
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




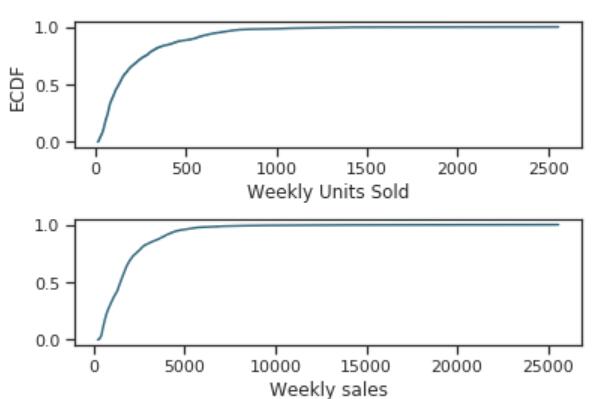
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
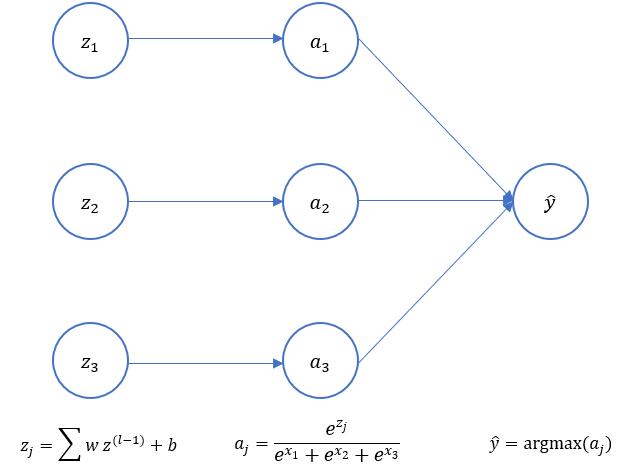
softmax作为多标签分类中最常用的激活函数,常常作为最后一层存在,并经常和交叉熵损失函数一起搭配使用。这里描述如何推导交叉熵损失函数的推导问题。

Tensorflow中tf.data.Dataset是最常用的数据集类,我们也使用这个类做转换数据、迭代数据等操作。本篇博客将简要描述这个类的使用方法。
本篇博客主要讲解如何从给定参数的的正态分布/均匀分布中生成随机数以及如何以给定概率从数字列表抽取某数字或从区间列表的某一区间内生成随机数,按照内容将博客分为3部分,并附上代码。
您刚刚经历了一个耗时的过程,将一堆数据加载到python对象中。 也许你从数千个网站上爬取了数据。也许你计算了pi的数值。如果您的笔记本电脑电池耗尽或python崩溃,您的信息将丢失。 Pickling允许您将python对象保存为硬盘驱动器上的二进制文件。 在你pickle你的对象后,你可以结束你的python会话,重新启动你的计算机,然后再次将你的对象加载到python中。
今日推荐
A21 Labs宣布开源520亿参数的全新混合专家大模型(Mixture of Experts,MoE)Jamba:单个GPU的上下文长度是Mixtral 8x7B的三倍
Java爬虫入门简介(四)——HttpClient保存使用Cookie登录
国产MoE架构模型大爆发!深圳元象科技XVERSE开源256亿参数MoE大模型XVERSE-MoE-A4.2B,评测结果接近Llama1-65B
Meta开源Llama3.3-70B-Instruct模型:大模型后训练的佳作,性能超越4050亿参数规模的Llama3.1-405B大模型!
全球首个200万上下文商业产品开始内测!月之暗面Kimi助手开启最长上下文模型内测邀请。
吴恩达再开新课程!如何基于大语言模型实现更强大的语义搜索课程!
Java爬虫入门简介(三) —— Jsoup解析HTML页面
ChatGPT即将发布的新版本:增加自动标签管理并去除对ChatGPT回答的点赞按钮
MistralAI的混合专家大模型Mistral-7B×8-MoE详细介绍,效果超过LLaMA2-70B和GPT-3.5,推理速度快6倍