
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



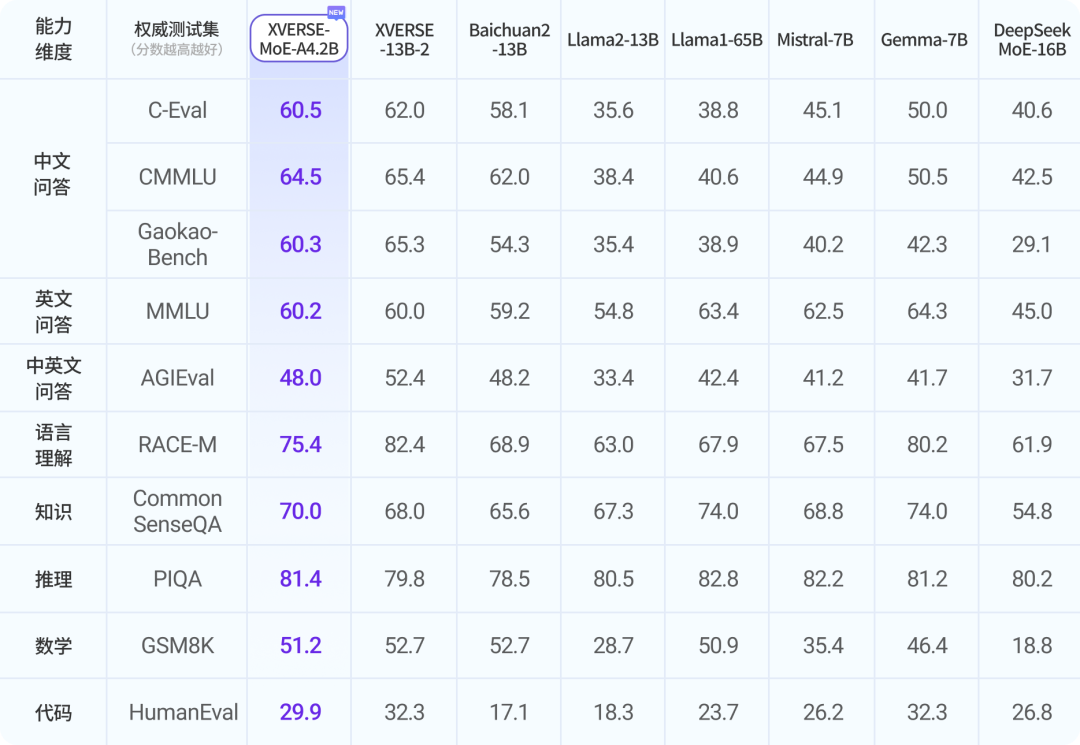
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
今日推荐
正则化和数据增强对模型的影响并不总是好的:The Effects of Regularization and Data Augmentation are Class Dependent
微软发布大语言模型与传统编程语言的集成编程框架——Python版本的Semantic Kernel今日发布
OpenRouterAI:一个提供目前最优秀大模型API的网站,支持GPT-4 32k和Claude v2接口!
text-davinci-003后继者!OpenAI发布了一个新的补全大模型:GPT-3.5-Turbo-Instruct,完全的指令模型,没有聊天优化
手把手教你本地部署清华大学的ChatGLM-6B模型——Windows+6GB显卡本地部署
如何估计大模型推理或者训练所需要的显存大小?HuggingFace官方工具Model Memory Calculator,一键计算大模型显存需求~
好东西!Transformer入门神作手把手按行实现Transformer教程The Annotated Transformer2022版本来袭