
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



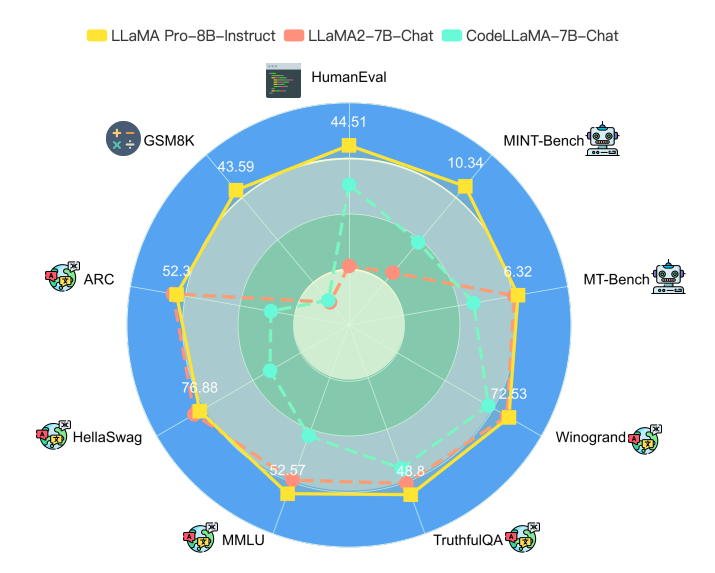
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。
今日推荐
GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!
MistralAI的混合专家大模型Mistral-7B×8-MoE详细介绍,效果超过LLaMA2-70B和GPT-3.5,推理速度快6倍
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
大模型领域最著名开源模型小羊驼Vicuna升级!Vicuna发布1.5版本,可以免费商用了!最高支持16K上下文!
传闻OpenAI内部大模型推理能力获得进展,Q*项目进化成Strawberry!并且距离发布时间更近了!
AI2发布全新的大语言模型预训练数据集:包含3万亿tokens的大规模文本数据集AI2 Dolma,开源免费商用数据集~