
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



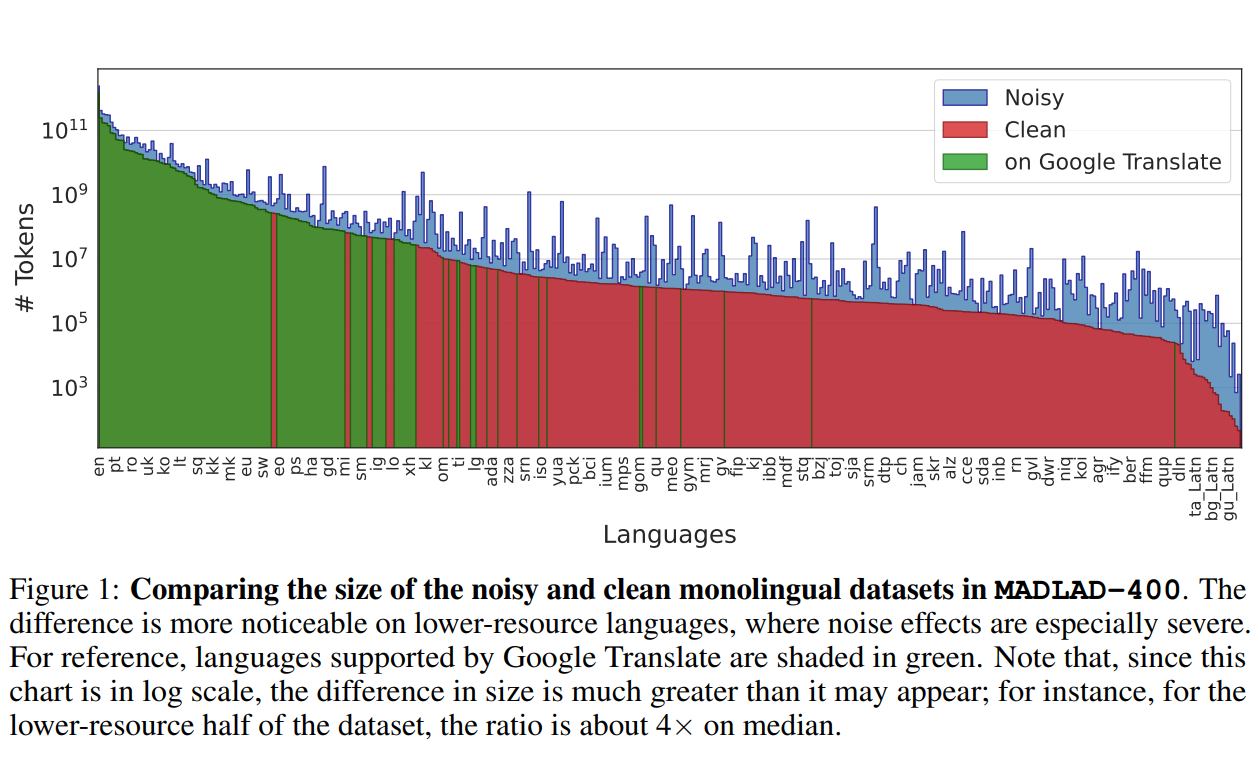
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。
今日推荐
OpenAI最新的文本生成图像大模型DALL·E3发布!生成的图像不忽略每一个细节的文本!
仅需一行代码即可微调大语言模型——LightningAI发布全新Python库Lit-Parrot
截至目前最强的70亿参数大语言模型:开源可商用的RedPajam 7B完全版发布!
重磅!MLPerf™训练1.1成绩发布!AI训练正在超越摩尔定律!
Keras中predict()方法和predict_classes()方法的区别
OpenAI CEO详解今明两年GPT发展计划:10万美元部署私有ChatGPT、最高支持100万tokens、建立微调模型应用市场
华盛顿大学提出QLoRA及开源预训练模型Guanaco:将650亿参数规模的大模型微调的显存需求从780G降低到48G!单张显卡可用!