Augmentation are Class Dependent