
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



DeepSeekAI最近发布的几个模型,如DeepSeek V3、DeepSeek R1等引起了全球的广泛关注和讨论,特别是低成本训练出高质量模型之后,引起了很多的争论。引起了大家对OpenAI、英伟达等公司未来的质疑。然而,对于DeepSeekAI的模型为什么引起了如此广泛的关注,以及大家讨论的核心内容是什么,很多人并不是很清楚。本文基于著名的独立科技行业分析师Ben Thompson的总结,配合DataLearnerAI的分析,为大家总结DeepSeek引起的全球讨论。
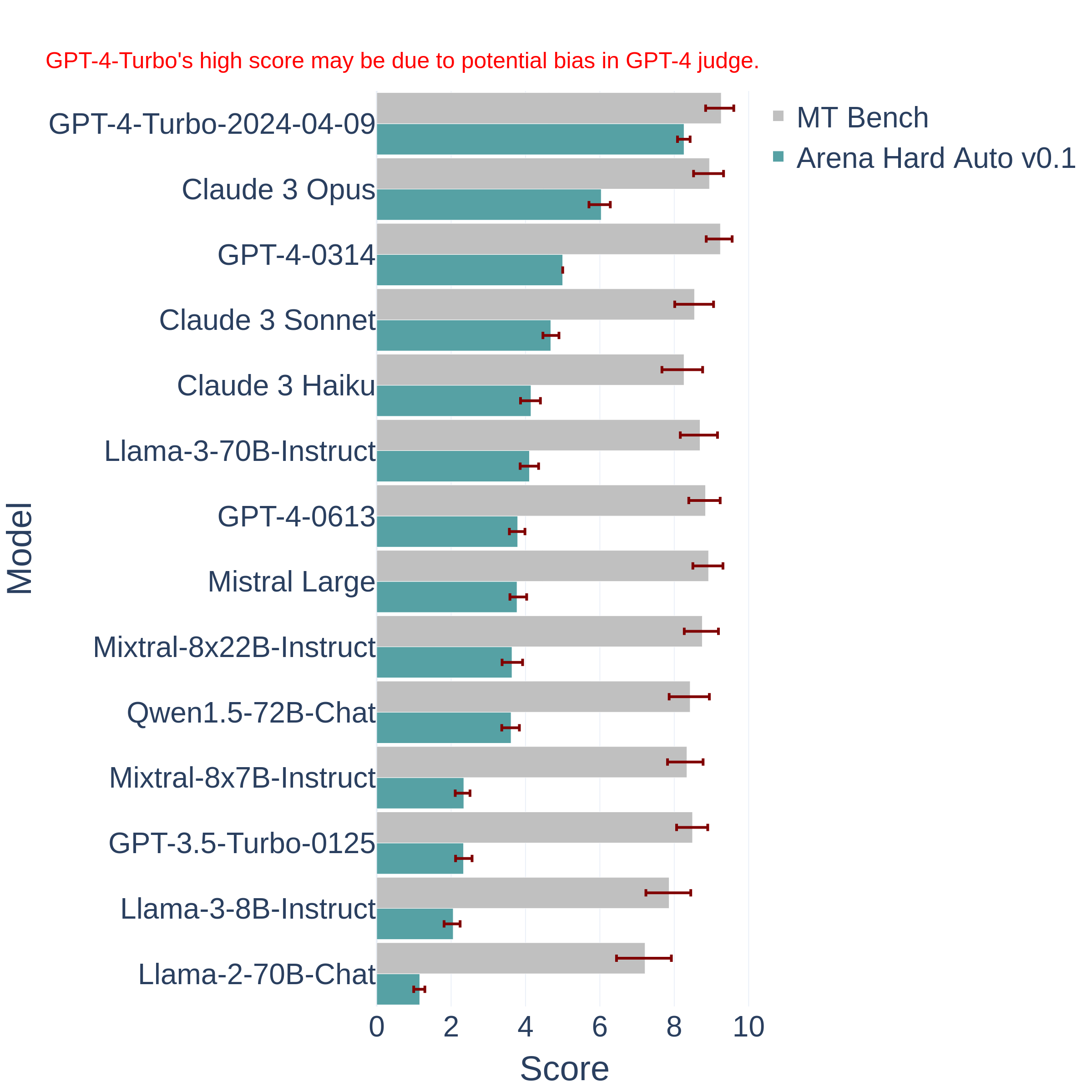
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。
在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 **提示缓存(Prompt Caching)** 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!

随着OpenAI发布推理大模型o1,专注于推理能力的大模型开始被广泛关注。基于思维链探索的推理大模型也不断涌现。此前,DeepSeekAI与上海人工智能实验室都发布过推理大模型,也展现了很不错的推理能力,虽然DeepSeekAI官方承诺该模型会开源,但是目前还没有发布。今天,阿里开源了一个全新的推理大模型QwQ-32B-Preview,其推理能力在评测结果上超过o1-mini,是目前开源领域最强的推理大模型(也可能是目前唯一)。

最初,大模型的应用主要通过像ChatGPT这样的聊天机器人展现其智能理解能力。随着技术的进步,基于大模型的智能代理(AI Agent)成为突破大模型能力边界的重要方向。这些智能代理能够执行一系列任务、解决问题,并进行决策,具备深刻理解用户需求和自主规划解决方案的能力,并能够根据规划结果,选择和使用各种工具来完成任务。然而,AI Agent系统面临的关键挑战是如何高效地将外部工具、知识、资源等迅速接入大模型,并实现有效利用。尤其是,如何将现有的工具和资源整合进大模型,提升其生产力能力,是一个亟待解决的问题。

OpenAI的o1模型是当前最强大的具有超强推理能力的大语言模型。但是,o1模型本身的能力如何,o1版本和o1-mini版本模型的差异在哪等似乎都很不清晰。为此,OpenAI在Twitter上举办了一次AMA(Ask me anything)活动,解答了很多大家关心的问题。在这篇博客中,我们根据这个讨论结果总结了一下其中比较重要的信息供大家参考。

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!
大语言模型是通过收集少量专门数据对模型的部分权重进行更新后得到一个比通用模型更加专业的模型。但是,当前大家讨论较多的都是语言模型的微调,对于嵌入模型(或者向量大模型)的微调讨论较少。Modal团队的工作人员发布了一个博客,详细介绍了向量大模型的微调工作,本文将其翻译之后提供给大家(原文:https://modal.com/blog/fine-tuning-embeddings )。

尽管各家大模型技术进展神速,但是在复杂任务的推理上,大模型目前依然较弱。在去年底,各方消息透露,OpenAI内部有一个称为Q\*的项目取得了重大的突破,可以大幅提高大模型的推理能力。但是,几个月过去了,这个当时吸引了大量讨论的项目没有任何信息。直到昨天,Reuters披露了Q\*项目的进展,这个项目已经变为Strawberry!并且距离发布时间更近了!

OpenAI在GPT-4发布一年之后再次更新其基础模型,发布最新的GPT-4o模型,其中o代表的是omni,即“全能”的意思。GPT-4o相比较此前最大的升级是对多模态的支持以及性能的提升。GPT-4o在各方面比GPT-4更强,但是速度更快,开发者接口的价格则只有一半!
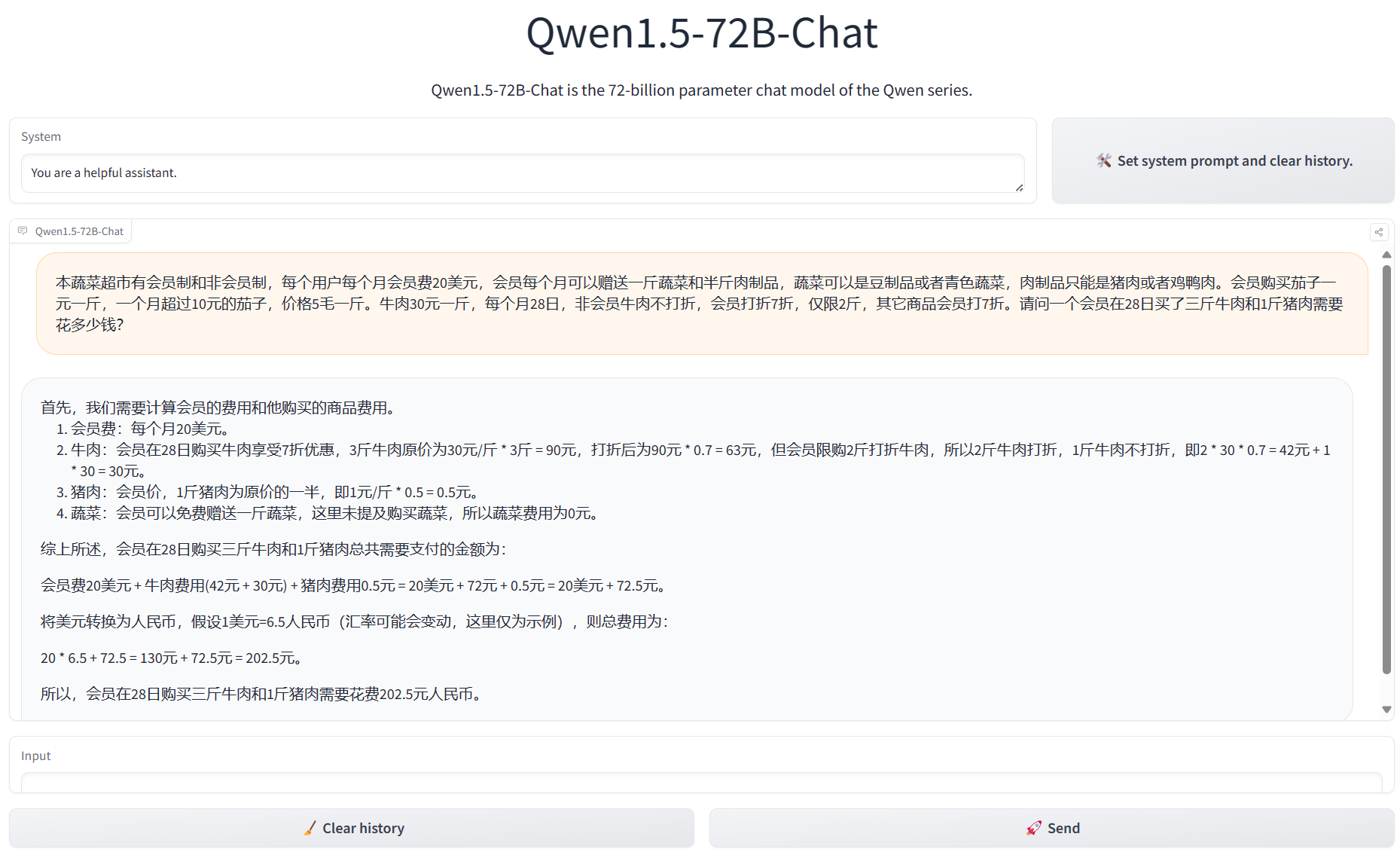
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!

Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。
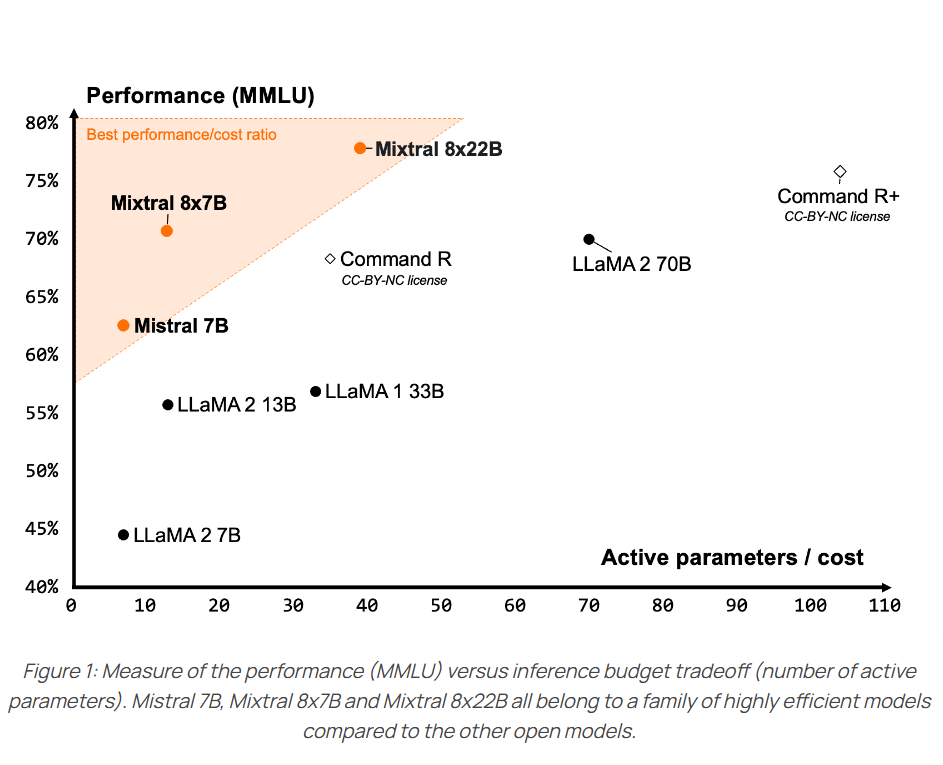
今天,MistralAI官方正式官宣了这个模型,并在HuggingFace上上架了两个不同的版本,一个是预训练基础模型Mixtral 8x22B,另一个则是指令优化的版本Mixtral-8x22B-Instruct。同时官网发布了博客介绍这个全新的大模型,并披露了更加详细的结果。
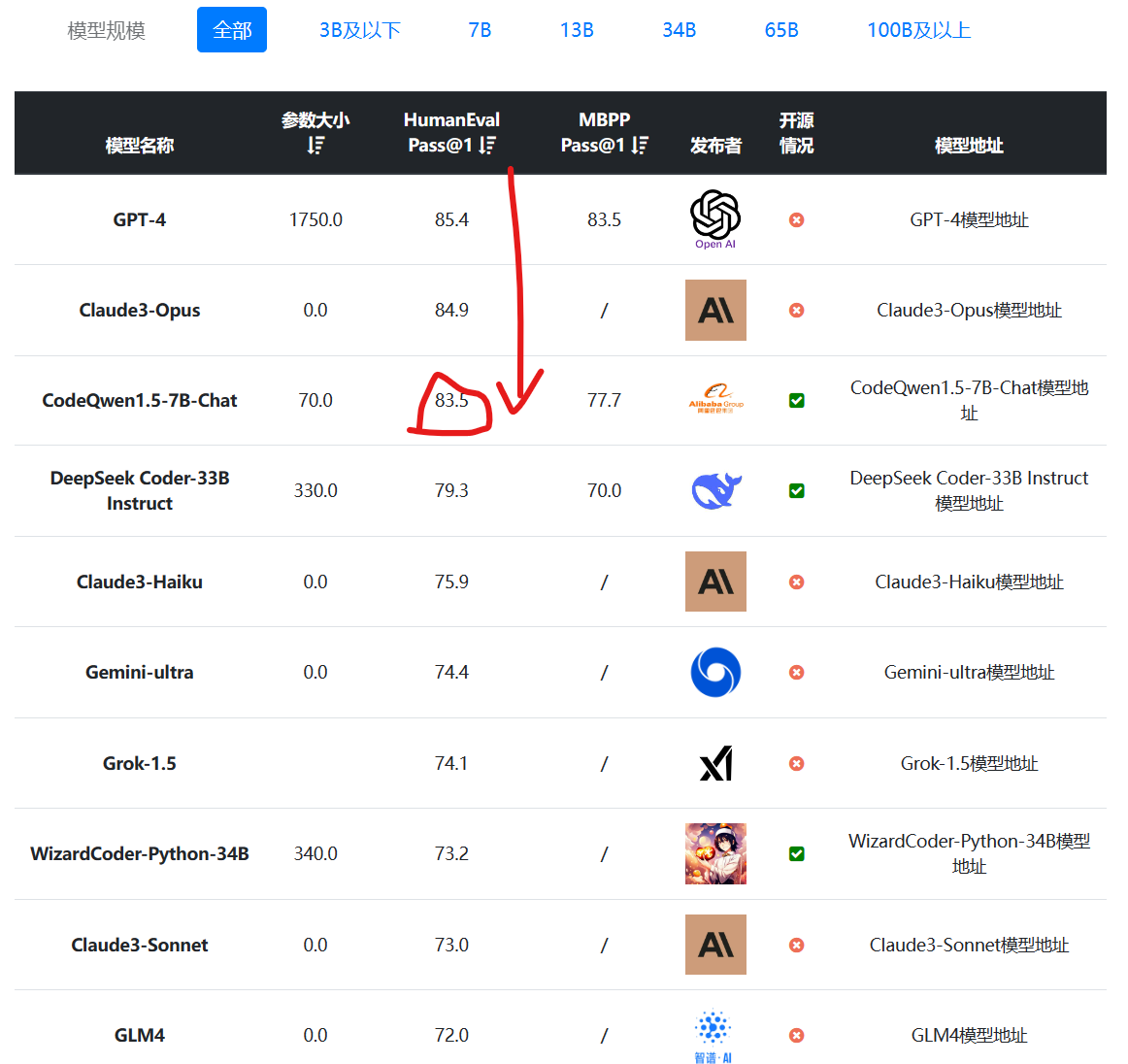
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!