
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



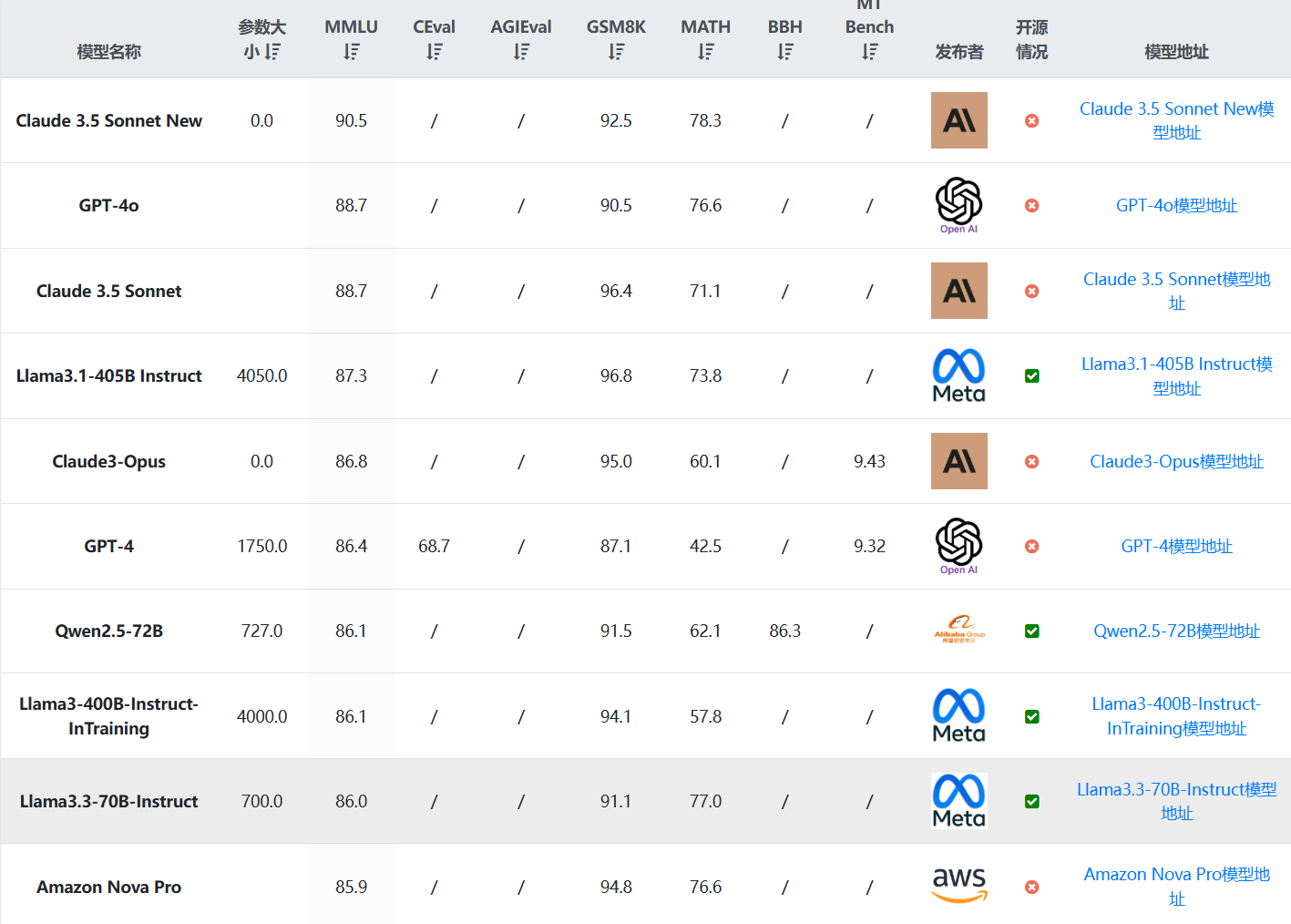
Llama系列大语言模型一直是开源领域的大模型标杆,Llama3系列大模型自从开源之后一直在不断更新。最早的Llama3模型于2024年4月开源,此后,几乎每个三个月都有一个新版本发布。就在昨天,Meta开源了最新的Llama3.3-70B模型,这是Llama3.3系列目前唯一开源的模型。尽管该模型的参数规模仅仅700亿,但是在多项评测基准上已经超过了4050亿参数规模的Llama3.1-405B,后者是Llama系列模型中参数规模最大的一个,也是业界开源模型中参数规模最高的模型之一。

Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。
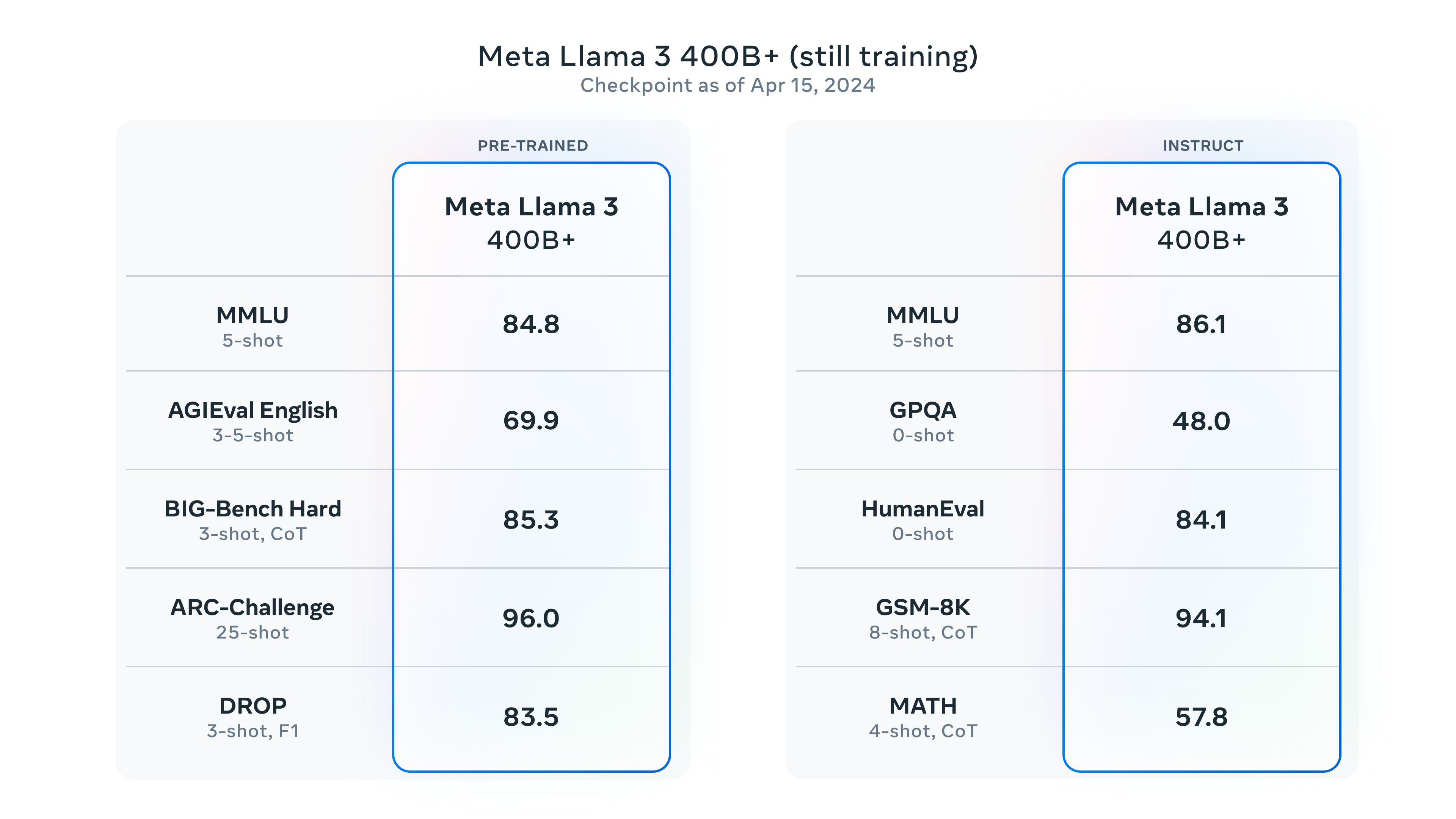
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。
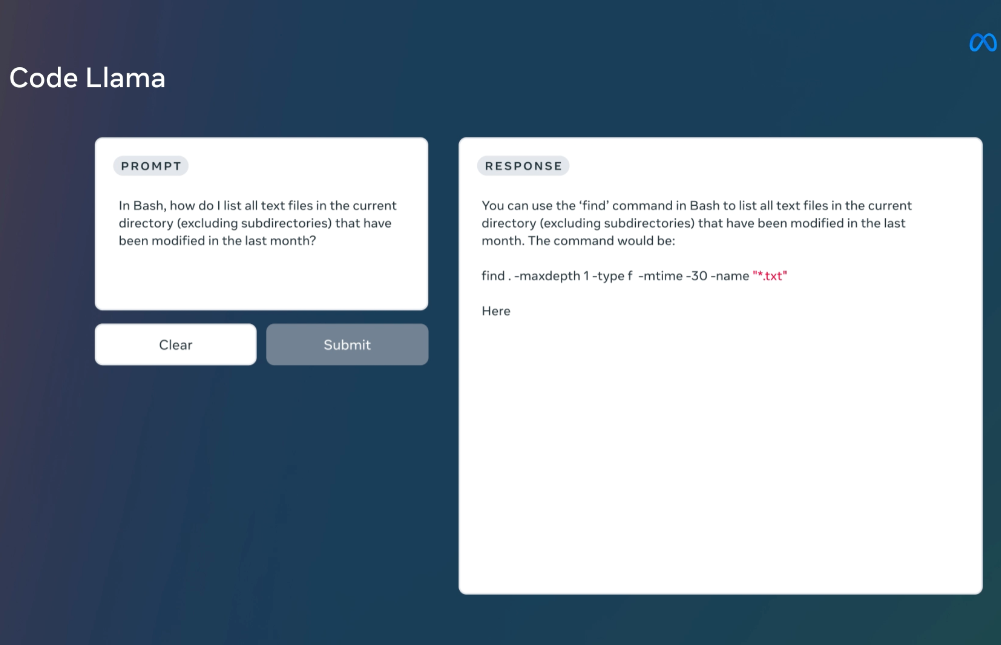
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst
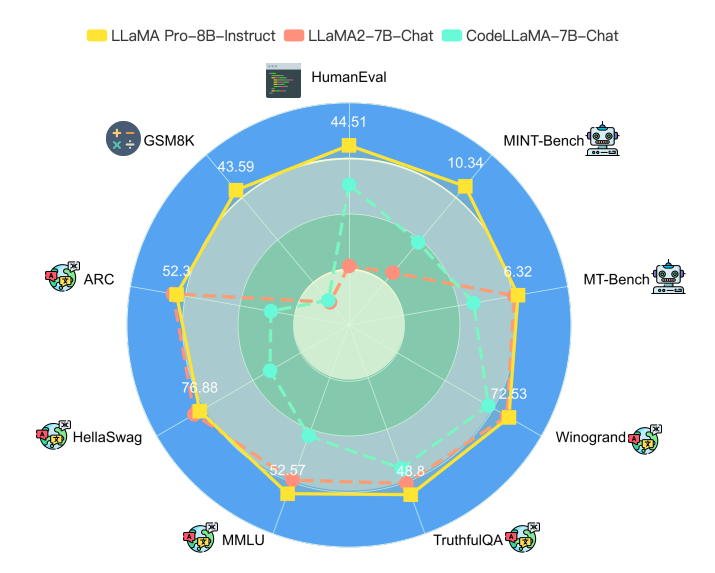
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
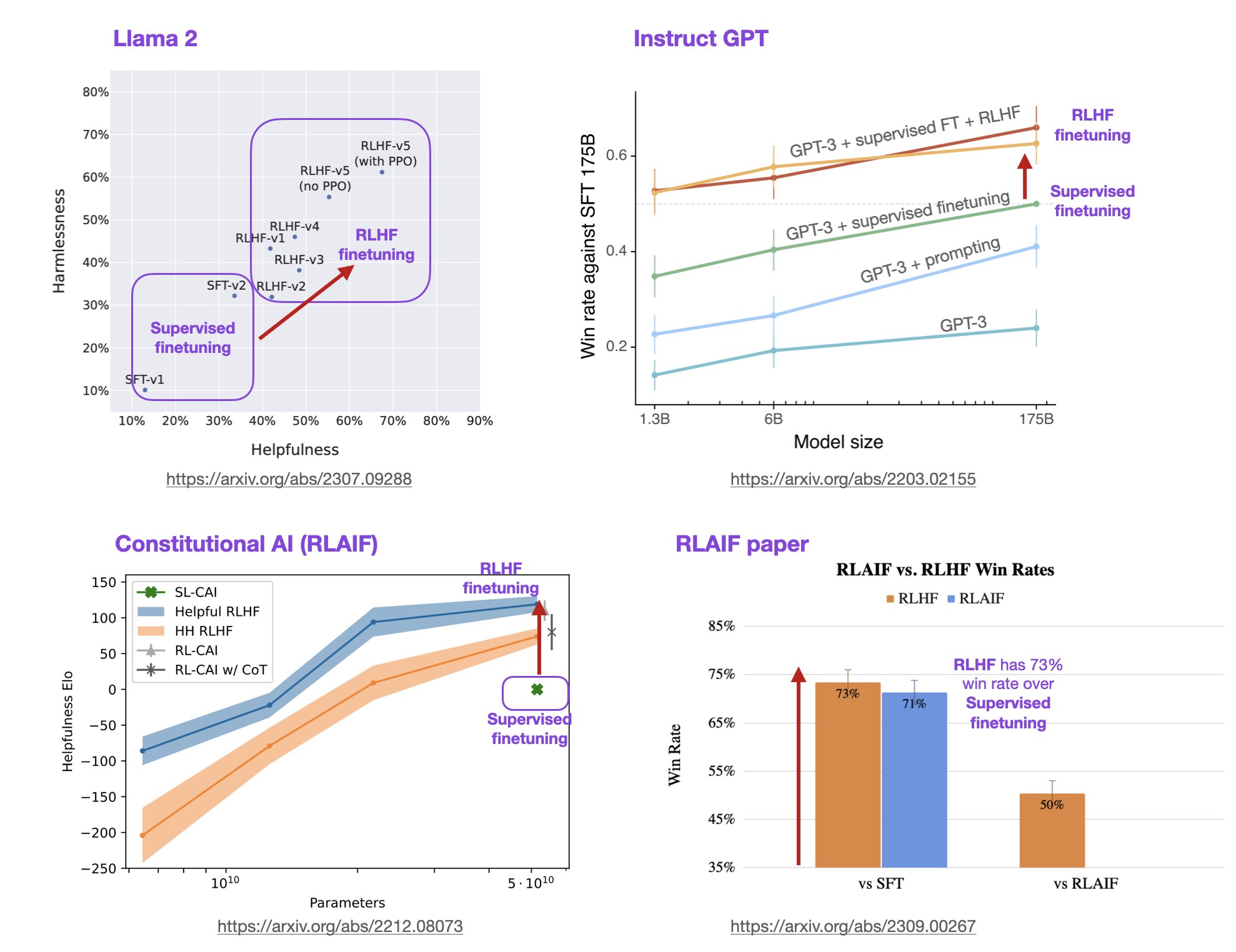
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。

据传,Meta公司即将推出一款名为Code LLaMA的开源AI模型,用于生成编程代码。这一新模型被视为与OpenAI的Codex模型竞争的产品,并建立在Meta最近发布的LLaMA 2上。以下是关于这一新技术的详细分析。
Vicuna是开源领域最强最著名的大语言模型,是UC伯克利大学的研究人员联合其它几家研究机构共同推出的一系列基于LLaMA微调的大语言模型。这个系列的模型因为极其良好的表现以及官方提供的匿名评测而广受欢迎。今天,LM-SYS发布Vicuna 1.5版本,包含4个模型,全部基于LLaMA2微调,最高支持16K上下文输入,最重要的是基于LLaMA2的可商用授权协议!免费商用授权!

LLaMA是由Meta开源的一个大语言模型,是最近几个月一系列开源模型的基础模型。包括著名的vicuna系列、LongChat系列等都是基于该模型微调得到。可以说,LLaMA的开源促进了大模型在开源界繁荣发展。而刚刚,微软官方宣布Azure上架LLaMA2模型!这意味着LLaMA2正式发布!
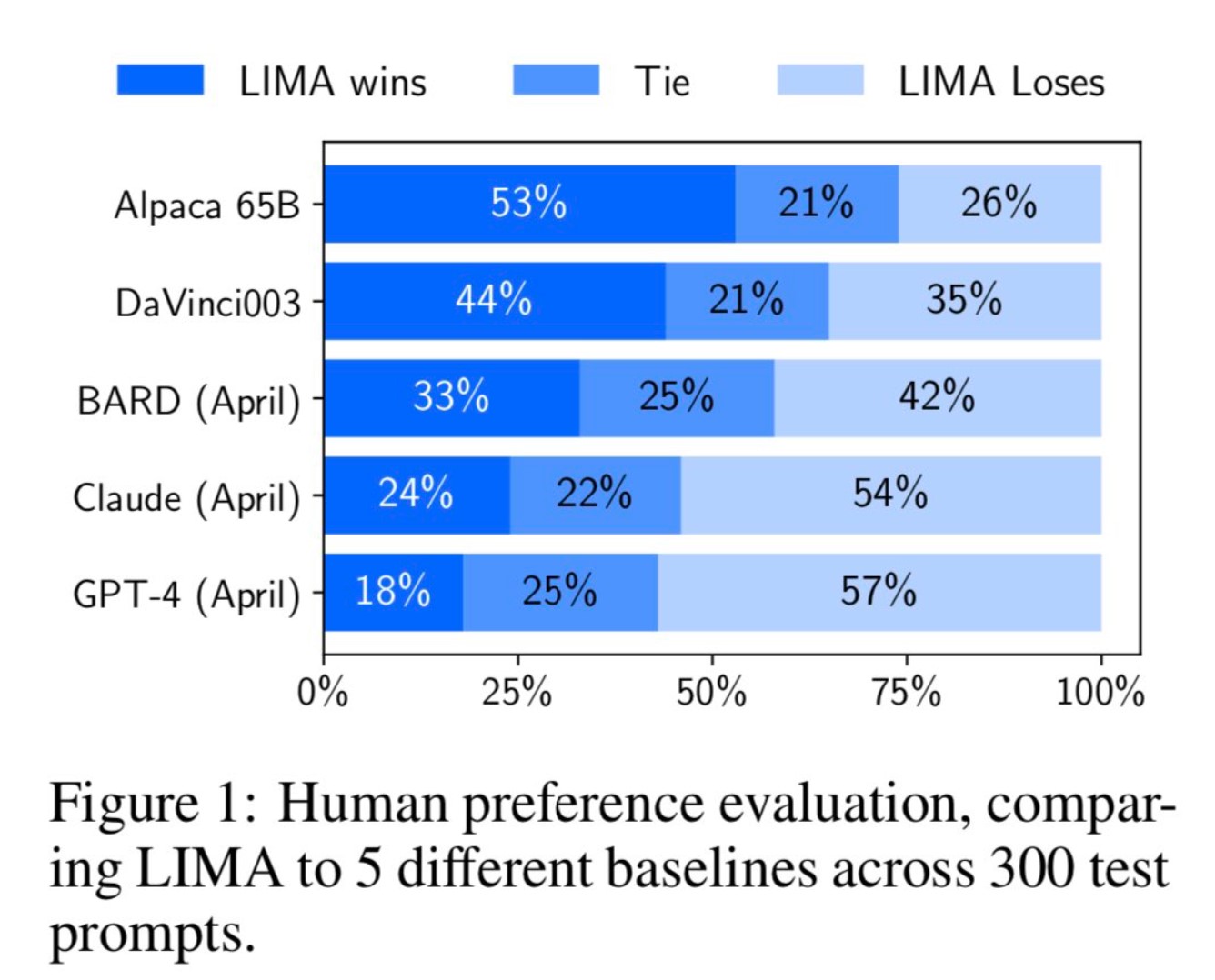
MetaAI最近公布了一个新的大语言模型预训练方法(LIMA: Less Is More for Alignment)。它最大的特点是不使用ChatGPT那样的(Reinforcement Learning from Human Feedback,RLHF)方法进行对齐训练。而是利用1000个精选的prompts与response来对模型进行微调,但却表现出了极其强大的性能。能够从训练数据中的少数几个示例中学习遵循特定的响应格式,包括从规划旅行行程到推测关于交替历史的复杂查询。
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
今日推荐
2023年AI与开源进展总结:来自LightningAI首席AI科学家Sebastian Raschka的2023年年度AI发展总结
来自OpenAI的官方解释:ChatGPT中的GPTs与Assistants API的区别是什么?有什么差异?
Google Gemini Pro 1.5重大更新:新增音频理解、单次处理任何格式数据、更强大的函数调用和JSON模式,DataLeanrerAI实测音频理解能力优秀,且免费使用!
OpenAI最新动向,Sam不再回归OpenAI,与Greg一起进入微软!OpenAI新任CEO由Emmett Shear接任!
MistralAI的混合专家大模型Mistral-7B×8-MoE详细介绍,效果超过LLaMA2-70B和GPT-3.5,推理速度快6倍
Stable Diffusion的最新实现——KerasCV的官方实现!
全球最大的39亿参数的text-to-image预训练模型发布