
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
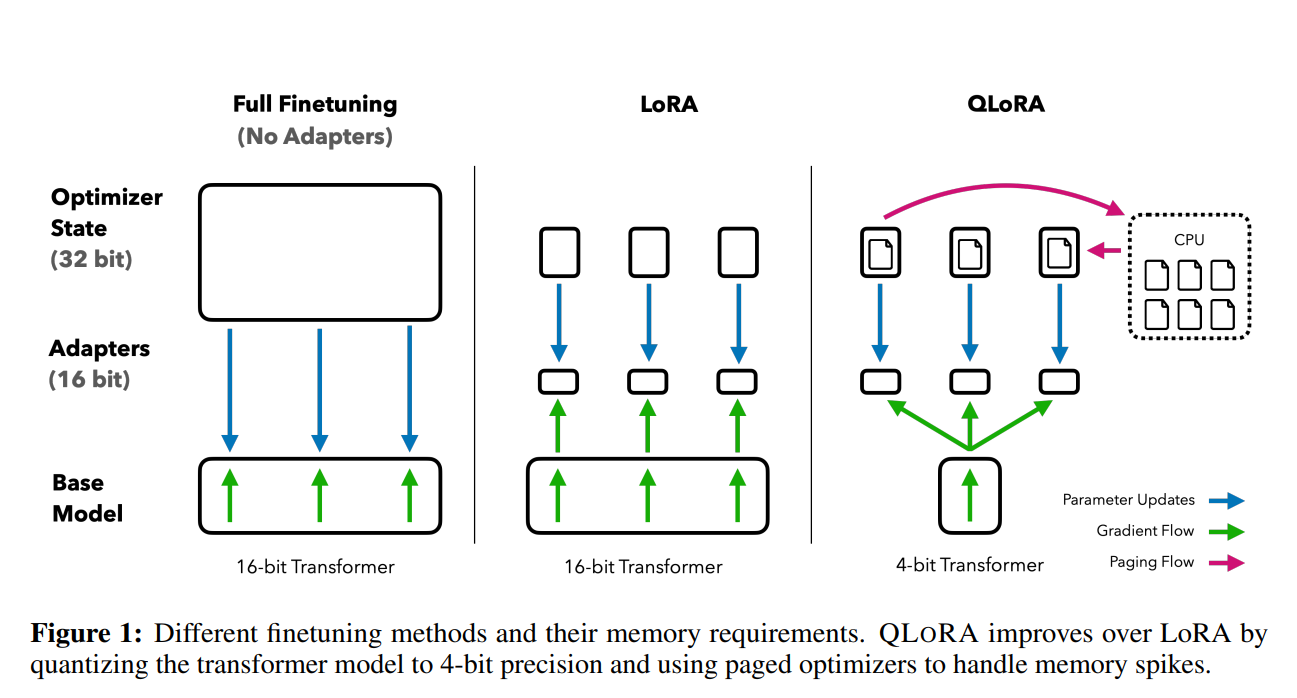
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
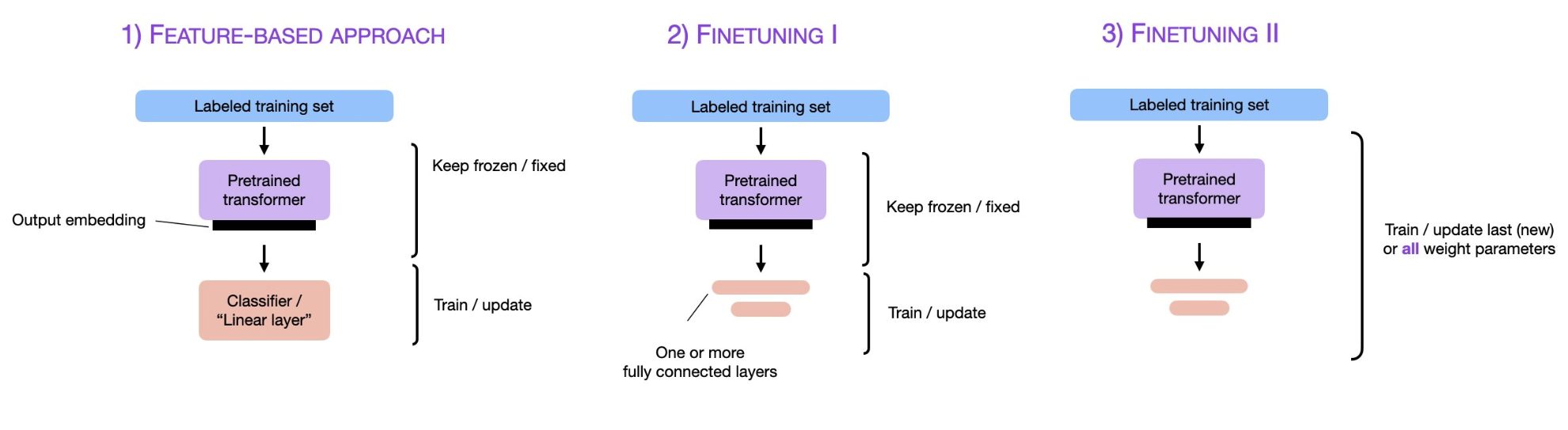
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
今日推荐
Google开源CodeGemma编程大模型和RNN架构大模型RecurrentGemma,同等参数规模最强编程大模型以及更快的大模型
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
如何提高大模型在超长上下文的表现?Claude实验表明加一句prompt立即提升效果~
OpenAI最新动向,Sam不再回归OpenAI,与Greg一起进入微软!OpenAI新任CEO由Emmett Shear接任!
开源可商用大模型再添重磅玩家——StabilityAI发布开源大语言模型StableLM
Llama3相比较前两代的模型(Llama1和Llama2)有哪些升级?几张图简单总结Llama3的训练成本、训练时间、模型架构升级等情况
新产品越来越近!OpenAI可能会推出全球最强个人助手Jarvis个人助理工具:OpenAI新商标Voice Engine透露出OpenAI正在做的事情!