
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



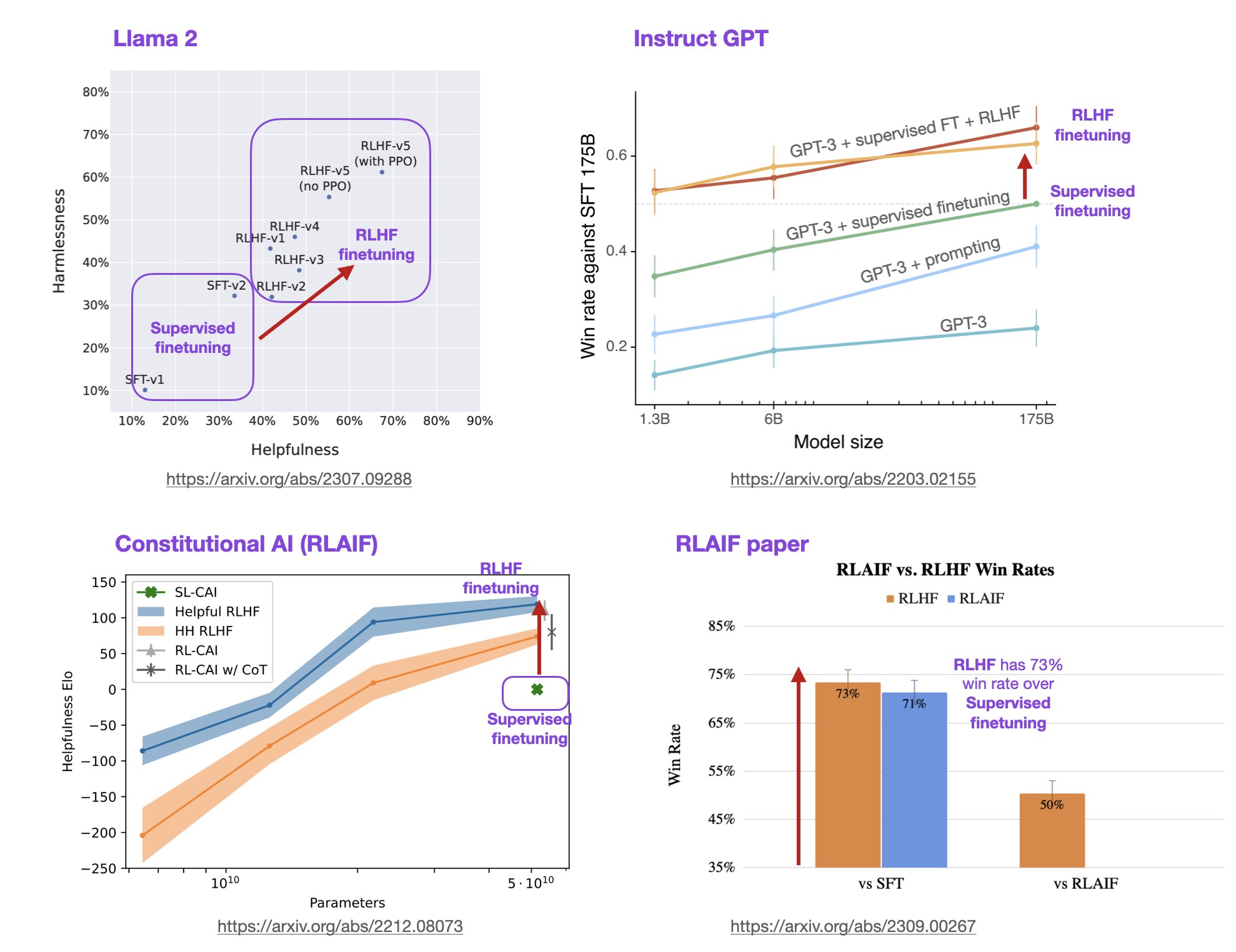
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。
今日推荐
使用kaggle房价预测的实例说明预测算法中OneHotEncoder、LabelEncoder与OrdinalEncoder的使用及其差异
华为大模型生态重要一步!PyTorch最新2.1版本宣布支持华为昇腾芯片(HUAWEI Ascend)
手把手教你本地部署清华大学的ChatGLM-6B模型——Windows+6GB显卡本地部署
截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
GGUF格式的大模型文件是什么意思?gguf是什么格式?如何使用?为什么有GGUF格式的大模型文件?GGUF大模型文件与GGML的差异是啥?