
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



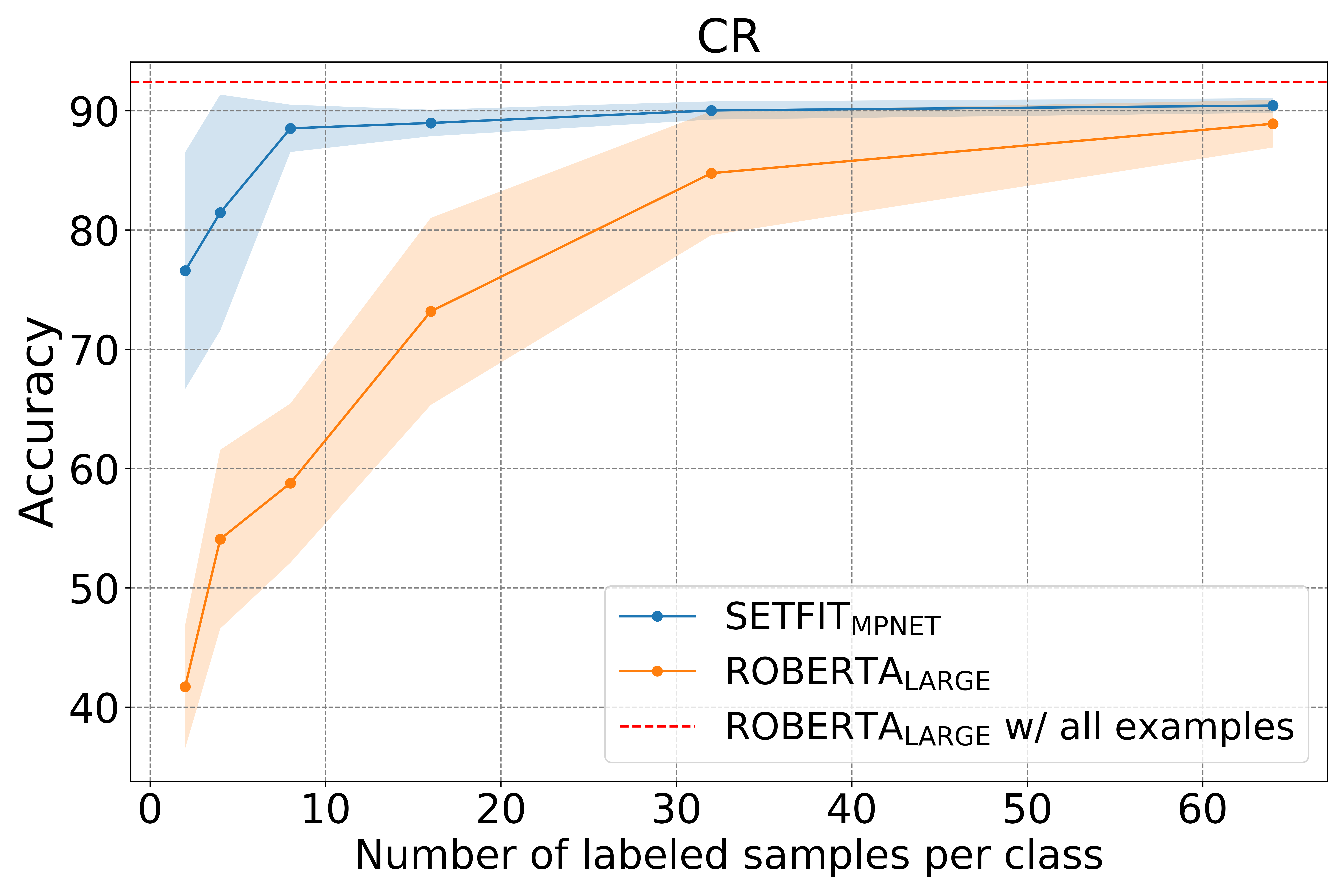
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。
今日推荐
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)
扩散模型是如何工作的:从0开始的数学原理——How diffusion models work: the math from scratch
关于OpenAI最新的营收和成本数据估算:包括ChatGPT Plus付费用户数以及OpenAI的月度成本等
好消息~Kaggle提高了免费的GPU和内存等计算资源的使用额度!
Java类型转换中valueOf方法和parseInt方法的区别
73亿参数顶级开源模型Mistral-7B升级到v0.2版本,性能与上下文长度均有增强。
ChatGPT 3.5只有200亿规模的参数?最新微软的论文暴漏OpenAI的ChatGPT的参数规模远低于1750亿!