
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




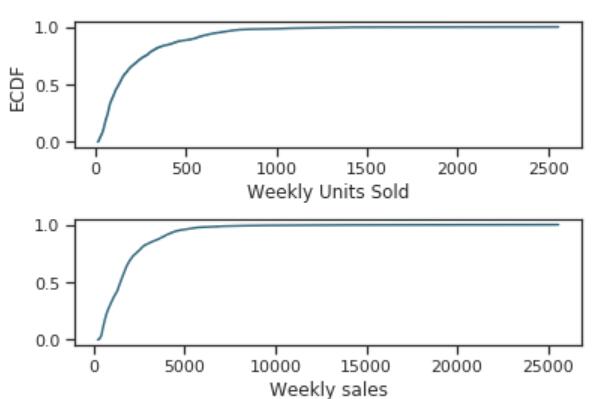
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
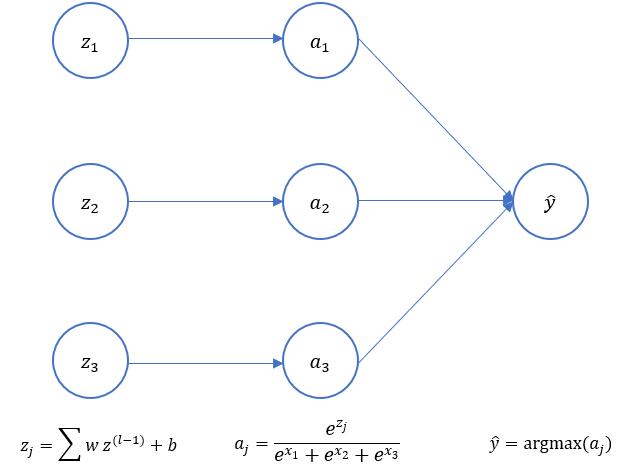
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。
您刚刚经历了一个耗时的过程,将一堆数据加载到python对象中。 也许你从数千个网站上爬取了数据。也许你计算了pi的数值。如果您的笔记本电脑电池耗尽或python崩溃,您的信息将丢失。 Pickling允许您将python对象保存为硬盘驱动器上的二进制文件。 在你pickle你的对象后,你可以结束你的python会话,重新启动你的计算机,然后再次将你的对象加载到python中。
今日推荐
重磅!苹果官方发布大模型框架:一个可以充分利用苹果统一内存的新的大模型框架MLX,你的MacBook可以一键运行LLaMA了
为什么Python可以处理任意长度的整数运算——Python原理详解
Text-to-Video来临!——Meta AI发布最新的视频生成预训练模型
ChatGLM-6B升级!清华大学开源VisualGLM-6B:一个可以在本地运行的读懂图片的语言模型!
导致Sam离职风波背后的OpenAI最近的技术突破——Q*项目信息汇总
截止目前中文领域最大参数量的大模型开源:上海人工智能实验室开源200亿参数的书生·浦语大模型(InternLM 20B系列),性能提升非常明显!
CerebrasAI开源可以在iPhone上运行的30亿参数大模型:BTLM-3B-8K,免费可商用,支持最高8K上下文输入,仅需3GB显存
如何构建下一代机器翻译系统——Building Machine Translation Systems for the Next Thousand Languages