
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



ChatGLM-6B是清华大学知识工程和数据挖掘小组发布的一个类似ChatGPT的开源对话机器人,由于该模型是经过约1T标识符的中英文训练,且大部分都是中文,因此十分适合国内使用。本文将详细记录如何在Windows环境下基于GPU和CPU两种方式部署使用ChatGLM-6B,并说明如何规避其中的问题。
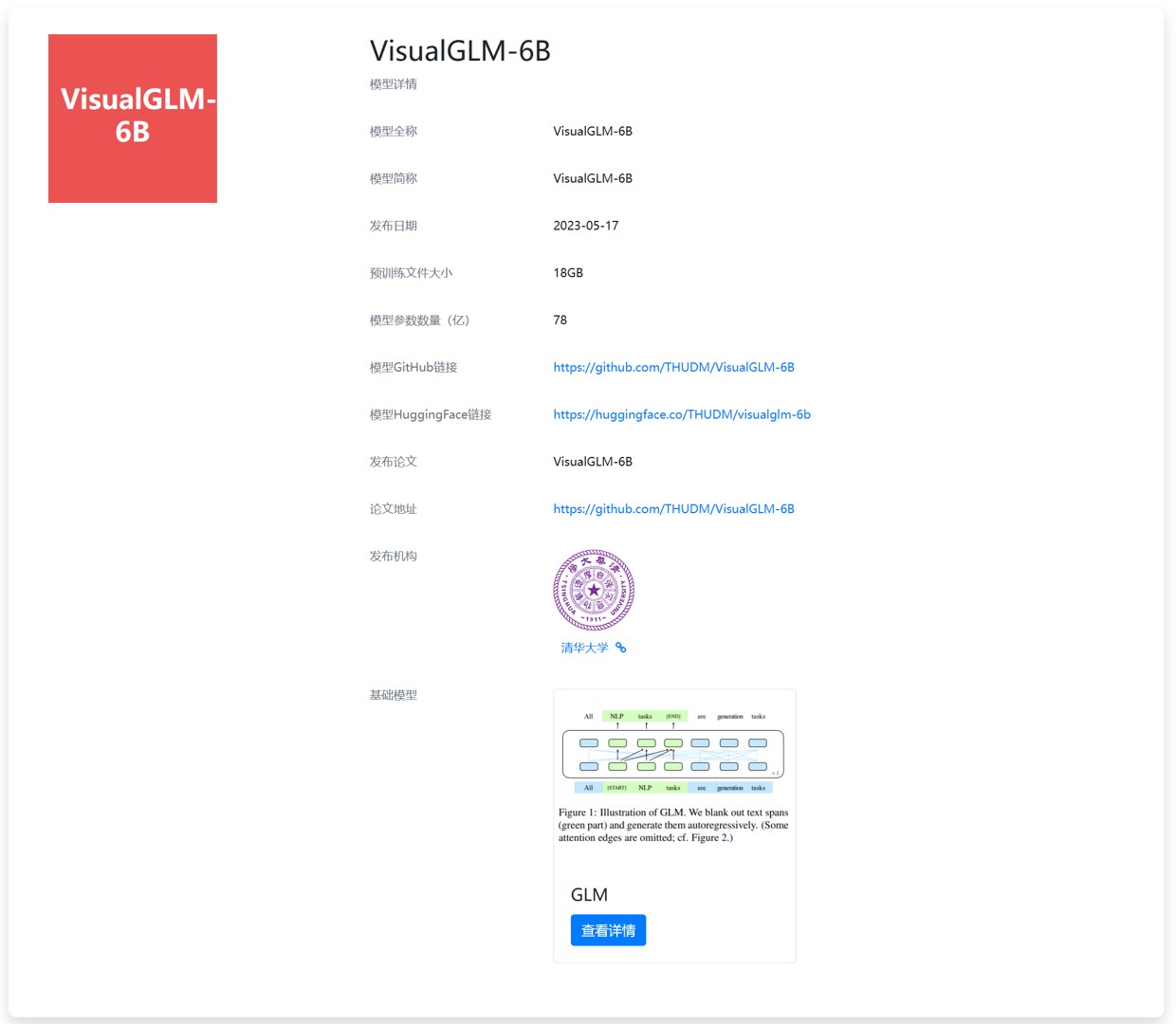
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。