
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



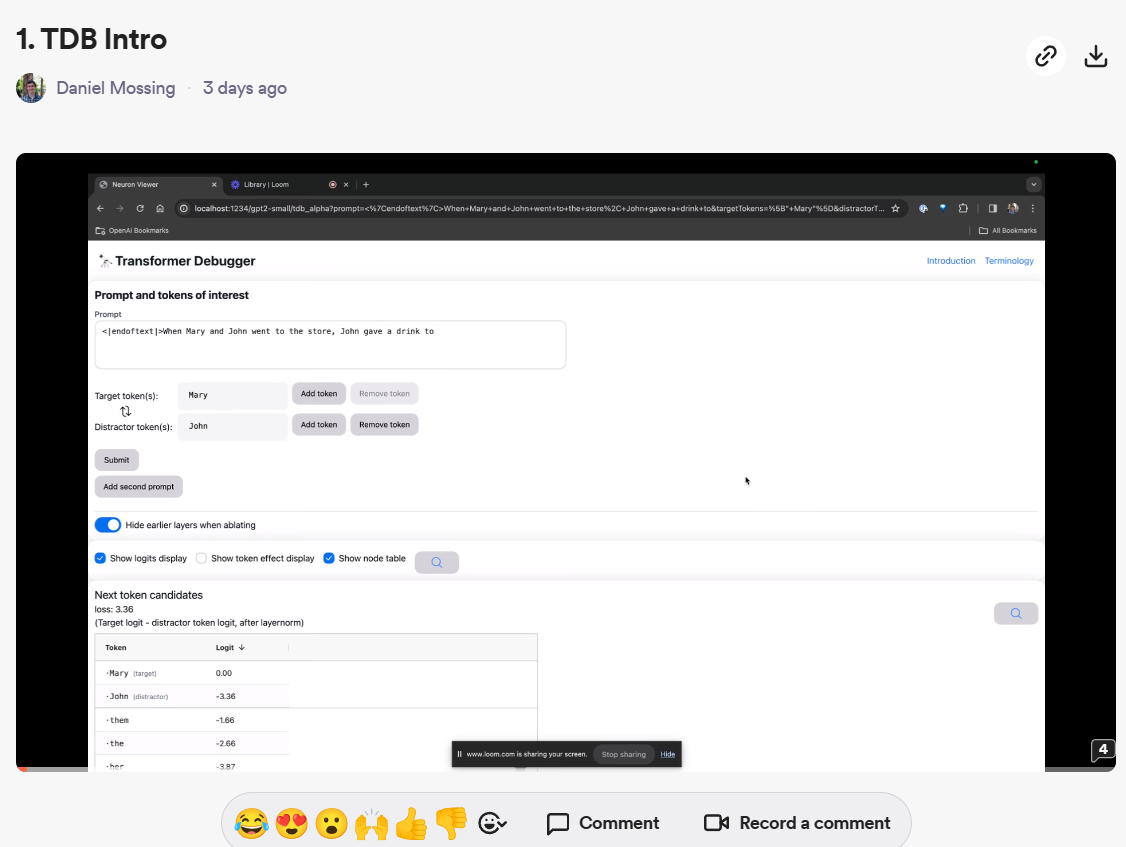
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。
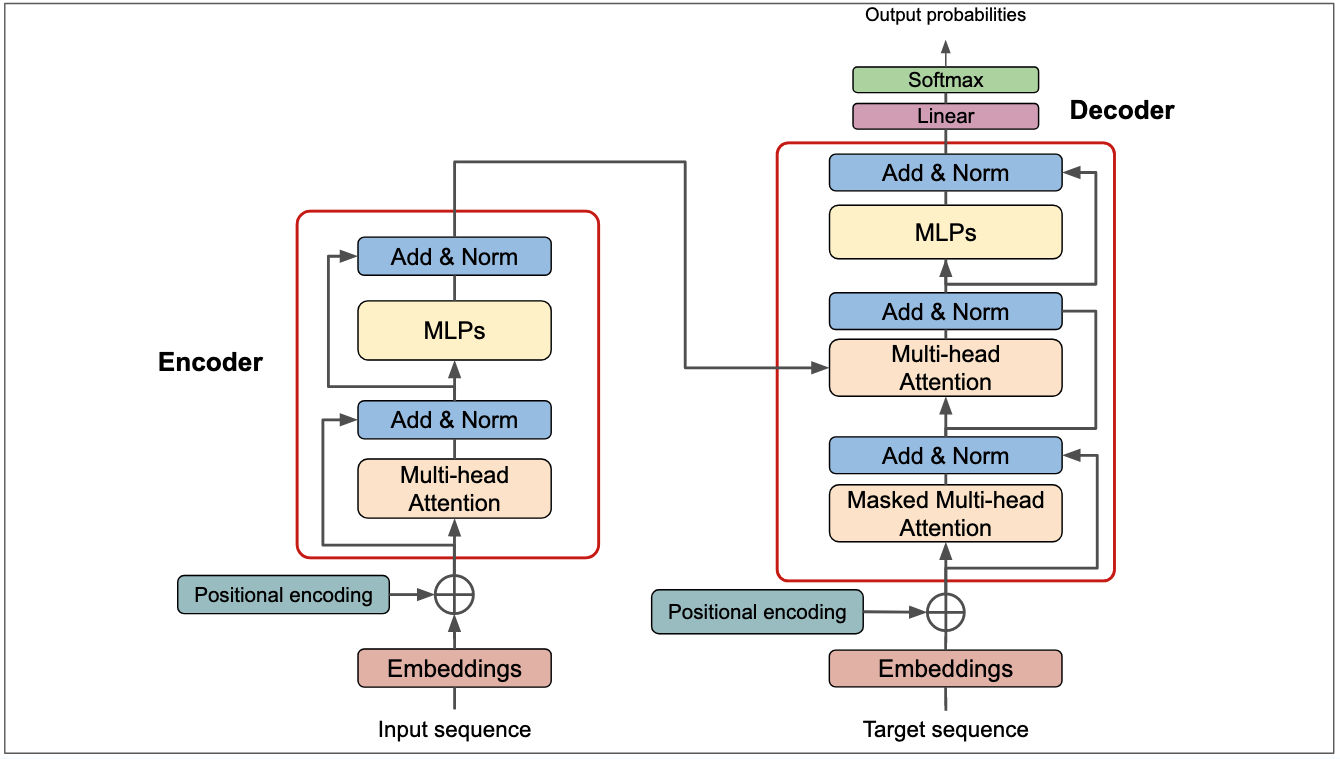
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。
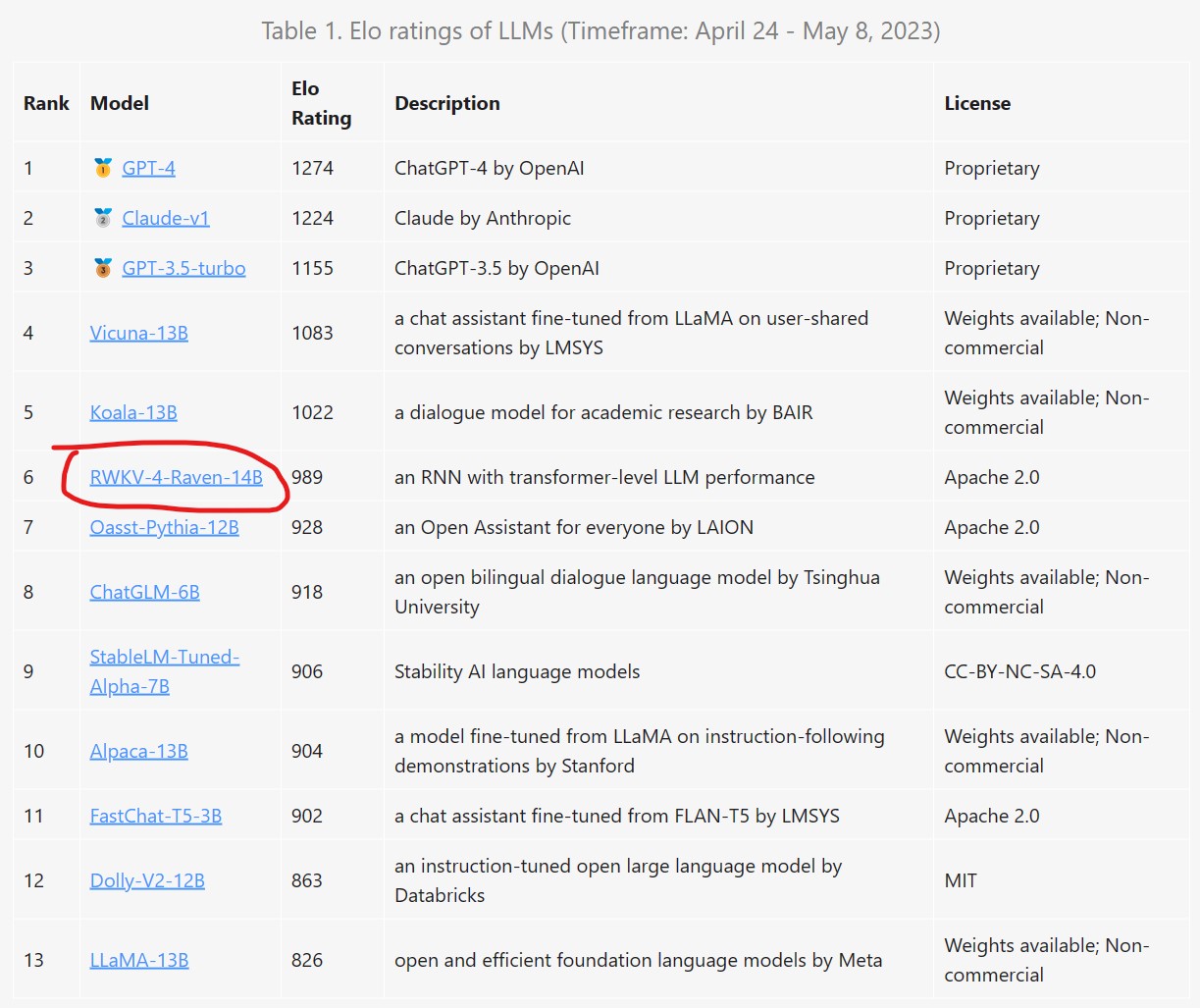
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。今天,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。
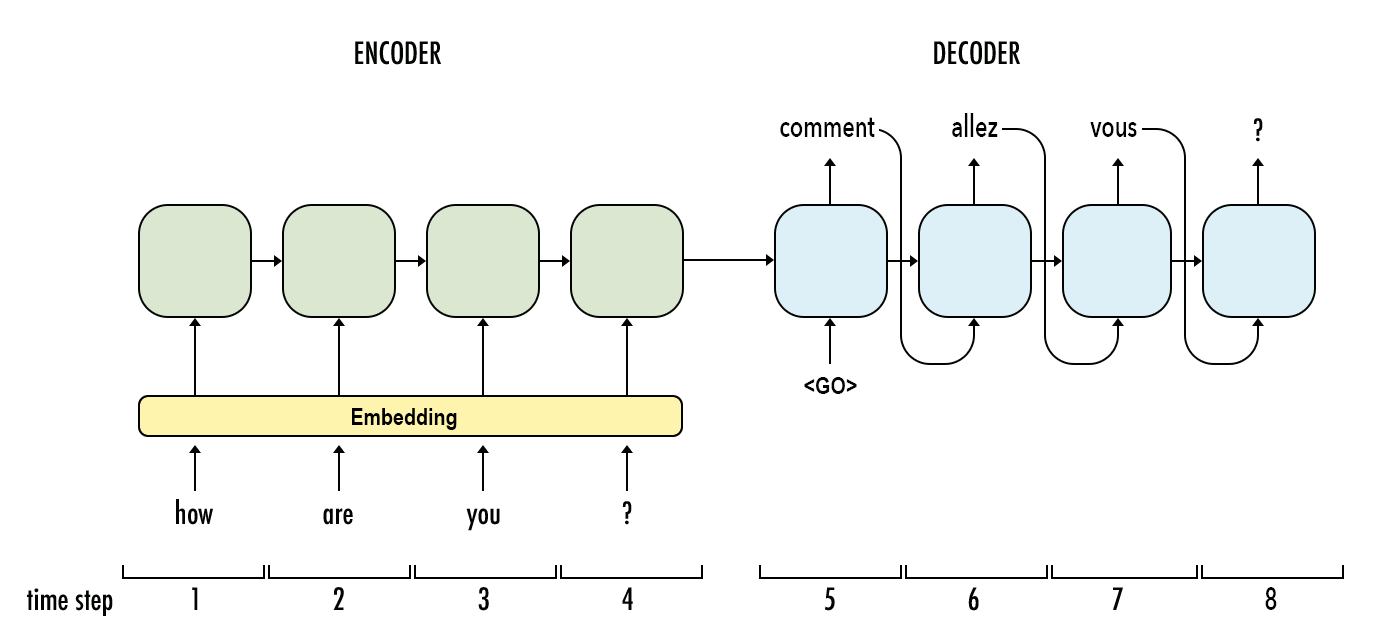
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。

近几年语言模型的发展速度很快,各种大语言预训练模型的推出让算法在各种NLP的任务中都取得了前所未有的成绩。其中2017年谷歌发布的Attention is All You Need论文将transformer架构推向了世界,这也是现在最流行的语言模型结构。威斯康星大学麦迪逊分校的统计学教授Sebastian Raschka总结了6中Language Transformer的使用方法。值得一看。
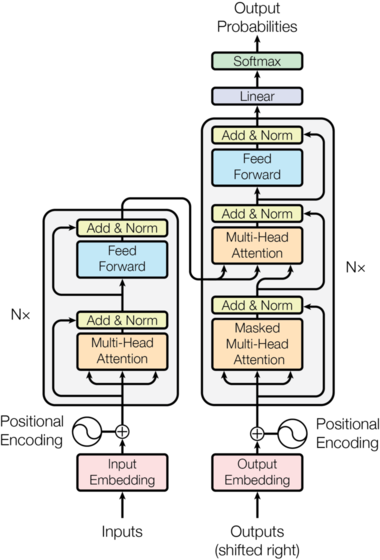
The Annotated Transfomer是哈佛大学的研究人员于2018年发布的Transformer新手入门教程。这个教程从最基础的理论开始,手把手教你按照最简单的python代码实现Transformer,一经推出就广受好评。2022年,这个入门教程有了新的版本。
Hugging Face一直在努力支持深度学习,但是,这只是深度学习的一部分。传统统计机器学习领域里面最重要的工具Scikit-learn如今终于和深度学习的开源标杆工具Hugging Face联手。
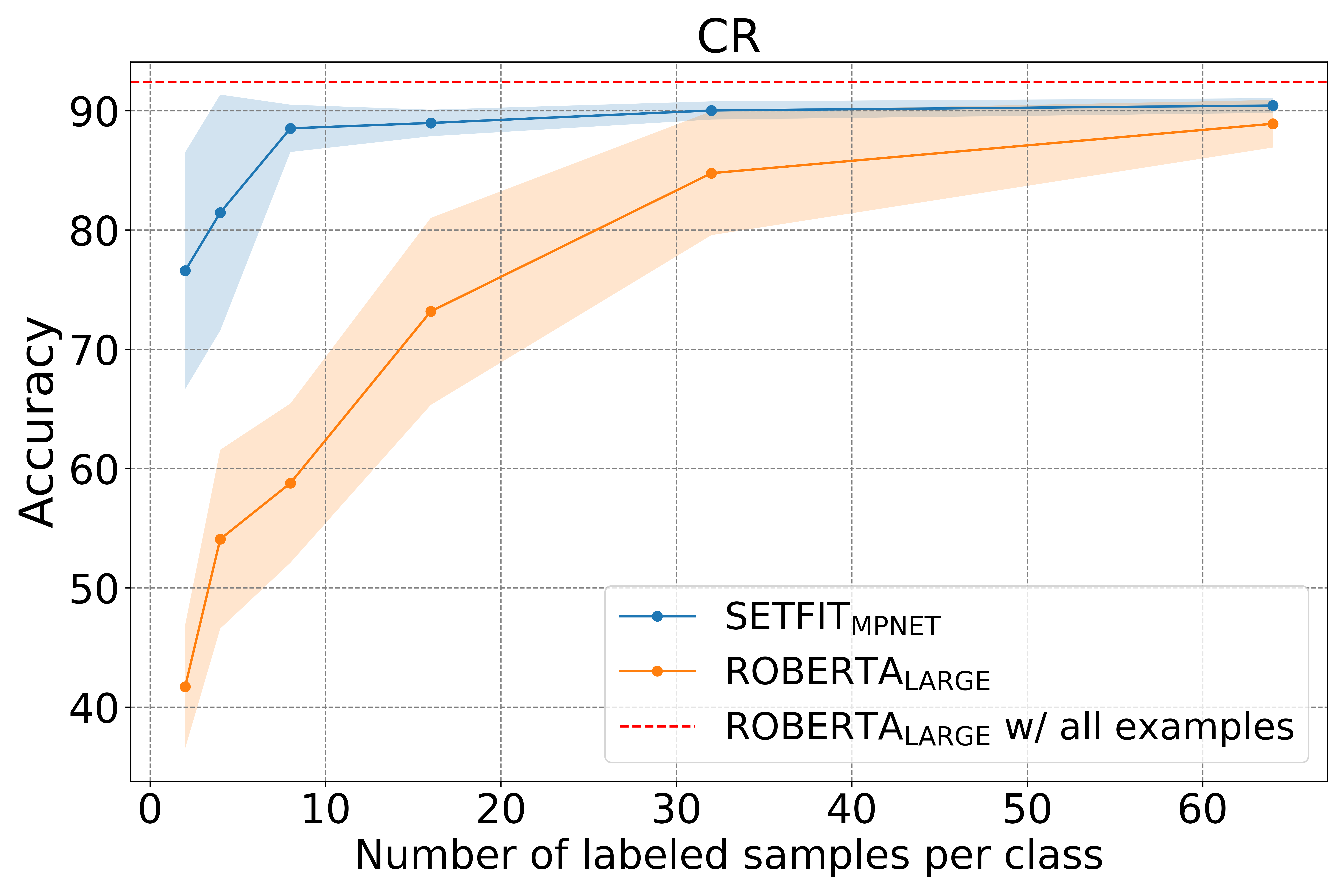
少量标记的学习(Few-shot learning)是一种在较少标注数据集中进行模型训练的一种学习方法。为了解决大量标注数据难以获取的情况,利用预训练模型,在少量标记的数据中进行微调是一种新的帮助我们进行模型训练的方法。而就在昨天,Hugging Face发布了一个新的语句transformers(Sentence Transformers)框架,可以针对少量标记数据进行模型微调以获取很好的效果。