
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



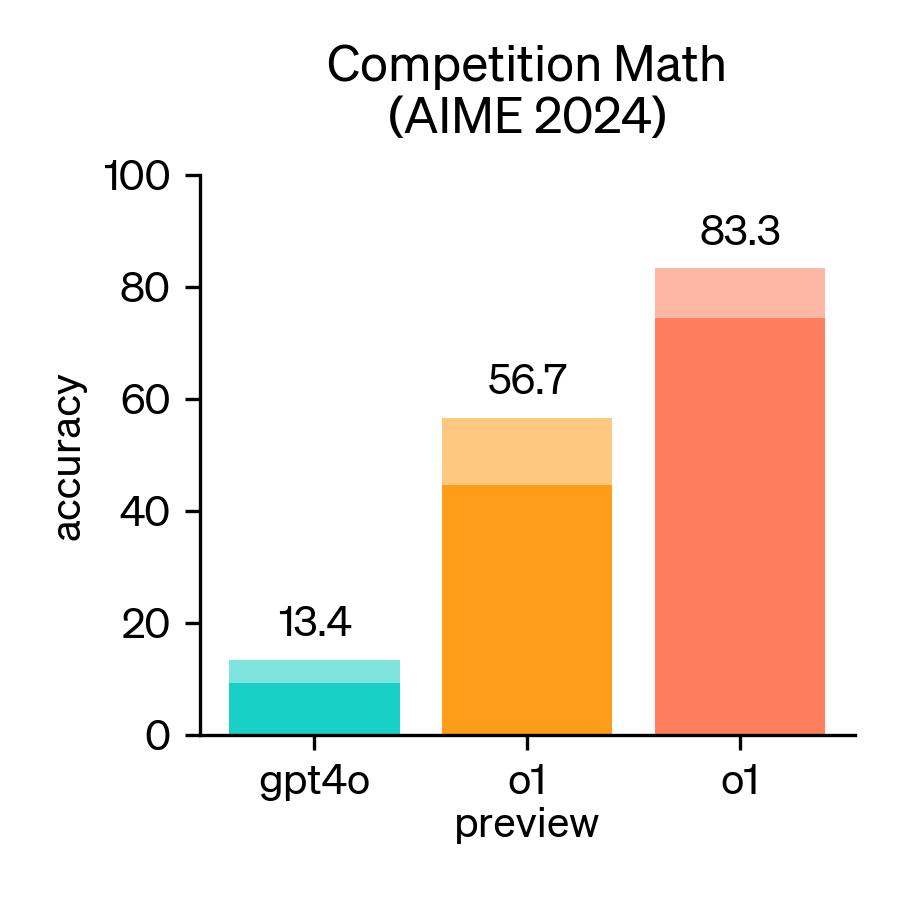
2024年,美国数学邀请赛(AIME)成为评估大型语言模型(LLM)数学推理能力的重要基准。AIME是一项备受尊崇的考试,包含15道题,考试时间为3小时,旨在考察美国顶尖高中生在各类数学领域的复杂问题解决能力。
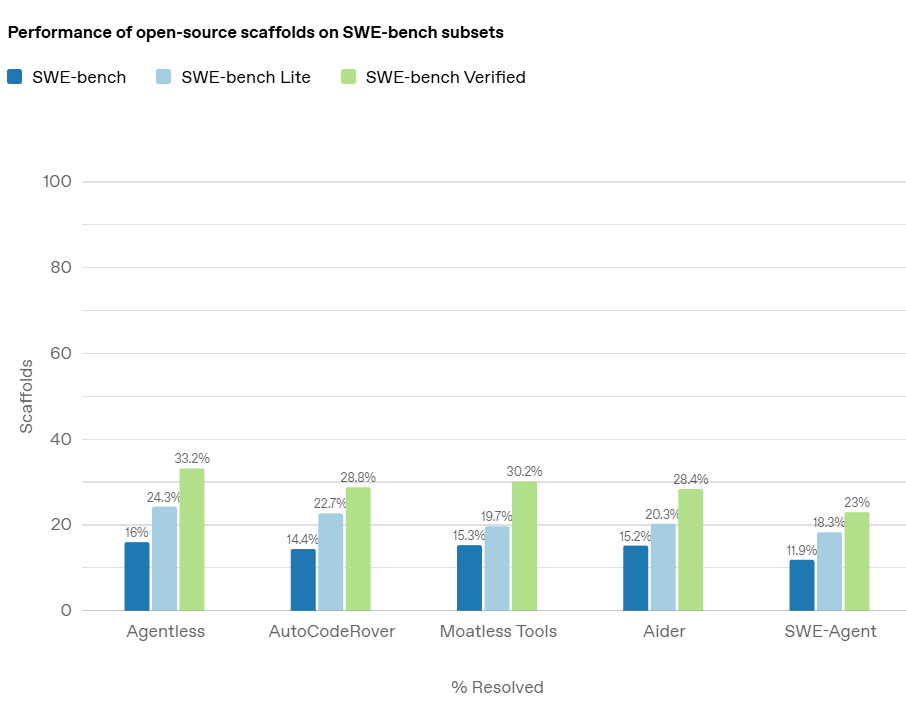
在人工智能领域,随着大型语言模型(LLMs)在各类任务中的表现不断提升,评估这些模型的实际能力变得尤为重要。尤其是在软件工程领域,AI 模型是否能够准确地解决真实的编程问题,是衡量其真正应用潜力的关键。而在这方面,OpenAI 推出的 *SWE-bench Verified* 基准测试,旨在提供一个更加可靠和精确的评估工具,帮助开发者和研究者全面了解 AI 模型在处理软件工程任务时的能力。
今日推荐
马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
Seq2Seq的建模解释和Keras中Simple RNN Cell的计算及其代码示例
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
OpenAI首次发布语音合成大模型:VoiceEngine,一个可以用15秒原始录音就可以克隆声音的语音合成大模型
OpenAI更新新版的Assistant API接口到Assistant API v2版本,现在你可以让GPT-4同时搜索1万个文件