
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



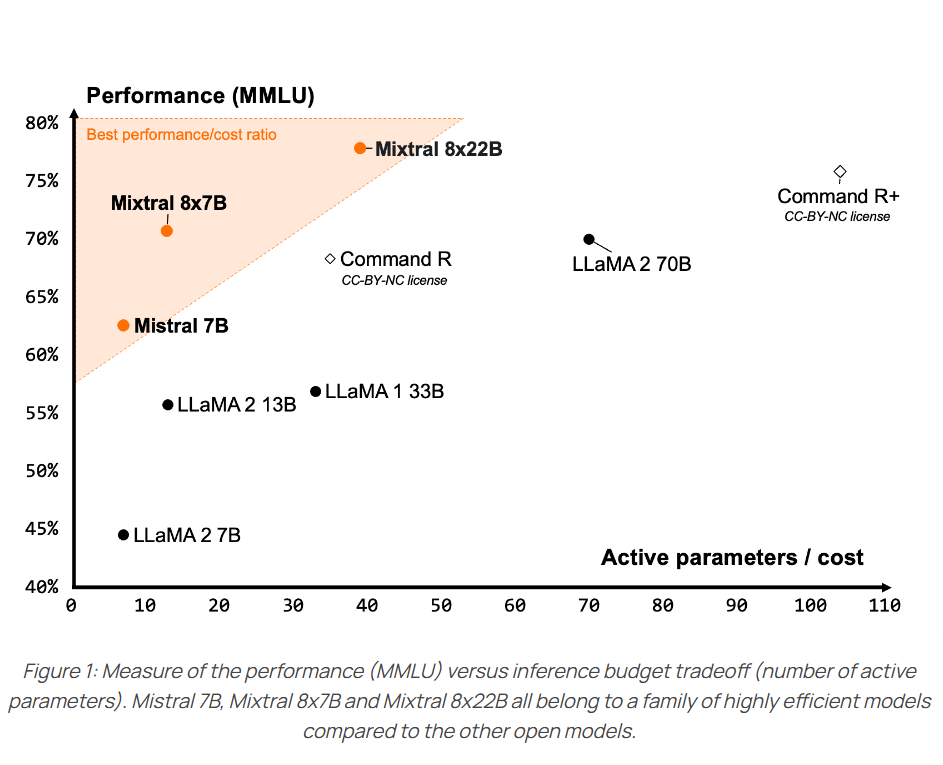
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。
今日推荐
速度,2个月免费的GPT-4和Claude-2.1,PerplexityAI发布圣诞优惠~
不更改一行AI模型的代码加速你的模型训练过程——AI模型训练加速库Nebulgym简介
如何让大模型提取更有信息密度的文本摘要?SalesforceAI最新的密度链提示方法Chain of Density Prompting
DeepGraph Library(DGL)发布了0.81版本
阿里开源最新Qwen-14B:英文理解能力接近LLaMA2-70B,数学推理能力超过GPT-3.5!
一张图总结OpenAI看好的未来AI应用——OpenAI Startup Fund支持的创业企业简介
SWE-bench Verified:提升 AI 模型在软件工程任务评估中的可靠性