
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



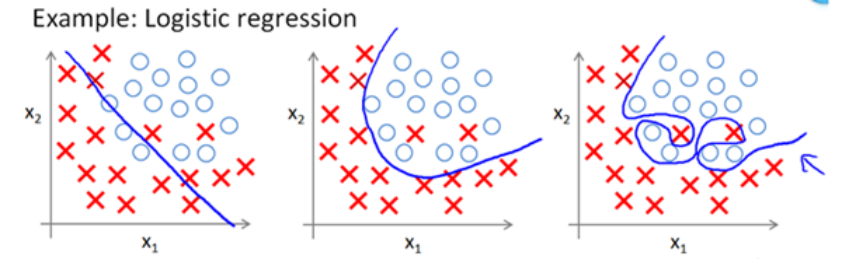
在我们给推荐问题建模时,神秘的正则化项L0、L1、L2的选择对模型很重要。为什么要加正则化?正则化有哪几种形式?到底该选择哪种正则化来建模呢?正则化项与推荐问题的关系?