
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



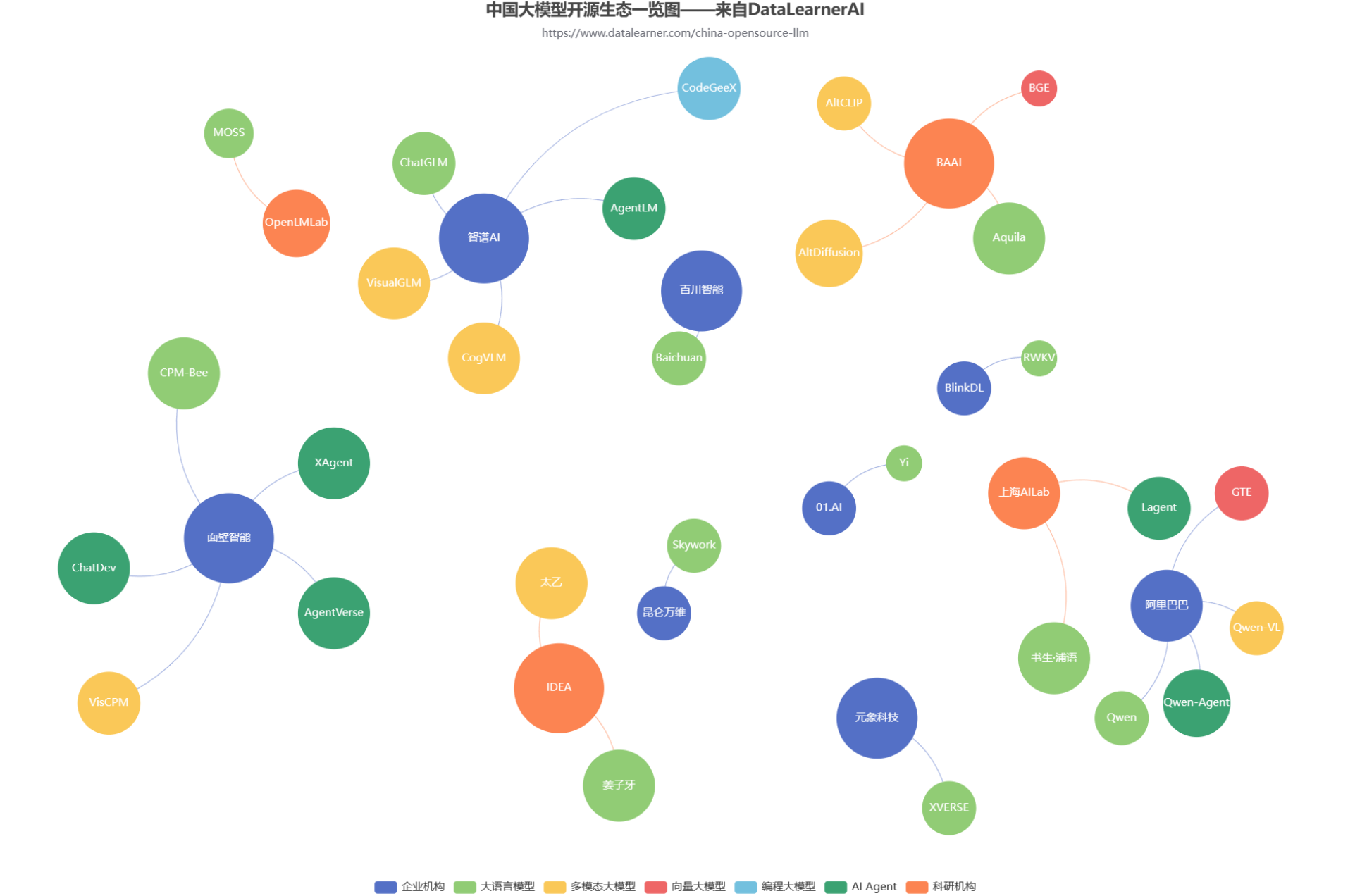
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
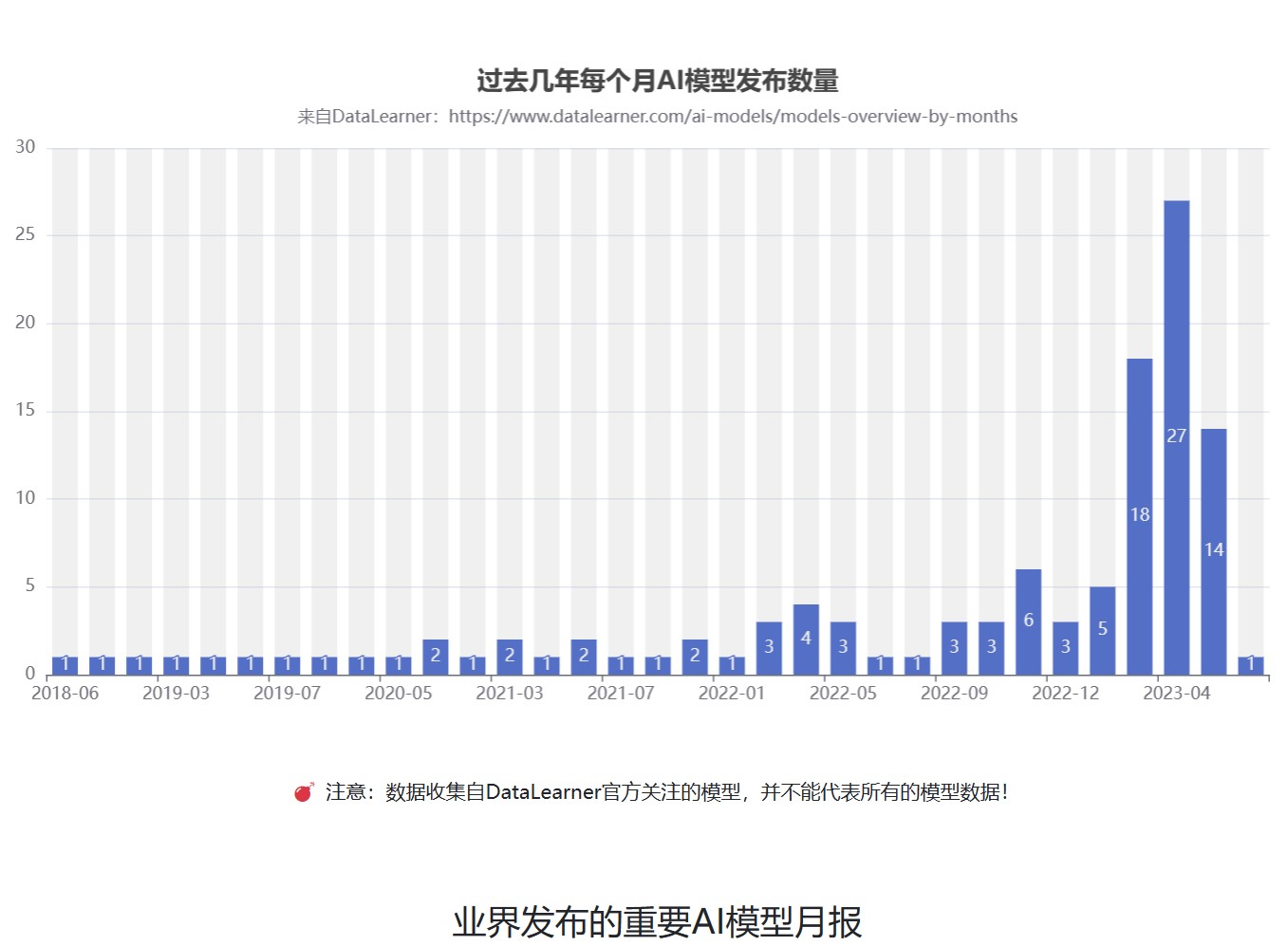
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。