
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




Llama系列大语言模型是由MetaAI开源的一系列大语言模型。作为最早开源的大语言模型,Llama系列对大模型开源社区的推动有目共睹。而现在MetaAI开源Llama3.1系列模型,其中包括迄今为止最大规模的开源大语言模型Llama3.1-405B,参数规模达到了4050亿!其多项评测结果超过GPT-4、GPT-4o模型,与Claude3.5-Sonnet几乎有来有回!

Llama3是MetaAI开源的最新一代大语言模型。一发布就引起了全球AI大模型领域的广泛关注。这是MetaAI开源的第三代大语言模型,也是当前最强的开源模型。但相比较第一代和第二代的Llama模型,Llama3的升级之处有哪些?本文以图表的方式总结Llama3的升级之处。
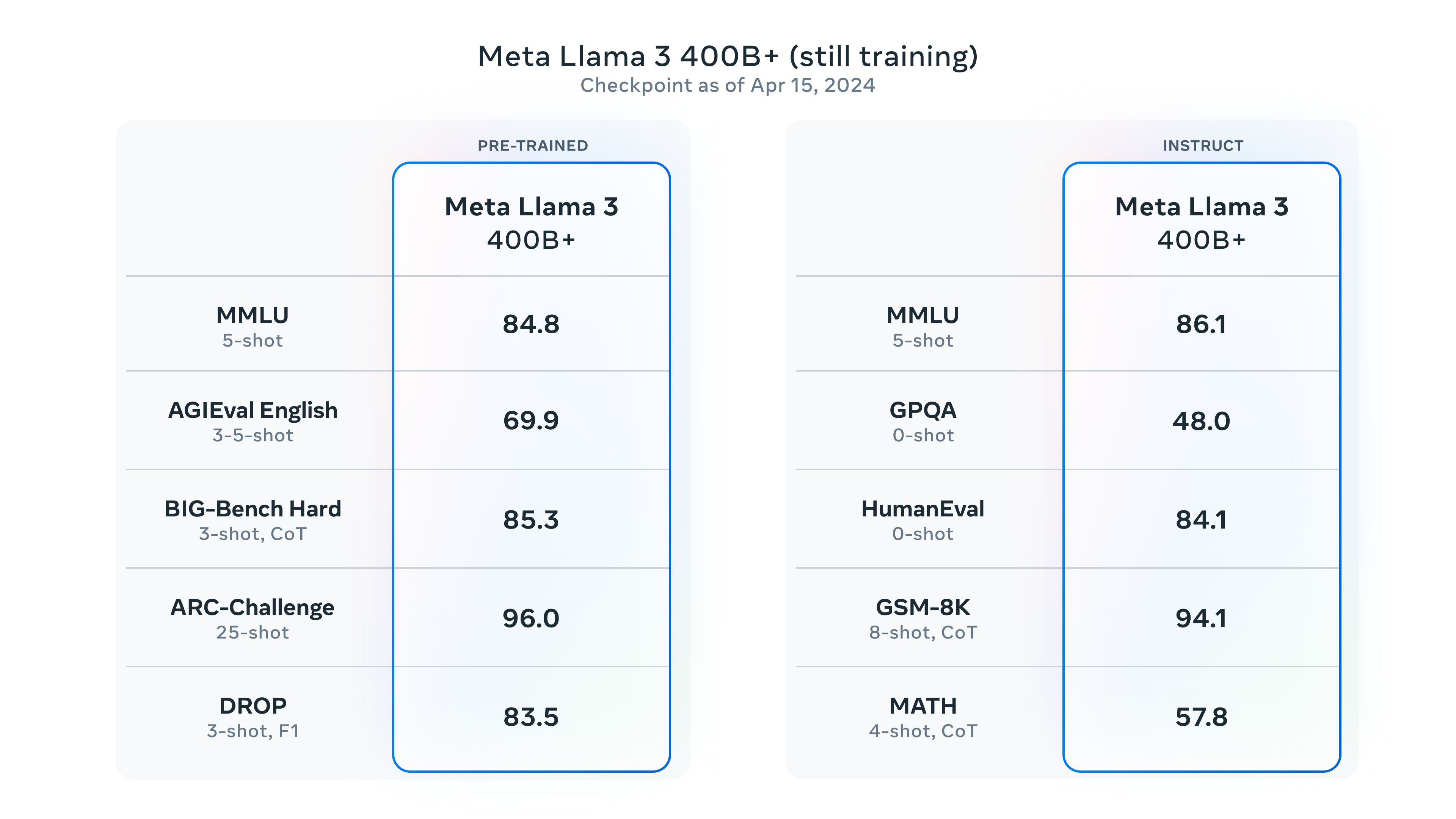
大语言模型开源领域最重要的一个模型就是MetaAI开源的Llama系列。当前,很多著名开源模型都是基于Llama系列进行预训练得到。就在刚才,MetaAI开源了第三代Llama3系列。官方透露的信息非常多,Llama3系列是目前为止最强的开源大语言模型,未来还有4000亿参数版本,支持多模态、超长上下文、多国语言!
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。
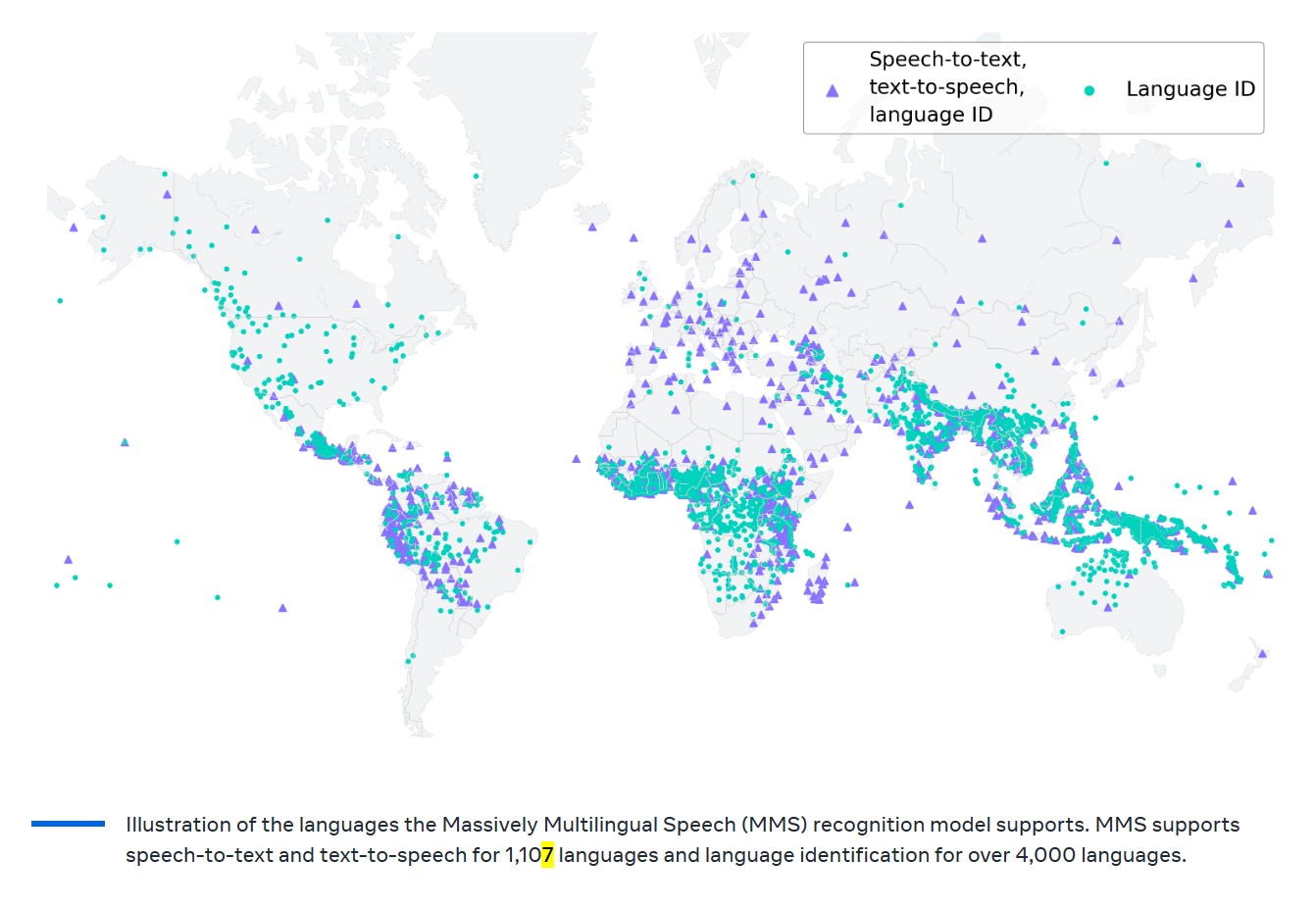
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~

SAM全称是Segment Anything Model,由MetaAI最新发布的一个图像分割领域的预训练模型。该模型十分强大,并且有类似GPT那种基于Prompt的工作能力,在图像分割任务上展示了强大的能力!此外,该模型从数据集到训练代码和预训练结果完全开源!真Open的AI!
今日推荐
DeepGraph Library(DGL)发布了0.81版本
大模型追踪利器!斯坦福大学发布基础大模型追踪图谱Ecosystem Graphs
OpenAI官方教程:如何针对大模型微调以及微调后模型出现的常见问题分析和解决思路~以GPT-3.5微调为例
MistralAI正式官宣开源全球最大的混合专家大模型Mixtral 8x22B,官方模型上架HuggingFace,包含指令微调后的版本!
重磅优惠!打1折!OpenAI开放最新的GPT-3.5和ChatGPT模型API商业服务!
Artificial Analysis报告显示中国AI产业技术突破,已经与美国形成全球双极主导
如何构建下一代机器翻译系统——Building Machine Translation Systems for the Next Thousand Languages