
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



2025年2月5日,Google官方宣布Gemini 2.0 Pro版本上线,Gemini系列是谷歌最新一代大模型的品牌名称。Google最早在2024年12月中旬发布了Gemini 2.0系列的第一个模型Gemini 2.0 Flash,当时试用的人都普遍反应这个模型速度又快,结果友好,让Google摆脱了此前大模型很落后的印象。今天,Gemini 2.0 Pro上线,其能力更强。

Gemini是谷歌发布的一系列大模型的名称,是谷歌前期大模型Bard产品的替代品。从Gemini 1.0发布开始,每一次发布都获得了不错的反响。今天,Google发布了最新一代的Gemini 2.0模型,首个产品是其参数规模较小的Gemini 2.0 Flash,它的推理速度是Gemini 1.5 Pro的2倍,但是各项评测结果上的表现却超过了Gemini 1.5 Pro。该模型完全免费提供给大家使用。

在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!
Gemini是谷歌发布的一系列大语言模型。最早是2023年12月发布1.0版本,在2023年2月中旬,劈柴哥亲自宣布Gemini Pro升级到1.5版本。Gemini 1.5 Pro是一个全新的MoE模型(Mixture of Experts,混合专家),在各项评测结果中都接近Gemini Ultra 1.0的水平。而在今天,Gemini Pro 1.5再次迎来重大更新,包括音频理解、无限制文件阅读以及更好地指令遵从性等。本文将介绍这次更新,并做一些简单的实际测试。

Gemma系列是谷歌开源的与Gemini同源的小规模参数版本的大语言模型,此前只有70亿参数和20亿参数的Gemma大语言模型。而现在,Google又开源了2个系列的新的大模型:一个是编程大模型CodeGemma系列,一个是基于RNN架构新型大模型RecurrentGemma。

Google Gemini是谷歌最新推出的和OpenAI竞争的大语言模型。尽管Gemini褒贬不一,但是Gemini模型的影响力是巨大的。而现在更加令人激动的是谷歌开源了2个新的不同参数规模的模型,分别是Gemma 7B和Gemma 2B,其技术与Gemini模型一致。但是这两个开源模型完全公开,可以商用授权。
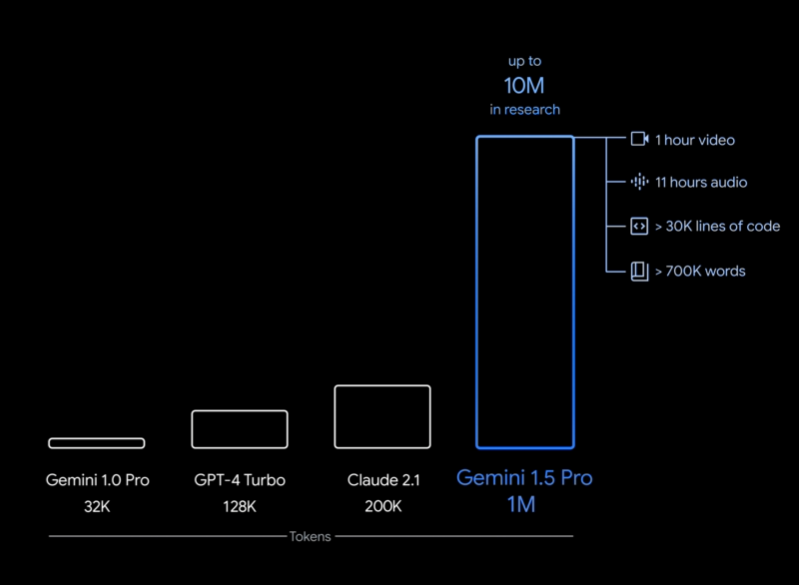
在2023年12月份,Google发布了Gemini系列大模型(参考:谷歌发布号称超过GPT-4V的大模型Gemini:4个版本,最大的Gemini的MMLU得分90.04,首次超过90的大模型),包含3个不同参数规模的版本。其中,Gemini Ultra号称在MMLU评测上超过了GPT-4,并且在月初也将Bard更名为Gemini,开放了Gemini Ultra的付费使用。刚刚,Google的CEO劈柴哥宣布发布了Gemini 1.5 Pro,这意味着仅仅一个半月,Gemini有了重大更新。

决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。今天,OpenAI宣布了他们第三代向量大模型text-embedding,模型能力增强的同时价格下降!

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。
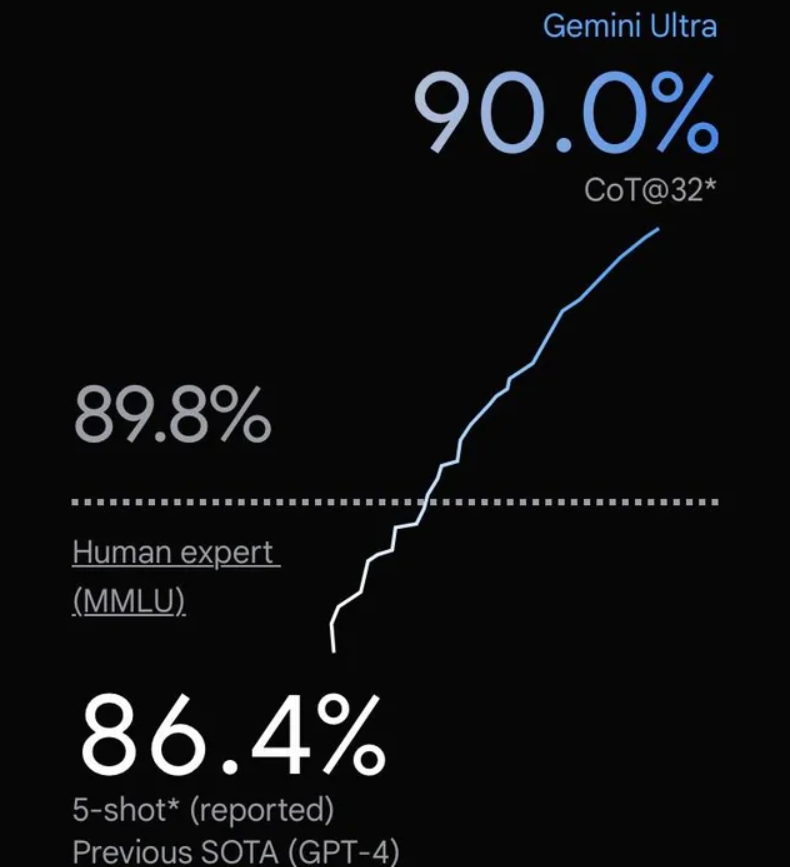
谷歌在几个小时前发布了Gemini大模型,号称历史最强的大模型。这是一系列的多模态的大模型,在各项评分中超过了GPT-4V,可能是目前最强的模型。

The Information最新消息透露OpenAI正在抓紧准备GPT-4多模态版本的发布,可能称为GPT4-Vision。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。
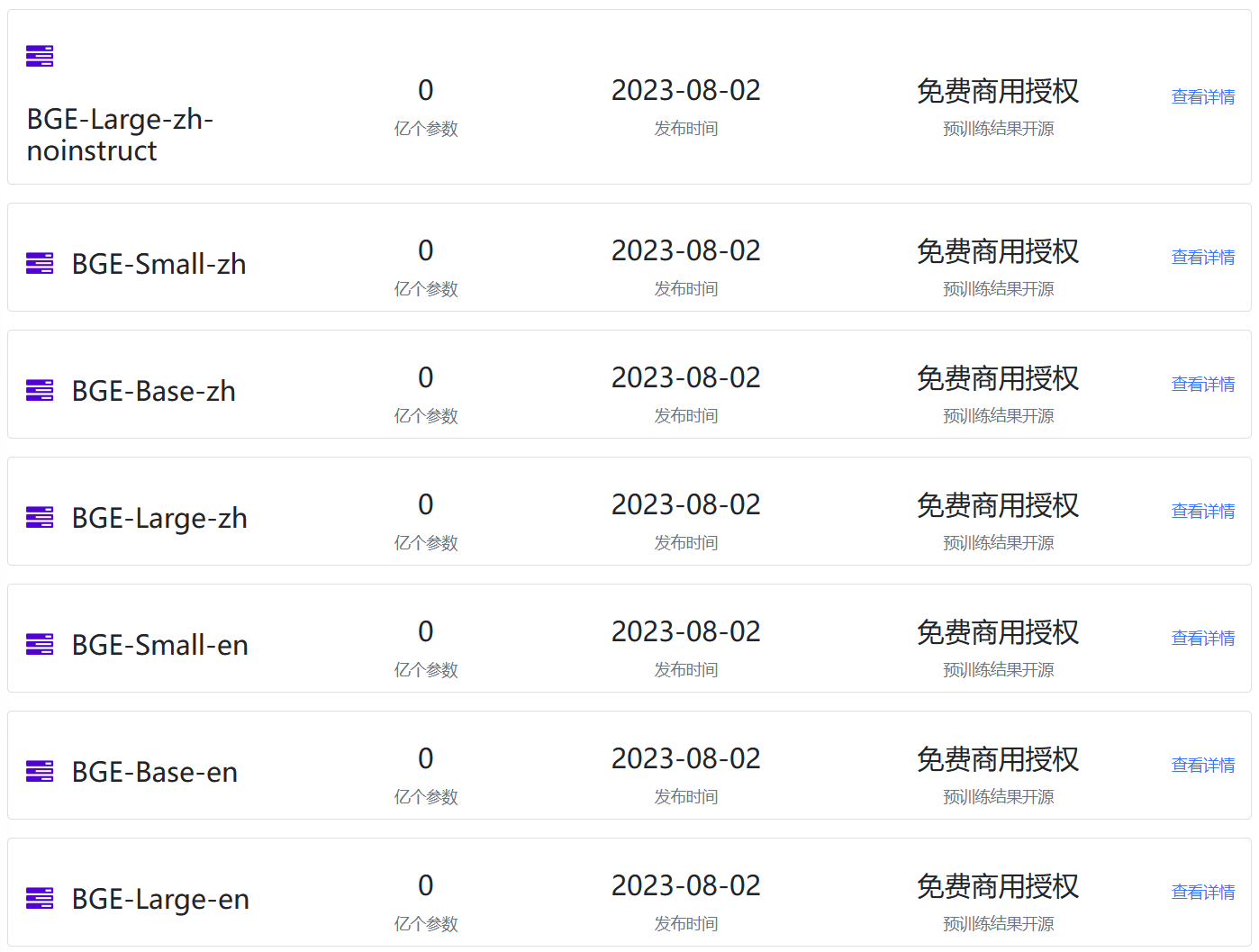
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。

文本embedding是当前大模型应用中一个十分重要的角色。在长上下文支持、私有数据问答等方面有非常重要的应用。但是相比较开源领域快速发布的大模型节奏,开源的embedding模型和数据却非常少。今天,GPT4All宣布在其软件中增加embedding的支持,这是一个完全免费且可商用的产品,最重要的是可以在我们本地用CPU来做推理。
今日推荐
AI2发布全新的大语言模型预训练数据集:包含3万亿tokens的大规模文本数据集AI2 Dolma,开源免费商用数据集~
重磅!OpenAI发布GPT-4o mini,这是GPT-3.5的替代升级版,价格下降60%,但是更快更强!编程能力甚至超过GPT-4!
推荐一个国内可以按分钟计费的4090显卡租用公有云,一个小时24GB显存的4090只需要2.37元——仙宫云
支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
开源领域大语言模型再上台阶:Databricks开源1320亿参数规模的混合专家大语言模型DBRX-16×12B,评测表现超过Mixtral-8×7B-MoE,免费商用授权!
国产全球最长上下文大语言模型开源:XVERSE-13B-256K,一次支持25万字输入,免费商用授权~
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
重磅!来自Google内部AI研究人员的焦虑:We Have No Moat And neither does OpenAI