
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




RedPajama模型是TOGETHER发布的一个开源可商用的大模型。2023年6月6日,TOGETHER在官方宣布该模型完成训练,经过测试,该模型目前超过所有7B规模的大模型,比LLaMA-7B和Falcon-7B的效果还要好!

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。
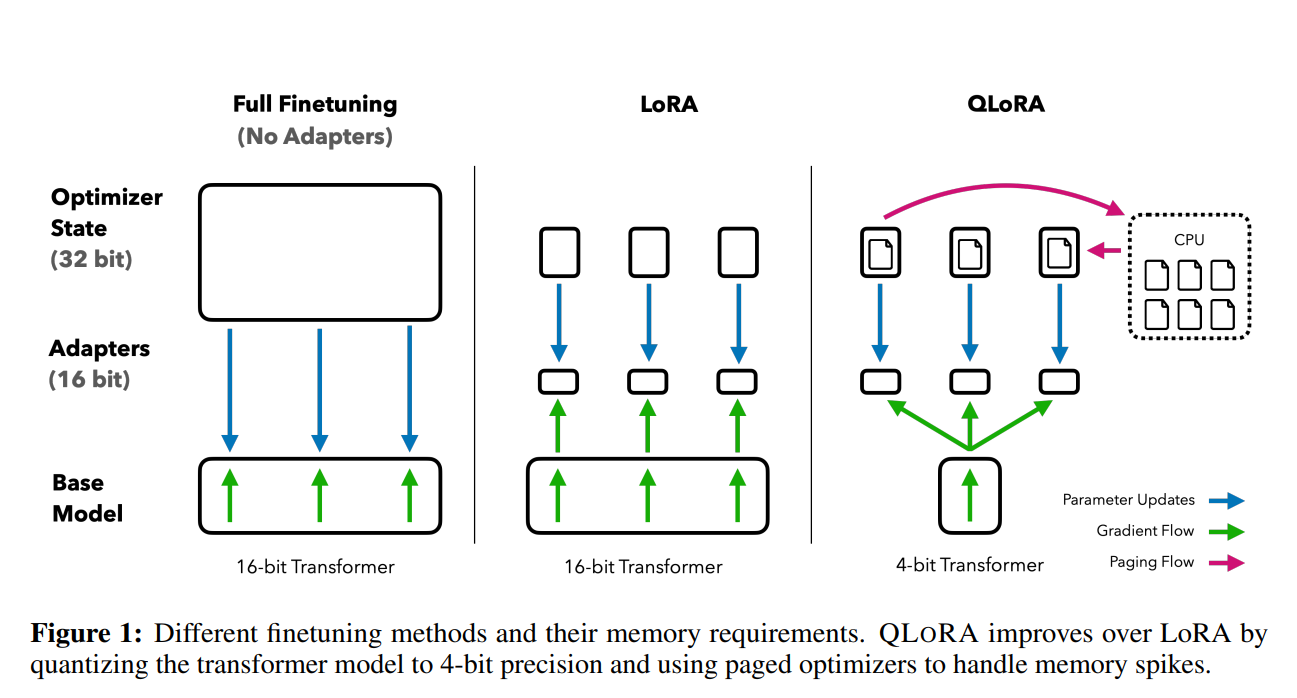
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。
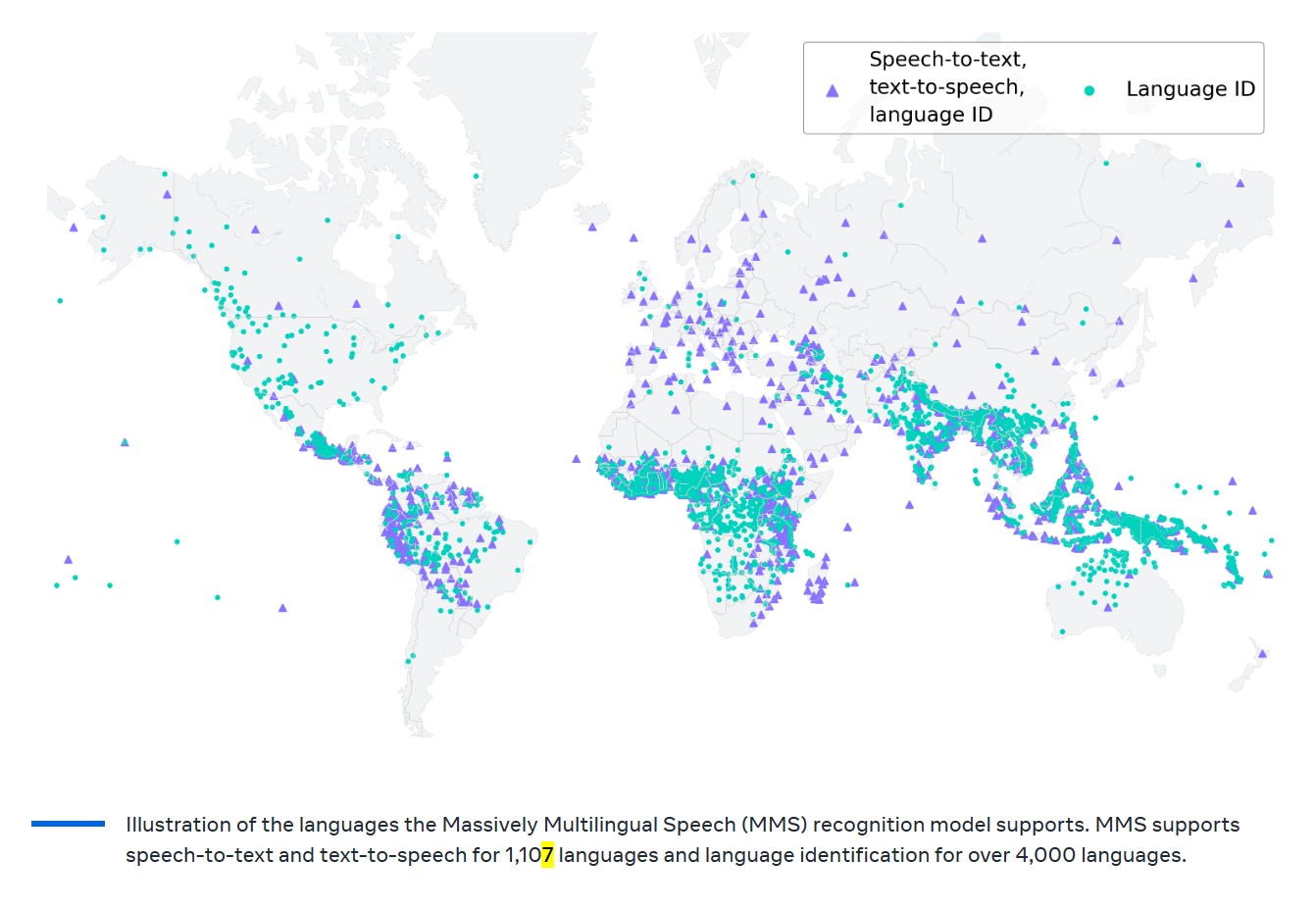
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!
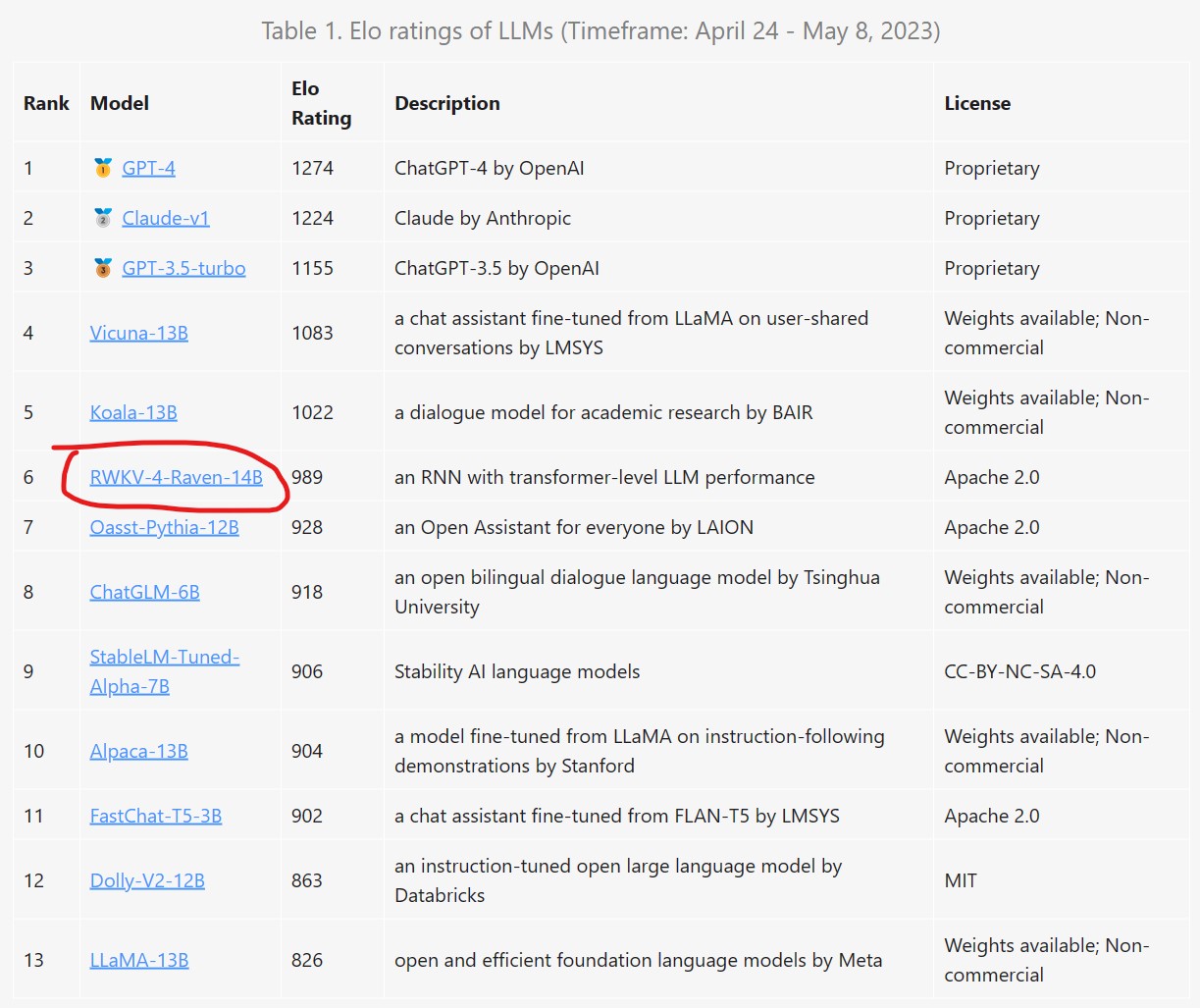
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!
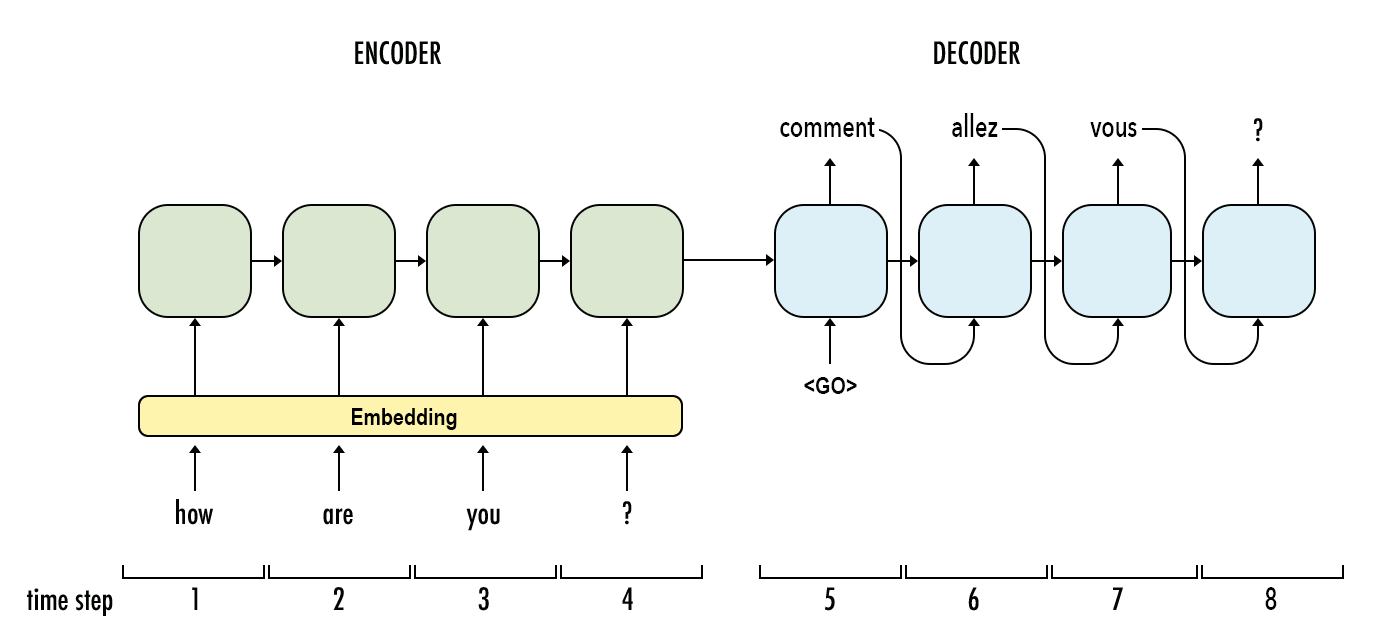
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。
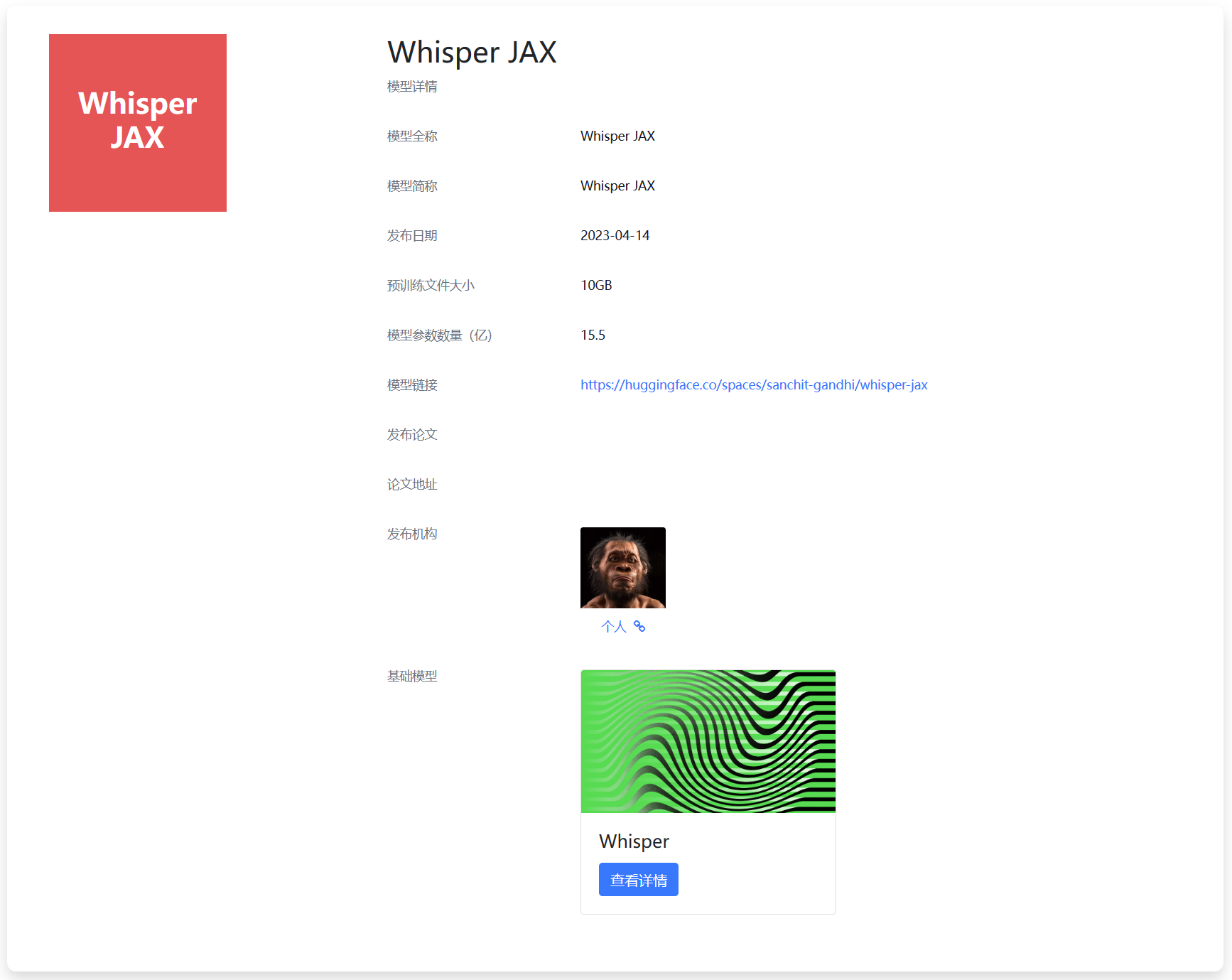
Whisper是OpenAI在2022年9月份开源的自动语音识别模型。官方宣传其英语的识别水平与人类接近。而2个月后,官方就发布了Whisper V2版本,是第一个版本继续训练2.5倍得到,且加了正则化技术。而今天,一位网友Sanchit Gandhi发布了Whisper JAX,这是对原有版本的优化结果,识别速度最高达到原始模型的70倍!
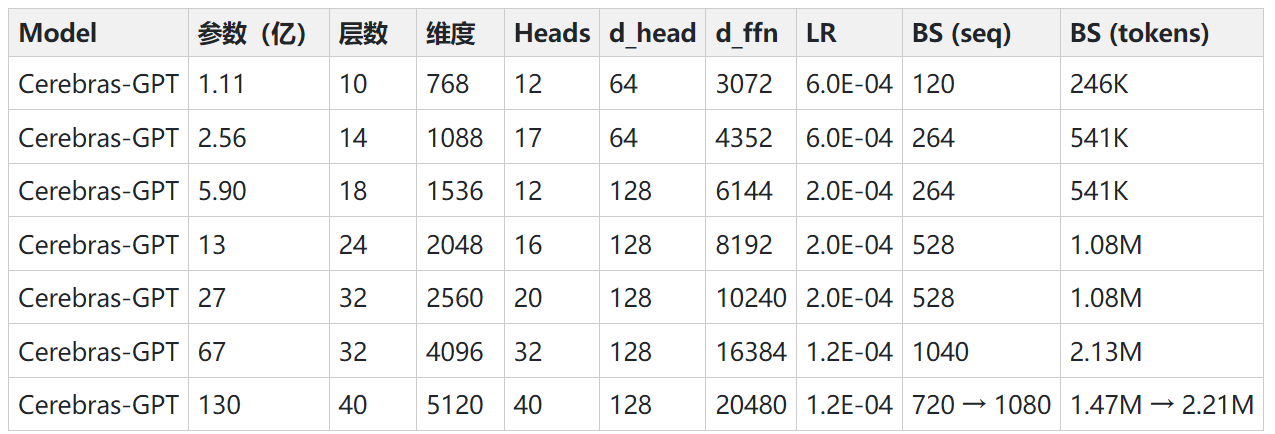
在最近的24个小时内,有2个开源的自然语言处理领域的开源预训练大模型发布。这两个模型都是类似GPT的Transformer模型,可以完成和ChatGPT类似的能力。最重要的是这2个模型完全开源!

彭博社今天发布了一份研究论文,详细介绍了BloombergGPT的开发,这是一个新的大规模生成式人工智能(AI)模型。这个大型语言模型(LLM)经过专门的金融数据训练,支持金融业内的多种自然语言处理(NLP)任务。