
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



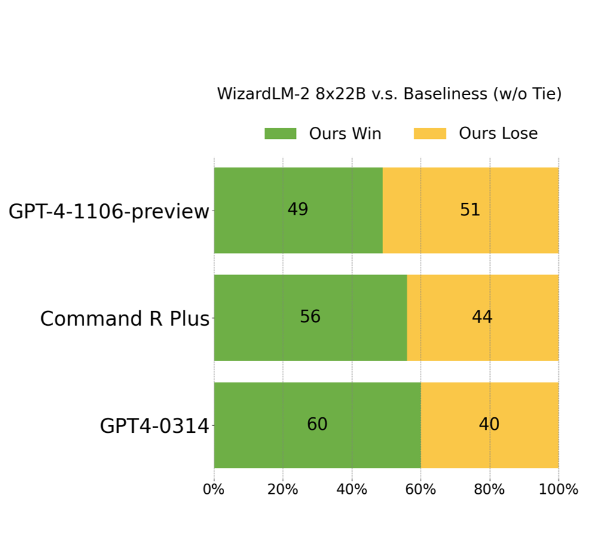
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。
WizardLM是微软联合北京大学开源的一个大语言模型。此前,发布的WizardLM和WizardCoder都是业界开源领域最强的大模型。其中,前者是针对指令优化的大模型,而后者则是针对编程优化的大模型。而此次WizardMath则是他们发布的第三个大模型系列,主要是针对数学推理优化的大模型。在GSM8K的评测上,WizardMath得分超过了ChatGPT-3.5、Claude Instant-1等闭源商业模型,得分十分逆天!
今日推荐
未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考
tf.nn.softmax_cross_entropy_with_logits函数
大模型驱动的自动代理(AI Agent):将语言模型的能力变成通用能力的一种方式——来自OpenAI安全团队负责人的解释与观点
GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
大型语言模型的新扩展规律(DeepMind新论文)——Training Compute-Optimal Large Language Models
正则化和数据增强对模型的影响并不总是好的:The Effects of Regularization and Data Augmentation are Class Dependent