
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



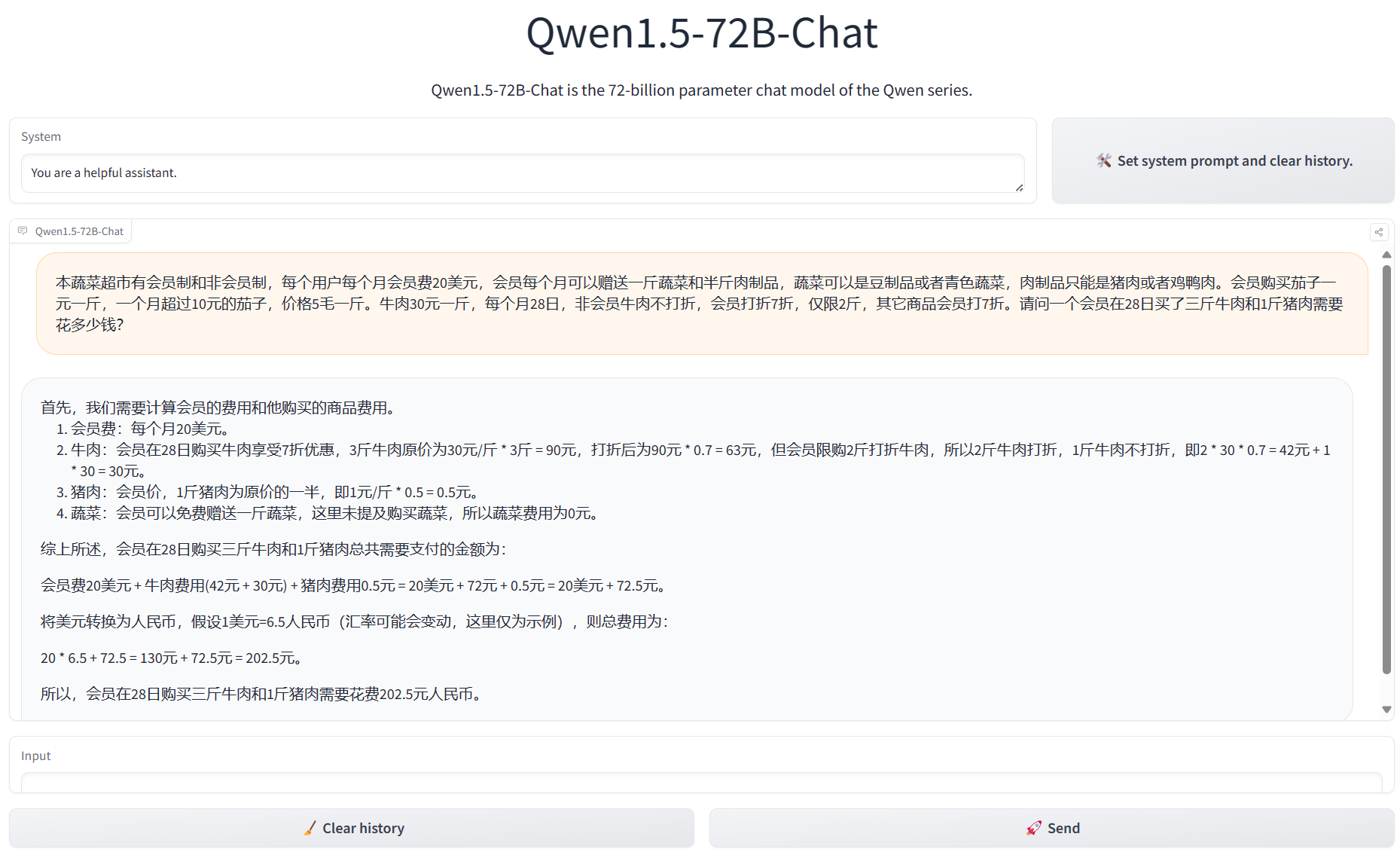
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
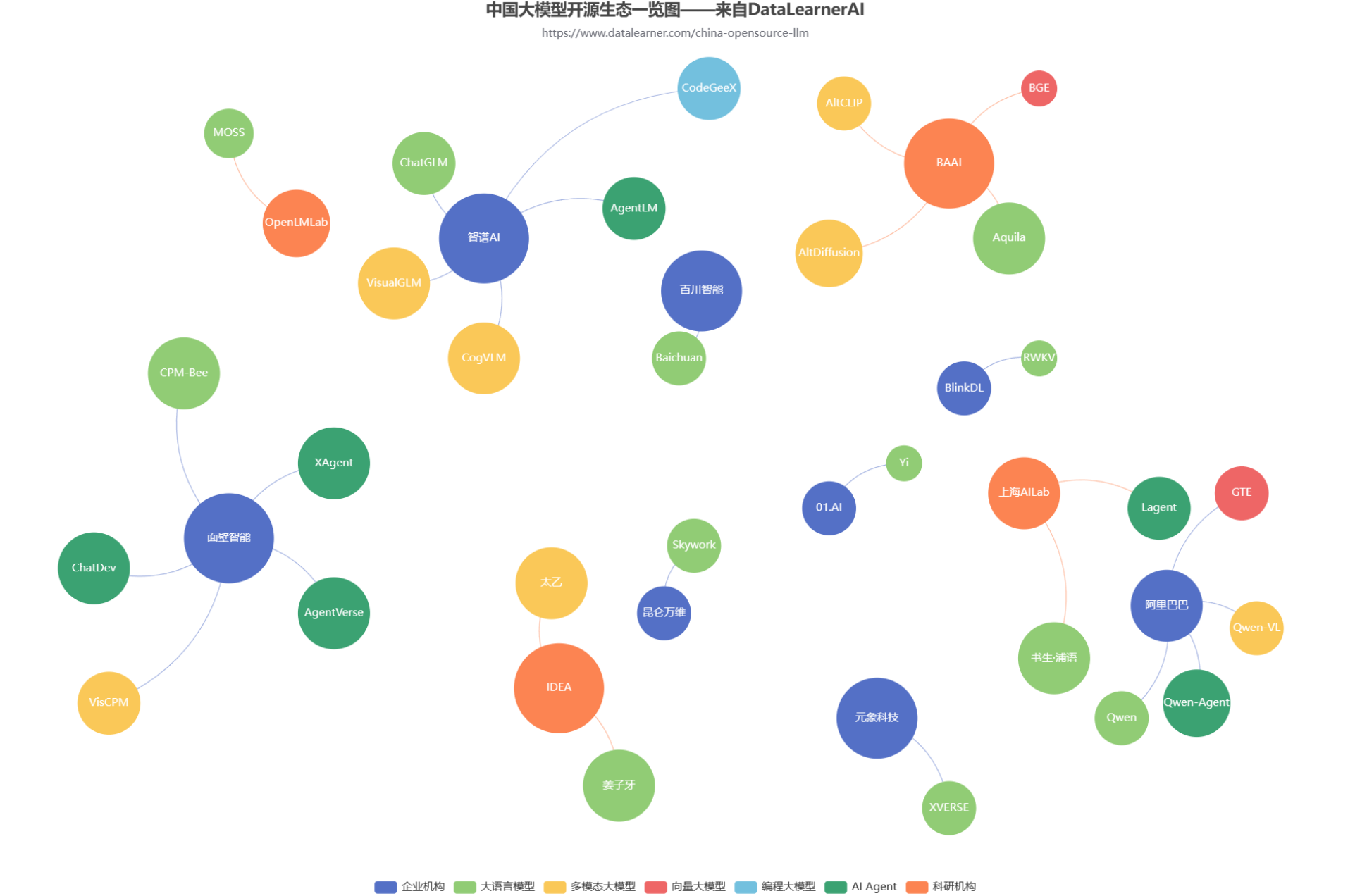
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。
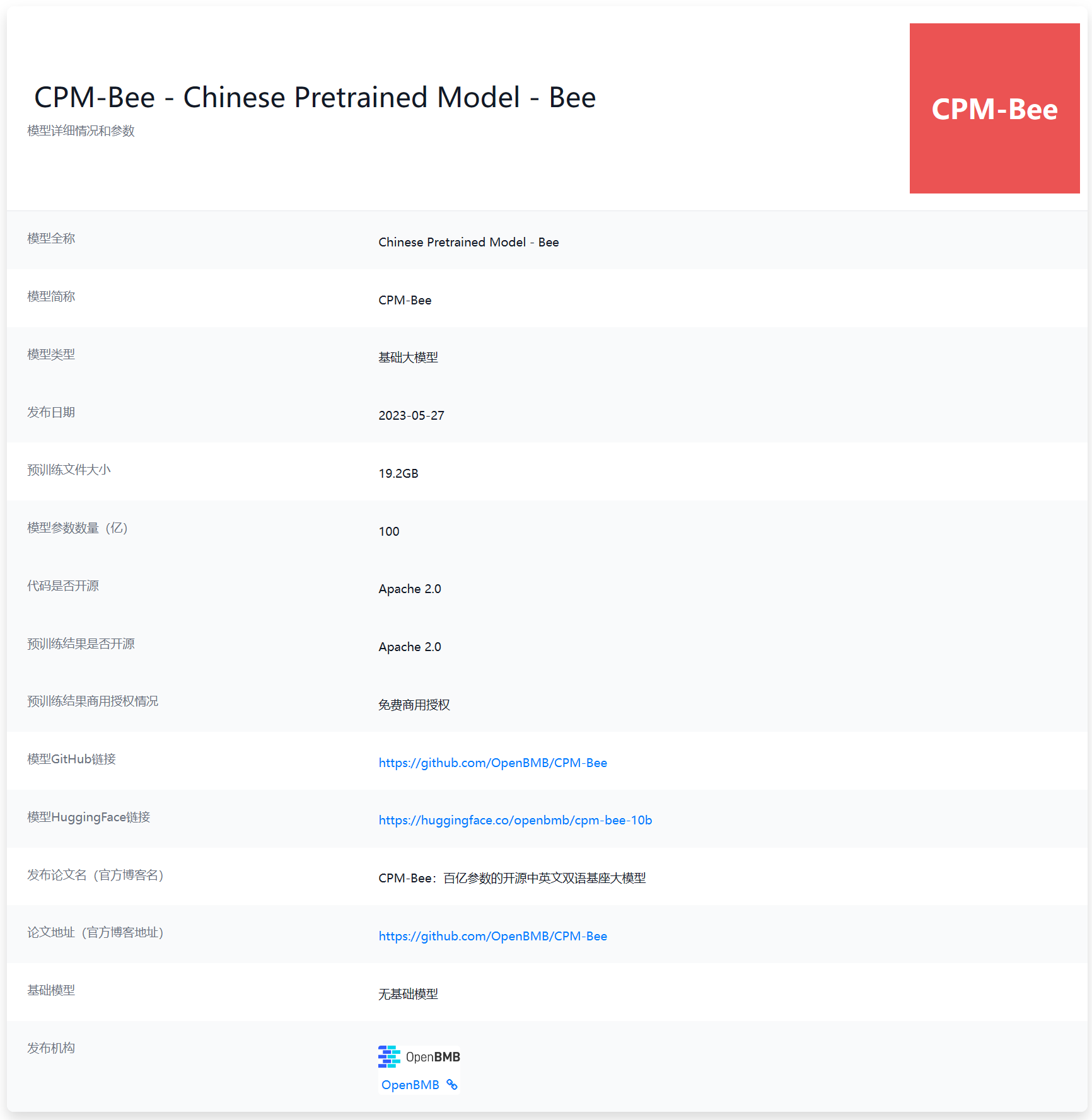
最近几个月,国产大语言模型进步十分迅速。不过,大多数企业发布的大模型均为商业产品,少数开源的LLM则有较高的商业授权费用或者商用限制。对于希望使用LLM能力的中小企业以及个人来说都不是很合适。本次给大家介绍的是目前国产开源领域里面一个十分优秀且具有潜力的大语言模型CPM-Bee 10B。该模型来自清华大学NLP实验室,参数规模100亿,最重要的是对个人和企业用户均提供免费商用授权,十分友好!

BAAI全称北京智源人工智能研究院(Beijing Academy of Artificial Intelligence),是国内非常重要的一个人工智能研究机构。此前发布了悟道系列数据集和大模型。在最近,他们开源了一个全新的国产开源大语言模型Aquila系列模型。该模型基于大量的中英文数据集训练,是一个完全开源可商用国产大语言模型。
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
今日推荐
截止目前为止最大的国产开源大模型发布:元象科技开源XVERSE-65B大模型,16K上下文,免费商用
强化学习进入分布式时代——DeepMind分布式强化学习框架ACME发布
Bloomberg发布的最新的memray——Python内存分析器是什么?
SlimPajama:CerebrasAI开源最新可商用的高质量大语言模型训练数据集,含6270亿个tokens!
OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
Python报Memory Error或者是numpy报ValueError: array is too big; `arr.size * arr.dtype.itemsize` 的解决方法